L2/04-328
Source: Antoine Leca
Date: August 4, 2004
Subject: Response to Public Review Issue #37
[ This document is available for browsing at URL:http://antoine.leca.free.fr/devanagari/PR37.html ]
The question was:
“Should the UTC adopt a model in which ZWJ precedes Virama, as proposed in section 7 of the review document?”
My answer would be a balanced yes. However, this answer does not endorse fully the proposed document. I really believe the whole area should be revised. In such a revision, I believe a good guideline would be to have this new model of use of ZWJ. But there are a lot more of things that needs revision, too.
A. Background
Since the publication of the review period three weeks ago, I have spent many hours studying the various aspects touched by this proposal, along with the aspects that are not said to be affected, but most likely would. I have particularly studied how it could be implemented, and how efficient it would result: I must make clear that I have a good grasp of rendering technologies, particularly of Indic scripts; I have revised one of the available layout engines (from Eric Mader, used in ICU and Pango); I have a good knowledge of another two, the OpenType/Uniscribe technology from Microsoft, and ISFA/ISFOC/GIST from CDAC in India (using ISCII); I have a prototypical engine myself, but it is still unpublished. I also consulted the various TeΧ implementations for Indic scripts.
Since Indic scripts in Unicode is an area I know for a long time, I also studied the evolution of the various mechanisms of encoding over the time, something that is of uttermost importance when it comes at inventing another mechanism.
I had also a look at the other scripts beyond the nine scripts of India, because a new model is in my eyes likely to have an impact on the other virama-based scripts, present and future.
This study has brought me to ask some questions on the public lists; others also have. The feedback, more exacty the lack thereof, suggests me that the previous studies on this respect were not as deep as I had thought at the beginning. In fact, Peter Constable himself makes clear that he has a role of synthesizing various sources, and does not pretend to be authoritative. I appreciate the pragmatism of the task, particularly since I shall not be able to do this. However, I feel it is my duty to point out the various problems I have encountered.
B. Reading of the document to be reviewed
1. Introduction
I have a number of problems with this part. Here they are, in no particular order.
a) First, the presentation introduces the present (4.0) version of The Unicode Standard, as if it would be a definitive document. When we look at it from a historical perspective, there are interesting things to add.
The Unicode Standard, version 1.0, volume 1
(ISBN 0-201-56788-1, October 1991) contained a 7-page chapter on Devanagari (53
to 59), which described in detail the principles of encodings: the virama-model,
and also (with great details) the relationship with the ISCII encoding (1988
draft). While the
explicit halanta (overt virama) form was then defined as
virama+ZWNJ, there was nothing about ZWJ then (worse, INV was identified with
ZWNJ!) The description of the Devanagari script proper (in as much it is
different from the others) was reduced to a minimum. Similarly, the descriptions
of the eight other scripts were, well, very short...
Then, volume 2 (ISBN
0-201-60845-6, June 1992) contained, in an obscure appendix A named
“Character Shaping Behavior”, along with a description of the shaping
of the Arabic script, a description of the rendering principles of both
Devanagari (pp. 399 to 409) and Tamil (410 to 414). That is, the appendix is 50%
larger than the ‘main text’. And, of course, it is the bulk of these
descriptions that we then encountered in the next versions of The Unicode
Standard.
However, there is very important difference. On page 387, at
the beginning of say appendix, there is the following text:
For brevity, the Indic scripts are represented in some details with Devanagari and Tamil, since they illustrate the range of types of behavior found in the other Indic scripts. The behavior of the other scripts can be derived from a close examination of these examples.In other words, how to understand the whole picture for the other scripts was then left as an exercise for the reader... Also, in the 8 month period between both volumes, the Unicode standard did evolve quite a
bit with regard to the Indic scripts in general, and Devanagari in particular (remember that ISCII standard was published in the middle of this period). It is in this appendix that we shall discover (on page 403) the use of ZWJ to select the half form (remember we are in the context of Devanagari only). There were no such things as exceptions (like eyelash-repha, which came into existence a few months later), much less needs for the representation of features not present in Devanagari.Now, the very text that is quoted in the document (“The principles [...]”), is an extract that was present in the ‘main’ part, in volume 1; and as such did not apply in first instance to the description of Devanagari in voume 2. However, when both texts were merged for version 2, the quoted sentence was inadvertantly extended in meaning, and as a result the description of (minimum) rendering for Devanagari, with all the bells and whistles like half-forms, was cast in stone to be the ultimate tayloring for all the Indic scripts...
