| Version | 1 |
| Authors | Mark Davis (mark.davis@us.ibm.com) |
| Date | 2001-04-11 |
| This Version | n/a |
| Previous Version | n/a |
| Latest Version | n/a |
| Tracking Number | 1 |
This document describes guidelines for testing programs and systems to see if they support Unicode, and the level of support that they offer.
This document is a proposed draft Unicode Technical Report. Publication does not imply endorsement by the Unicode Consortium. This is a draft document which may be updated, replaced, or superseded by other documents at any time. This is not a stable document; it is inappropriate to cite this document as other than a work in progress.
A list of current Unicode Technical Reports is found on [Reports]. For more information about versions of the Unicode Standard and how to reference this document, see [Versions].
This document describes guidelines for testing programs and systems to see if they support Unicode, and if so, to determine the level of support that they offer. These guidelines explicitly do not test for general internationalization or localization capabilities; those are out of scope for this document.
[TBD: add reasons for testing: e.g. companies wish to assemble systems that handle Unicode correctly.]
Unicode is a very fundamental technology and will appear in many different products: from operating systems to databases, from digital cameras to online games. Thus any tests for Unicode capabilities must be tailored to the specific type of product. Moreover, many of the requirements for Unicode compliance are only applicable to particular products. BIDI conformance, for example, may not be applicable if the product never displays text, but only processes it. Thus all of the following guidelines can only be applied to products that support or require the relevant kinds of processing.
In some cases below, tests are provided for features that are not required for conformance to the Unicode Standard, but are in practice part of what would be expected of a Unicode-capable program or system.
The most fundamental requirements for Unicode conformance are the following:
Compliance tests for the first of these are fairly straightforward, with programs that store and retrieve data, such as databases. Here is one example:
Build a small table, insert Unicode data, select the data from the table and compare the results. For instance, use the following SQL statements to create a table named "langs", insert data, select all data and search for one record:
| SQL Statements | Results |
|---|---|
drop table langs; |
The SQL command completed successfully. |
create table langs (L1 character(10), L2
varchar(18)); |
The SQL command completed successfully. |
insert into langs values ('Russian', 'русский'); |
The SQL command completed successfully. |
insert into langs values ('Spanish', 'Español'); |
The SQL command completed successfully. |
insert into langs values ('Czech', 'čeština'); |
The SQL command completed successfully. |
insert into langs values ('Greek', 'ελληνικά'); |
The SQL command completed successfully. |
insert into langs values ('Japanese', '日本語'); |
The SQL command completed successfully. |
insert into langs values ('Vietnamese', 'Tiểng
Việt'); |
The SQL command completed successfully. |
select * from langs; |
L1
L2русский
|
select * from langs where L2 like '%λη%'; |
L1
L2ελληνικά |
This section is optional, since not every product does--or needs to do--conversion. However, if a product does do conversion, here are the areas to test for:
For ISO/IEC 8859 tests, download the files in http://www.unicode.org/Public/MAPPINGS/ISO8859/. The files are of the following format, with two significant fields: the first is a byte, and the second is a code point.
| 0x00 0x0000 # NULL ... 0xFF 0x00FF # LATIN SMALL LETTER Y WITH DIAERESIS |
For compression tests and UTF tests (and if CESU-8 is supported), for each converter:
| Bytes | Encoding | Code Points |
| EF BB BF E1 88 B4 | UTF-8 | 1234 |
| EF BB BF E1 88 B4 | UTF-16/LE/BE | EFBB BFE1 88B4 |
| EF BB BF E1 88 B4 | UTF-32/LE/BE | error |
| FE FF 12 34 | UTF-16 | 1234 |
| FE FF 12 34 | UTF-16BE | FEFF 1234 |
| FE FF 12 34 | UTF-16LE/UTF-32* | error |
| FF FE 34 12 | UTF-16 | 1234 |
| FF FE 34 12 | UTF-16LE | FEFF 1234 |
| FF FE FF FE 34 12 | UTF-16 | FEFF 1234 |
| FE FF FE FF 12 34 | UTF-16 | FEFF 1234 |
Proposal: For major encodings (charset in the sense of IANA) we provide a file with:
A sample is at sjistest.zip. The mappings are filtered so that they are neutral regarding variation between different encodings with the same name. For example, this sample excludes Private-Use (aka User-Defined codes), "special" characters not defined in the references, and mappings that are known to be ambiguous such as for U+005C
A test would read such a file and verify that the roundtrip-mappings work as specified. Legal (but unassigned) sequences are converted to some Unicode code point: either the replacement character (U+FFFD), the SUB character (U+001A), or a private use character. Illegal sequences are treated as an error condition.
