Graham Asher
Symbian Ltd
This paper was delivered to the 16th International Unicode Conference Amsterdam, The Netherlands, on 30th March 2000. It was published in the conference proceedings. Copyright (C) Symbian Ltd., 2000. Duplication of this material without express permission of Symbian Ltd is prohibited.
EPOC is an operating system for mobile ROM-based devices including mobile phones and palmtop computers. It is used on Psion palmtops and the new Ericsson R380 smartphone among others. Former versions of EPOC used an eight-bit character encoding. During 1999 a new Unicode version of EPOC was released. Changing the character representation from 8-bit to 16-bit was only one of the problems that had to be solved. In addition, the standard Unicode collation and compression systems were implemented at the base level of the operating system, and control codes and special character encodings were changed from in-house values to standard Unicode. One of the most interesting tasks, which is still in progress, was to add support for complex scripts and bidirectional text to the text layout system. EPOC differs from most other operating systems in including text layout as an integral part. This paper describes how some of the design issues in adding these Unicode capabilities were tackled, and attempts to demonstrate how easy it is to write Unicode-compliant applications in EPOC. The conclusion of the paper is that EPOC now supports Unicode well enough to justify the claim 'EPOC does Unicode'.
As a way of getting started I shall show you some non-Latin scripts on EPOC and discuss what is happening. Then we can look at how we got there. (The screen shots are of the EPOC emulator running on Microsoft Windows NT; it is identical in almost every respect to EPOC running on an target device-an actual palmtop or smartphone.)
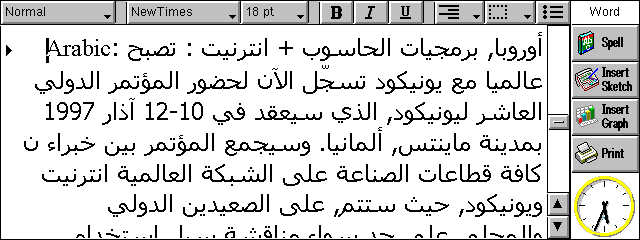
Here is some Arabic. We use a minimal rendition of Arabic, with no ligatures apart from the compulsory one, lam with alef. In this example you can see that some bidirectional reordering is happening, because apart from the word 'Arabic' at the start there is a number, the year 1997, which is displayed left to right within the right-to-left Arabic, and a range of numbers, 10-12, which appears as 12-10. EPOC implements the standard Unicode bidirectional reordering algorithm. Most of the diacritics seen here are parts of characters, but there is one floating diacritic, shadda, which looks like a little w; one of these is about half way along the second line.

The next example shows some Chinese and some Russian. The Russian is easy, of course, being just another small alphabetic script. Chinese is at first glance equally easy once the fact of the huge number of characters has been dealt with. There are some more subtleties, because Chinese line breaking has special requirements. We can break freely between Han characters, but some characters like commas and closing parentheses can't occur at the starts of lines, and some others, like opening parentheses, can't occur at the ends of lines. Also, this paragraph is fully justified, and in Chinese we can do this by inserting extra space between Han characters, even though there are no space characters there.
Earlier versions of EPOC used the 8-bit Windows character set and an encoding known as Windows Code Page 1252. 256 code points are quite adequate for Western European languages, and EPOC was successfully delivered for various locales including French, Dutch, Italian and German. Although there was some provision in the locale system for producing versions of EPOC that used other code pages, so that in theory EPOC could have been shipped in Russian, Greek or for any other locale for which 256 characters sufficed, in practice this would have been difficult to support because of assumptions about character values elsewhere in the operating system, and because of the questions it raised about interchanging data files, both between different versions of EPOC and between EPOC and the outside world. This led some of us to state emphatically that EPOC would never support code pages.
EPOC was shipped as an 8-bit-text system until 1999. The last 8-bit version was known as EPOC Release 5, or just ER5. Subsequent releases are all Unicode; the first of these is intended as not much more than a Unicode port of ER5, and is called ER5U. ER5U shipped in late 1999 and will appear on the new Ericsson R380 smartphone and products from other EPOC licensees (who include Nokia, Motorola, Psion, Matsushita and Philips).
Creating ER5U meant taking the huge code base of EPOC and all its applications - word processor, spreadsheet, web browser, e-mail, database, and so on - and making everything work in Unicode without extensive rewriting.