b) The introduction, and the main part as well, only deals with ZWJ. However, in this context, it would have been fruitful to also deal with ZWNJ, particularly since it appears much less polemic.
c) This leads us to notice that there is no reference to section 15.2 (Layout Controls) of The Unicode Standard, particularly pages 389 to 391 (in version 4) that specify the general behaviour of ZWNJ and ZWJ. It is true that it is expressedly specified that ZWJ has a specific behaviour in the Indic scripts, but the very way it is written is interesting (more on this later).
d) About ‘Indic scripts’, since the model is about the use of ZWJ with relation to virama and conjuncts, I believe any study at the respect should at least skim all the scripts that use a virama-based model, with conjuncts; beyond the studied nine scripts of India (minus Tamil, which in its present-days form has only
one conjunct and a few more ligatures involving vowels, so does not have any need for the discussion at hand, and can be discarded), we ought to consider Sinhala, Myanmar, Khmer, Kharosthi, and Brahmi. Brahmi is particularly interesting, since it is the basis for all the others scripts, and its method to form conjuncts is used with many of the descendants (an obvious exception being the famous half-forms of Devanagari...) Also relevant here is document N2827 of SC2/WG2 (the 10646 subcommittee), titled “Proposal of 4 Myanmar Semivowels”, which proposes yet another hack to solve the same problem of encoding the difference between a very modified conjoining form (here, the 4 semivowels of Myanmar) and the ‘natural’ subjoined forms that are sometimes used: basically the same problem as we are dealing with.
2.1 Background: Dead consonants and conjoining forms in Devanagari.
Here, I disagree with the author when he says: “Indic conjoining forms are very often explained in terms of the conjoing forms of Devanagari.” As himself shows later, Devanagari way to form conjuncts is the exception rather than the rule when one consider several Indic scripts. Things are very different when one only have to explain Devanagari, and this is the fundamental reason why The Unicode Standard is set up like it is now: remember that at the beginning, this text intended to describe Devanagari only. The authors that try to describe conjuncts, usually begin with Brahmi, since it is historically the antecedent. Conjuncts in Brahmi were usualy done by writing, using forms reduced in size, the various parts in a stacked way, from top left to bottom right. Thereafter, scribes will transform the most used and most difficult to write into undecipherable ligatures, as always.
2.2 Background: Function of ZWJ in Devanagari
“For most Indic scripts, there have been variations in typographic conventions [...] ” This is incorrect: we are not dealing with typographic variations (such as the glyph used for श), but rather orthographic variations. This is much like the opposition in French between oe, as in « coexister », and œ as in « cœur »: one cannot use one when the other is expected, unless there is real technical limitations to do so.
“Unicode does not in general require conforming implementations to display consonant clusters in their conjoined forms.” The expression ‘conjoined form’ is not previously defined; one might deduce that it really means ‘ligatured from’, but this is not clear.
In fact (and the document does explain this in details later), Unicode does constrain the implementation to render consonant clusters for the scripts of India using the ‘most ligated form’, unless instructed otherwise. And this is where the description of the ‘normal’ behaviour of ZWJ, as specified in chapter 15.2, is changed. If we keep the three categories of this latter (unconnected, cursively connected and ligated), the normal behaviour of ZWJ is to request an higher category (and conversely, ZWNJ requests a lower one). One should note here that this model has been applied to Sinhala (according to draft standard SLS 1134, 2nd ed.) and Khmer. This is as expected, since the normal use for these scripts nowadays is to not use (undecipherable) ligatures. However, to keep in line with ISCII-91 ‘soft halants’, Unicode chose to alter this mechanism for the scripts of India. So the default behaviour is now to have ligature if possible. And the effect of ZWJ in Devanagari (as it is described) is what is to be encoded <X, ZWJ, ZWNJ, Y> in chapter 15. Of course, the added presence of the virama character in the middle of the sequence is the additional reason to avoid such overlong sequences (that are nevertheless contemplated in Sinhala.)