Protocols should follow these guidelines:
SMTP (with/without MIME) is given as a simple example. For SMTP, there are sending and receiving clients easily available: email applications like Outlook Express and Netscape Messenger.
Sample text for the email body:
Latin: U+00FE ð
Cyrillic: U+0436 ж
Arabic: U+0628 ب
Hindi: U+0905 अ
Hiragana: U+3042 あ
Han Ideograph: U+4E0A 上
Deseret (plane 1): U+1040C 𐐌
Han Ideograph (plane 2): U+20021 𠀡
Verify that the email contents is preserved when stored+forwarded through
this server.
Requires proper configuration of the email client/network.
In this case, as with some other protocols, the server will almost always just
pass the contents through. The test will thus just verify that the server is
8-bit clean, which is almost always the case.
Send the email to an address that is handled by a particular client
program. Make sure that the text is fully preserved and displayed in a
reasonable way (given available fonts etc.).
Example for email clients that are expected to have problems in this area:
Eudora, Netscape 4.x (do not use Unicode internally, so must convert to
subset-charsets).
Some email systems (Lotus Notes, X.500, VM) use other protocols than SMTP
and transform emails between SMTP and their own formats.
Send emails into such systems and forward/reply them back to a
globalization-capable client and verify full roundtrip of the text.
Example for gateways/systems that are expected to have problems: VM (EBCDIC
encodings are subsets of Unicode)
Note: Lotus Notes is globalization-capable (should pass the test) because LMBCS can encapsulate Unicode; it will not fully roundtrip arbitrary MIME/HTML formatting, but this is out of scope for G11N certification. All of the characters should roundtrip.
A non-SMTP email client would have to get the test email through such a gateway. It is possible that the client may show an email with higher or lower fidelity compared with the roundtrip test into and out of the gateway. Higher if only the second part of the roundtrip were to lose information. Lower if the roundtrip can preserve some or all of the original contents in a form that is not displayed in the non-SMTP client.
With many IETF (Internet) protocols it is possible to test at least some of
the protocol elements using a telnet client or a special-purpose client (e.g.,
Java application reading/writing to sockets) by reading and writing plain text
streams directly, and using UTF-8 text for the contents.
Generally, it may be necessary to write custom test clients/servers to perform
meaningful tests of a protocol at all or to automate such tests.
Some protocols (like HTTP) allow many more charsets in direct use than SMTP.
"Direct use" means that UTF-16 is possible in SMTP emails only after
a base64-transformation (or quoted-printable), while HTTP allows the contents
to be encoded in UTF-16 directly in the byte stream.
SOAP is an XML vocabulary being defined by W3C. A SOAP message consists of SOAP envelope, SOAP header and SOAP body. The SOAP body contains user data which is used for RPC function.
<SOAP-ENV:Envelope> <SOAP-ENV:Header> Additional Information for SOAP message transmission </SOAP-ENV:Header> <SOAP-ENV:Body> Body data of SOAP-RPC message transmission </SOAP-ENV:Body> </SOAP-ENV:Envelope>
SOAP request between service requester and UDDI service provider
POST /uddisoap/publishapi HTTP/1.1
Host: abc.def.com
Content-Type: text/xml; charset=utf-8
Content-Length: nnn
SOAPAction: ""
<?xml version="1.0" encoding="UTF-8" ?>
<SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/">
<SOAP-ENV:Body>
<save_business generic="2.0" xmlns="urn:uddi-org:api_v2">
<authInfo>uddiUser</authInfo>
<businessEntity businessKey="">
<name xml:lang="ru">русский</name>
<name xml:lang="cs">čeština</name>
<name xml:lang="el">ελληνικά</name>
<name xml:lang="ja">日本語</name>
<name xml:lang="vi">Tiểng Việt</name>
</businessEntity>
</save_business>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
The expected SOAP message from UDDI service provider for Example 1 above.
HTTP/1.1 200 OK
Server: ABC
Content-Type: text/xml; charset="utf-8"
Content-Length: nnnn
Connection: close
<?xml version="1.0" encoding="UTF-8" ?>
<SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/">
<SOAP-ENV:Body>
<businessDetail generic="2.0" xmlns="urn:uddi-org:api_v2" operator="operator">
<businessEntity businessKey="14821BDD-00EA-4398-8003-24BC35F0394A" operator="operator" authorizedName="uddiUser">
<discoveryURLs>
<discoveryURL useType="businessEntity">http://abc.def.com:9080/uddisoap/get?businessKey=14821BDD-00EA-4398-8003-24BC35F0394A
</discoveryURL>
</discoveryURLs>
<name xml:lang="ru">русский</name>
<name xml:lang="cs">čeština</name>
<name xml:lang="el">ελληνικά</name>
<name xml:lang="ja">日本語</name>
<name xml:lang="vi">Tiểng Việt</name>
</businessEntity>
</businessDetail>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
Java program (SaveBusinessExample.java) using SOAP interface in UDDI4J to generate sample 1.