Getting from 8-bit text to Unicode was made much easier by something that was built into EPOC from the start: the dual-build system. Right from day one all EPOC development happened in two ways; both in a 'narrow' build with 8-bit text, and in a Unicode build, using the same source code with the preprocessor macro _UNICODE defined; in this build all text types used 16 bits per character.
One irritation is the fact that Code Page 1252 is not quite identical to the lower 256 code points of Unicode. 1252 contains some useful characters like bullet, ellipsis and the recently added Euro currency symbol; these live in the range 128-159, which in Unicode contains rarely-used control characters. This meant a certain amount of tracking down of code like '#define ELLIPSIS 133'.
But all internal text in EPOC is now Unicode, and 8-bit text has almost been forgotten. The rest of this discussion looks at how we implemented Unicode, and what it means for an operating system to 'do Unicode'.
The fundamental and apparently easiest problem in moving from 8-bit to 16-bit characters is how we write programs - what notation we use for strings and characters and how we represent them to the operating system.
EPOC's native language is C++. The EPOC API is a collection of member functions of C++ classes.
Contrary to the customs and traditions of C and C++, in EPOC we don't use null-terminated strings, for two reasons - we don't want to have to count to the end every time we want to find the length of a string, and we very much want to be able to store binary and text data using the same representation, which means dropping the use of zero as a sentinel.
This led to the descriptor, which in EPOC is a lightweight object representing a defined number of bytes somewhere. It is really just a pointer plus a length; although for historical reasons it is implemented in a slightly different way.
Descriptors are sometimes confusing, especially if you are used to ordinary C++, but they allow us to hide the character size. A simple sort of descriptor is a constant pointer to some text, and it's called TPtrC. The text can be anywhere and it is not owned by the object. Other descriptors can own their text.
Here is how we can initialise it from a C++ string:
TPtrC my_text = _S("some text");
The _S macro is defined like this:
#if defined(_UNICODE) typedef TText16 TText; #define _S(a) ((const TText *)L ## a) #else typedef TText8 TText; #define _S(a) ((const TText *)a) #endif
So we have a character type, TText, that is build-independent, and 8 and 16-bit character types TText8 and TText16 that are defined as unsigned 8 and 16-bit integers respectively.
There is a third character type, TChar, which is used for the abstract notion of a character value and can contain any unsigned 32-bit value - and so can handle the Unicode values above outside the 16-bit range that are represented as surrogates when they are in strings. We use this when we want to get character attributes.
(Some of the following examples work only in the Unicode build because some of the functions - for example, GetTitleCase - don't exist in the narrow build. That doesn't matter; applications written for the narrow build get the information they need using functions that exist in both builds.)
For example, we can get case variants like this:
TChar x = 0x01C9; // x = 'lj' TChar x_uc = x.GetUpperCase(); // x_uc = 'LJ' (U+01C7) TChar x_tc = x.GetTitleCase(); // x_tc = 'Lj' (U+01C8)
We can get most of the attributes of a character at once like this:
TChar::TCharInfo info; TChar(0x10DA).GetInfo(info); // Georgian letter las // info.iCategory = ELetterOtherGroup // info.iBdCategory = ELeftToRight // info.iCombiningClass = 0 // info.iLowerCase = 0x10DA // info.iUpperCase = 0x10DA // info.iTitleCase = 0x10DA // info.iMirrored = FALSE // info.iNumericValue = -1 (= none)
When EPOC applications store their data they typically use serialisation member functions of the data storage classes. (Serialisation is the conversion of a data structure to an ordered sequence of bytes). These functions write the data to an output stream that may represent a file. When Symbian floated the idea of a Unicode build of EPOC some licensees were worried that text stored in files would double in length because each character would now take two bytes, not one. We managed to allay their fears by implementing the Standard Compression Scheme for Unicode, and plugging support for this in at the lowest levels of the serialisation system.
Whenever a descriptor is written out - and descriptors are used for essentially all text in EPOC - its contents are compressed. When it is read in it is decompressed. Compression and decompression happen automatically; but for applications and EPOC modules that need it the compression system can also be invoked explicitly.
I expect that everybody here knows about the Standard Compression Scheme for Unicode, so I will not explain it in detail. It is enough to say that it compresses most alphabetic text (text in languages using the Latin, Greek, Cyrillic, Indic and other alphabets) down to 8 bits per character, while leaving sequences of ideographs alone. Compression and decompression can be done quickly on the fly using very little context.