“Unicode 4.0 is not explicit regarding the effect of ZWJ when used following consonants [that do not have half forms], though it seems clear what the effect should be [...] ” I am not sure this is that clear. For an example, have a look at the TeΧ Sanskrit font and preprocessor done by Charles Wikner: on page 10 of the manual, one can encounter various options settings to request alternate renderings; of particular interest are options 125 to 131 (ट्म ठ्म ठ्य ड्म ड्य ढ्म ढ्य) and also 137 to 143; while the basic form is a ligature where the म or the य ligates, the alternate option is to be rendered with modified म or य , with open counters; these latter forms could be qualified as half-forms (see below), although this is not what is usual when one deals with Devanagari conjuncts. Still, I believe these latter forms do fully qualifiy as “to prevent a dead consonant from assuming full conjunct formation yet still not appear with an explicit virama,” and as such I should expect an implementation based on such a font to used ZWJ to select the optional form (in fact, looking at the full table of Mr. Wikner’s work, I believe all of options 101 to 170 could be implemented using ZWJ, except 147 which selects an alternative form of न्न, where the two hooks are one above the other, instead of the usual form where they have different angles and join at one only point.)
I should now emphatise the last phrase of this section. The author writes: “The effect of the ZWJ is to control how a dead consonant and a consonant following it will be presented.” I am very much in agreement with this sentence. However, it seems that the author does not agree that much, since the rest of the document (and particularly section 4.1 which refers directly to this text) seems to think that the effect of the ZWJ would rather be to “transform” the dead consonant into a half-form, irregardless of the following one...
3. Differences in conjoining strategies
First, one point that should be made here is that for the script where conjuncts are formed only or almost only with subjoined or post-base form (such as Kannada, Oriya, Telugu, and to a lesser extend Gurmukhi), the term ‘half-form’ usually designate those subjoined or post-base forms! And of course there is no assimilation between dead (also known as pure) consonants and half-forms, something that ought to be made clear for Devanagari also, as we saw.
I shall not comment a lot about table 6; suffice to say that we are all aware this is not a definitive and authoritative item.
About the specificity of ‘vattu’, I am not completely convinced: first, I believe a similar feature also exist in Kannada (but it applies to the subjoined forms, obviously), as in (?) ಸ್ತ್ರ್ವ ; furthermore, I feel the same behaviour exists for রবৰৱର and ବ. Then, there is the case of റ as in അവന്റെ (U+0D05 U+0D35 U+0D28 U+0D4D U+200D U+0D31 U+0D46; the rra is to be rendered in subjoined form below the chillaksaram nu) that I cannot decide due to lack of knowledge. And finally, there is न and व which in Sanskrit usually behave exactly the same way as र , except that there is no distinctive sign as is the rakar (which looks like a circumflex accent, at the bottom of the glyph.)
Something that should be outlined here is the special case of Bengali. Traditionnally (there has been a very detailled explanation at the respect from Mike Meir in the Indic mailing list), Bengali conjuncts are explained as using subjoined forms, for রলবণনম. In that way, Bengali could adhere to the same model as Kannada, Oriya, or Telugu, i.e. C2-conjoining. However, Bengali also has distinctive ‘half-forms’, here reduced in size versions of a number of C1 pure consonants, in a quite systematic way. We will revisit this issue below.
Regarding the other scripts not studied, Myanmar clearly use the C2-conjoining model with an added feature of the kinzi, which functions very much like a repha. Khmer also use the same model. Sinhala, when writing Pali or Sanskrit, use a model similar to Bengali, but there is no reduced versions of the C1 pure consonants.
After reading until now, the impression is that, while the ZWJ mechanism could be applied without too much of a problem to cases somewhat different of the canonical क्ष, there is a clear deficit of explanations and examples at the respect, since the existing material is clearly targeted at a narrow part of the spectrum.
4 Problems related to ZWJ in Indic scripts: 4.1, 4.2, 4.3
I agree that the current mechanism is deficient when it comes to the ‘defective’ cases, when there is only one consonant. In fact, this is by far the best argument for an alternative model.
One might argue that such sequences do not represent anything meaningful; this is correct, but this should not prevent us to notice that there is a real need to encode those ‘presentation forms’, such as Devanagari half-forms in isolation. In fact, the quest to encode the subjoined consonants forms in about all scripts except Devanagari and Tamil, is probably the mostly asked question once the basic step of understanding the virama-based model has been passed.
Regarding the non-defective sequence however, it should be clear at this point that it is quite possible to read the current text so that this should have the ‘natural’ effect to prevent ligature while at the same time avoiding the use of virama, as it is described page 225. At any rate, the example of ಕ್ಕ would be the same as the one without ZWJ, since there is absolutely nothing special here. And while keeping with Kannada, considering ಕ್ತ್ವ which in some fonts exhibits a special ligature of the subjoined ತ and ವ, an intermediary ZWJ after the second virama should probably have the effect to dispell such a ligature, keeping all other things unchanged and in particular using a subjoined form for ತ.