Programming Language support includes both the basic programming language, and libraries that supplement the basic support with additional functionality. Thus, for example, even though the basic support in C for Unicode is fairly rudimentary, there are supplementary libraries that provide full-featured Unicode support.
Testing for full internationalization support is beyond the scope of this document, but the language (supplemented by libraries) can be tested for the following.
The StringTest.txt file contains machine-readable tests for code point operations.
Analysis includes character properties, regular expressions, and boundaries (grapheme cluster, word, line sentence breaks). In this area, typically the tests will check against the UCD properties, plus the guidelines for how those properties are used. The exact formulation of the test will depend on the API and language involved. The main features to test for are:
For testing Unicode properties, a small test program should be written that for each property:
For regular expressions, UTR #18 provides 3 levels for regular expressions. The feature sets in these levels can be tested for explicitly. Note: the TR does not require any particular syntax, so any tests have to be adapted to the syntax of the regular expression engine.
[TBD: Char/Word/Sentence Breaksplaceholder, once UTR #29 gets further along.]
Comparison includes both binary comparison, and comparison based on UCA (UTS #10). In the latter case, it includes string comparison, string search, and sortkey generation.
<string1> ; <string2> ; <code point relation> ; <UTF-16 relation>
0061; 0062; LESS; LESS; FFFF; 10FFFF; LESS; GREATER; FFFF; 10FFFF; LESS; GREATER;Collation (UCA UTS #10): Verify that the default collation sequence follows the UCA, using the test files in http://www.unicode.org/Public/BETA/UCA/
String Search: Verify that the locale-sensitive string search functions follow the UCA, according to StringSearchTest.txt.
Transformations include case mapping/folding and normalization,
The main goals of keyboard input and editing tests are to verify that:
The goals of rendering tests are to verify that for the repertoire supported by the product:
Testing rendering behavior is not generally possible programmatically. There is simply too much variation in the possible acceptable behavior. Moreover, if a system is not documented as supporting a given repertoire of characters (such as Hebrew), then tests of that repertoire are not applicable. The following, however, does provide some guidelines in assessing correct behavior for a supported repertoire.
|
Code Point Sequence |
Unacceptable Rendering | Acceptable Rendering | ||
|---|---|---|---|---|
| Preferred | Fallback | |||
U+006C, |
||||
U+006C, |
||||
U+006F, |
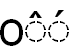 |
|||
[TBD: Add Thai example]
[TBD: list code points, with break opportunities marked by a vertical bar. Example:
0061 0020 | 0061 # break after spaces]
[TBD: Give acceptable and unacceptable Arabic and Hebrew examples]
[TBD: Give examples of unabashedly wide or narrow. Probably to difficult to test the ambiguous cases.]
[TBD: Give acceptable and unacceptable examples of Devanagari, Arabic, Tamil]
| [FAQ] | Unicode Frequently Asked Questions http://www.unicode.org/unicode/faq/ For answers to common questions on technical issues. |
| [Glossary] | Unicode Glossary http://www.unicode.org/glossary/ For explanations of terminology used in this and other documents. |
| [Reports] | Unicode Technical Reports http://www.unicode.org/unicode/reports/ For information on the status and development process for technical reports, and for a list of technical reports. |
| [U3.1] | Unicode Standard Annex #27: Unicode 3.1 http://www.unicode.org/unicode/reports/tr27/ |
| [Versions] | Versions of the Unicode Standard http://www.unicode.org/unicode/standard/versions/ For details on the precise contents of each version of the Unicode Standard, and how to cite them. |
Thanks to Helena Shih Chapman, Julius Griffith, Kentaroh Noji, Markus Scherer, Baldev Soor, and Israel Gidali for sample tests and feedback.
The following summarizes modifications from the previous version of this document.
| 6 | Initial Version |
Copyright © 2002 Unicode, Inc. All Rights Reserved. The Unicode Consortium makes no expressed or implied warranty of any kind, and assumes no liability for errors or omissions. No liability is assumed for incidental and consequential damages in connection with or arising out of the use of the information or programs contained or accompanying this technical report.
Unicode and the Unicode logo are trademarks of Unicode, Inc., and are registered in some jurisdictions.