An interesting point is done at the end of section 4.3. I think the second part is mostly correct, that is, “if a sequence χ is used to encode a C2-conjoining form in isolation, then the sequence <C1, χ> *could be* used to explicitely request a C2-conjoining form rather than a conjunct-ligature form.” However, this does not endorse the first part (hence the modification I did above), which basically can be understand as if the sequence χ would be the only way to achieve this. At any rate, this is impossible to achieve in the cases already identified (avoiding Bengali and Kannada repha using respectively ZWNJ before and ZWJ after the virama, see pages 9 and 15 of the proposal), unless of course the respective sequences are confirmed to be the way to go...
4.4 Problems related to ZWJ in Indic scripts: Ambiguous C1-/C2-conjoining sequences
Before dealing with this section, I should highlight that another problem is that ZWJ has already been [ab]used, and more than once, with ad-hoc hacks for the rendering of special features of the Indic scripts. Beyond Devanagari half-forms, an important case is the so-called eyelash repha, used in Marathi and Nepali when written in Devanagari script. While there is an alternative encoding since Unicode 3.0 using ऱ that avoid ambiguity (and might allow for rendering of this presentation form using the sequence <U+0931, U+094D, U+200D>, to be confirmed), Unicode 1.1 and 2.0 did use another sequence, <U+0930, U+094D, U+200D>, that is still available. Now, what should be the rendering of this very sequence when, instead of preceding some consonant (usually य or ह), it is in isolation? One may expect the same as <U+0931, U+094D, U+200D>, i.e. a standalone version of the eyelash repha (this is what produces Microsoft's Uniscribe, by the way). But the whole document reviewed advocate for another presentation form, namely the repha (which is only a special case of a C1-conjoining consonant); furthermore, if this sequence cannot be guaranteed to be used to present the repha, then we are really lacking one, since there is no obvious alternative, and of course there as much need to present the repha than for any other of the conjoining form (and perhaps a bit more, since repha has some unusual properties that make it a candidate for any work using presentation forms in Devanagari.)
Another use of ZWJ, the Malayalam chillaksaram, have already being cited: in ന്്റ or ന്റ (U+0D28 U+0D4D U+200D [U+0D4D] U+0D31; റ is supposed to be rendered in subjoined form below the chillaksaram).
Beyond the cited cases of Bengali and Kannada rephas, a very similar problem potentially exist for Oriya, unreformed Malayalam and Myanmar (with kinzi in the latter case). The same problem could have occured in Sinhala, but since Sinhala does not use ligature by default there is no possible ambiguity; on the other hand, the use of repaya with yansaya is singularly convoluted, see page 15 of the draft of SLS 1134, section 5.7; perhaps this is something that could be smoothed, for example if this proposal is adopted, and Sinhalese are willingful to amend their standard (I do not know the timing), repaya could be encoded with the more ‘natural’ <U+0DBB, U+200D, U+0DCA> rather than the current <U+0DBB, U+0DCA, U+200D>.
Another ambiguity that is not envisioned in the document is with Bengali. I already mentionned that Bengali is special in that it has both C2-conjoining and C1-conjoining consonants. The current rules for the script gives ‘priority’ to the C2-conjoining, but there is always the possibility that someone requires a distinct encoding to produce the C1-conjoining form meanwhile. Of course, the mechanism for Devanagari could be applied then; but by specifying things this way, this would preempt the <C1, virama, ZWJ, C2> sequence for this behaviour, how infrequent it might be; and the much more useful feature of preventing ligature while avoiding hoshonto would then need another encoding.
Even with Devanagari and Gujarati we can encounter some (very unusual) graphical representations that are difficult to encode: it would be the case for example for the examples at <URL:http://antoine.leca.free.fr/devanagari/rra4rya3.png>:
However, all these cases are only marginaly important. Moreover, at least two of them already have been addressed, and with different hacks. As a result, asking for “general rules [...] applied consistently across scripts” is « un vœux pieux »; and much less for implementers, which in any case have to deal with the previous inconsistences as well as adding the new, ‘consistent’ features...
In another perspective, there are other domains affecting ZWJ that are not exposed in the document.
An important one is the relationship between spaces and non-spacing marks. Unicode prescribes that a combining mark, when standing in isolation, is invalid; since there is sometimes a need to present them, Unicode also prescribes that when they follow the space character U+0020, or alternatively U+00A0, the mark should be rendered in apparent isolation from a base. The Indic FAQ on the Unicode site web used to go as far as explaining that this behaviour could be used to present the rakar form in isolation, using the sequence <U+0020, U+094D, U+0930>, which was presented as equivalent of ISCII <INV+halant+ra>, <D9,E8,CF>; this page used to be accessible as <URL:http://www.unicode.org/unicode/faq/indic-old.html> I assume this material was removed because few if any of the widely available rendering engines are able to show it (another reason might be that the answer to the question in which it is found, was plagged with errors and misinterpretations of the ISCII standard). The same interpretation was also mentionned by Mr. Davis on October 2003, according to <URL: http://oss.software.ibm.com/icu/docs/papers/IndicImplementationIssues.ppt>, slide 7. It is interesting to note that it is generally accepted that the mechanism <space+combining-mark> could be expanded to cover sequences of three or more characters; of course this is particularly true is the say sequence of marks is expected to be rendered as a whole, like it is the case for the rakar here.
As an interessant aside, very relevant to the discussion, it should be noted that Microsoft's Uniscribe, which is by far the most widely used rendering engine for Indic scripts these days, does not fully implement this mechanism. Rather, it request the user to slip a ZWJ into the sequence, just after the U+0020 character. Since it is not expected that the Microsoft engine evolves by removing the need for this ZWJ (I assume it is performance-related), one should expect that this will become a near-standard feature, or perhaps that it may be incorpored in a future revision of the Standard. At any rate, this is something that the user would have to know about, particularly when then deal with presentation forms.
Another muddy area are the presentation of vowel signs, and in general text elements, at non-standard places. Some ‘simple’ cases, like Bengali ja-phola, have been encoded without problem. But there is a long list of mor difficult cases, often where the ‘obvious’ encoding contradicts severely established rules. An example is the presence of more than one vowel sign. Often, it is envisionned to use ZWJ, in order to ‘paste’ the second sign. A particular example deals with conjuncts as well. In Sanskrit, sandhi rules ask for a terminal न्, when followed by a ल, to change to a nasalized form of ल; with Devanagari, this nasalisation is marked with anunasika or candrabindu, U+0901. Usually, the font have a glyph for the (resulting) conjunct ल्ल, where the two elements are superposed; so there is no problem in attaching the candrabindu after the second ल, it would be rendered in the correct place. This is shown at the left in <URL:http://antoine.leca.free.fr/devanagari/nasalll.png>:
. However, this is completely correct, since the candrabindu really ‘pertains’ to the first consonant, the dead one. And when the font does not have the stacked conjunct, the rendering should be the one shown to the right. Currently, there is no encoding for this situation.
Another problem that is not examined is the case when, by default, the font does not provide the ‘most dense’ ligatures. This may be the case for a font intended primarily for small resolutions, like on user interfaces. As we know, we have two mechanisms (ZWJ and ZWNJ) to ‘stretch’ ligation, but nothing to ‘strength’ it. This is contrary to the general model as explained in chapter 15. A possible solution for this problem might have been to define the use of ZWJ before the virama as requesting this strengthening, to make a counter-point to the present model where ZWJ after the virama would stretch.
Of course, these are small examples taken out a long list. My purpose here is to show that there are a lot of potential issues with the rendering of Indic scripts. As time passes, Unicode will resolve a number of these issues, and for a fair number of them this will mean ad-hoc hacks. As a result, the potential combination is very likely to exposive. So it is important to set up principles that could be applied in numerous cases, and reserves ad-hoc hacks, particularly the ones that do not scale well to other scripts (and I am thinking in the first encoding of the eyelash-ra here) to the least complex cases, where it is expected to interfere in the lesser possible way with the other hacks. A corrolary is, when there is already a mechanism, there should be very strong reasons to provide another one as a parallel ‘solution’.
5. What is needed
From the above, we can deduce that the first part of the second objective is theorically already achieved by the way of the <space, combining-mark> mechanism; however, this is hampered by the fact that a very important rendering engine does not implement this mechanism...
As a result, it appears that formulating the problem this way can and will drive to one only solution...
6. Possible solutions
There is a solution that has been discarded here: <C1, ZWNJ, virama, C2>. The inferred reason is that it does not involve ZWJ, apparently a mandatory requirement. But there is no clear explanation of the reasons for this requirement (really, a restriction in the search for solutions.) This is particularly unwelcome, since this sequence is used for Bengali, and is also envisionned by some experts in Myanmar.
6.1 Possible solutions: The <virama, ZWJ> soution
I argue against this analysis. The author has decided that, under this model, <C1, virama, zwj, C2> should represent either the half-form of C1 + C2, or C1 + sub/post-base form of C2. This departs from the text of the standard that we have analysed above, which in my humble opinion rather suggests that this sequence should provide an intermediary path between the conjunct ligature and the overt virama model.
As such, the ‘solution’ could not solve the problem of ambiguity. However, one of the two already solved cases for ambiguity, the Kannada case, precisely uses this solution!
On the other hand, the author correctly points out the problem with Devanagari, where the eyelash-repha effectively ‘stole’ the possibility to use this solution.
The second problem is in my eyes pretty odd. First, while it could be seen as a possible candidate for inclusion in chapter 4, it is not. Then, it appears pretty specific of a given implementation to me. The fact I never tried to program such a device is probably the driving reason for which I cannot really grasp it.
6.2 Possible solutions: The <ZWJ, virama> solution
I agree that this solution fits the bills exposed in the document. My further studies did not show any stopshower, either.
However, this is a new feature, so intoducing it will have the effect to obsolete all the existing implementations (not that this is expected to be a problem), something that is not even mentionned. Nor is mentionned the interaction that this new solution mght have with the surrounding characters, particularly since the added ZWJ character, which acts toward the C2 consonant, is stored at an extrema of the sequence <ZWJ, virama, C2>, thus fully exposed to possible interactions.
7 Proposal
In addition to the proposal of the <ZWJ, virama> solution, this section is also a revisiting of the whole area of rules for consonant conjoining rules. Particularly, it means a restriction over the current text, when it comes to the interpretation of the sequence <C1, virama, ZWJ, C2>. As such, a user would have to know beforehand how a ligature might ‘decay’, in order to choose the appropriate restriction (on the other hand, since this could be algorithmically computed given the current font, a elaborated input channel could help here by automatically select the correct sequence to insert when the user asks for ‘use joined non-ligated form’, the previous meaning of ‘soft-halant’.)
On a formal level, there is a number of defects for a specification:
- the rules for repha is not sufficiently precise: what happens with <ra, virama, ZWJ, C>? <ra, ZWJ, virama, C> is expected to not form repha, but it would be clearer if it were stated.
- the sentense “No other function for ZWNJ is defined.” is not appropriate: at least, ZWNJ always has the action to prevent reordering of the left matra. Also, this may be inferred as meaning that inserting a ZWNJ before a virama would be an illegal sequence, which is probably too strong a statement.
- what constitues a ‘C1-conjoining consonant’ or a ‘C2-conjoining consonant’ is not defined. This subject already have suscited heated discussions; apparently, some people think that there may be a list of such C1-and C2-conjoining consonants (probably in the form of a new Unicode property.) With the need of strong bibliographical evidence to reverse the initial classification.
- the rendering of <C1, virama, ZWJ> (resp. <space, ZWJ, virama, C2>) is not specified when C1 (resp. C2) is not C1-conjoining (resp. C2-conjoining).
- the rendering of <space, virama, C2> is not specificed, neither is <space, virama, ZWJ, C2>, nor the sequences involving non-breaking spaces.
- the status of <C1, ZWJ, virama, ZWJ, C2> is unclear, even if one can deduce that it should result in the same as <C1, virama, ZWNJ, C2> in the ausence of exceptions.
- the analysis of sequences such as <U+0C95, U+0CCD, U+0CA4, ZWJ, U+0CCD, U+0CB5> (in a attempt to revoke a possible ligature between the subjoined t and the subjoined v) may depend upon the order in which is done the analysis. Same with <U+0915, ZWJ, U+094D, U+0935, U+094D, U+092F> to request a subjoined form for the v, stacked with the k.
Antoine Leca
Corbera, 4 août 2004, 02:00 TU soit 04:00 locales. 18:00 la veille, heure de Californie.
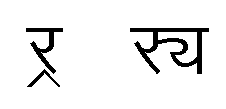

{kind=link}
{kind=link}