Text held in memory is not compressed. It is just stored as strings of 16-bit integers - C arrays, in fact - represented as EPOC descriptors. Array storage is so convenient that it is not worth giving up. In fact, it would have been almost insuperably difficult to do so and bring EPOC and its applications from 8-bit characters to Unicode with the source code unchanged.
Character attributes supplied by 8-bit libraries can be stored very easily and cheaply in a series of 256-byte tables. Usually there is one for the category (punctuation, number, capital letter, etc.) and some more for the mappings to uppercase, lowercase and folded versions, and to the collation value. For varying locales, which in 8-bit systems include the notion of variant encodings, we could install a complete new set of tables.
Obviously this approach could be used for a 16-bit encoding, and some operating systems may well do so, but on EPOC we have to think a little more carefully because of the need to conserve ROM.
Here is my rough calculation of the table sizes using exhaustive tables. I have completely neglected the problem of the attributes of characters in planes 1-16, which are outside the 16-bit range. I have also not bothered about the collation value, which I'll deal with later, or with some attributes like CJK width and line breaking properties.
| Character attributes: worst case storage | |
| attribute | bits |
| category | 5 |
| bidirectional category | 5 |
| combining class | 8 |
| lowercase mapping | 16 |
| uppercase mapping | 16 |
| titlecase mapping | 16 |
| mirrored attribute | 1 |
| numeric value | 16 |
| Total | 83 bits = 11 bytes |
| Total table size = 65,536 * 11 = 704K | |
In a ROM budget of 8-12 megabytes 704K is more than I dare ask for. So we use a very simple approach based on some characteristics of the data. There are better ways of compressing the data, I am sure, but this way is easy to implement and makes it easy to rebuild the data when a new release of Unicode comes along; and makes it easy to provide tailorings for locales.
Firstly, large numbers of characters have identical attributes. Secondly, few characters share a case mapping, but many share the offset from their value to the case mapping, so we store the offset; and this approach is also useful for numeric values.
This is how EPOC stores the data for a character.
| Character attributes as actually stored by EPOC | ||
| attribute | bits | |
| category | 8 | |
| bidirectional category | 8 | |
| combining class | 8 | |
| digit offset (offset from the low 8 bits of the character value to its numeric value, if the numeric value is in the range 0...255) | 8 | |
| case offset (offset from the character value to the other case, for upper and lower case characters) | 16 | |
| flags: case variants, mirrored property, numeric value for large numerics | 8 | |
| Total | 56 bits = 7 bytes; actually takes 8 because of alignment | |
| Total table size = 18950 bytes. (There are 263 different combinations of attributes actually used by Unicode characters in release 3.0, giving a basic attribute table size of 263 * 8 = 2104 bytes. Add to that a trie-a packed multi-branched tree-stored in 16,846 bytes.) | ||
The same data is thus stored in 1/38 of the space apparently needed. The cost is in the unpacking, which is relatively small. To get the attributes of a character we traverse the trie by means of two or three array indexing operations, yielding an index into the attribute table, which gives us the raw attribute data. We then need to do a little arithmetic to get the actual uppercase, lowercase and other values. We also fudge the issue for titlecase, which you may have noticed is not in the table above; titlecase is hard-coded, a decision that we may have to alter - but I think that is unlikely.
To clarify this idea, let us look in detail at how we extract the attributes for the character U+10DA, which is a letter of the Georgian alphabet. We take the top 12 bits of the character value and use that number, 0x10D or 269 in decimal, as an index into the first stage of the trie, yielding the number 0x8036, which gives us access to the attributes of the 16 characters U+10D0...U+10DF. The top bit is set, indicating that all 16 characters have the same attributes, the index of which is the rest of the number, 0x0036 or 54 in decimal.
When the top bit of the index is not set we add the low four bits of the character code to it and use the new value as an index into the second stage of the trie, which contains the attribute indexes for all the ranges of 16 characters that are not all the same; this stage is packed by overlaying the ranges as far as possible.
Here is part of the attribute table, showing element 54 in grey.
| general category | bidirectional category | combining class | digit offset | case offset | flags |
| Lu | L | 0 | 0 | 218 | has lower case |
| Lu | L | 0 | 0 | 217 | has lower case |
| Lu | L | 0 | 0 | 219 | has lower case |
| Lo | L | 0 | 0 | 0 | none |
| Ll | L | 0 | 0 | -56 | has upper case |
| Lu | L | 0 | 0 | 2 | has lower case, has title case |
| Lm | L | 0 | 0 | 1 | has lower case, has upper case, is title case |
By collation we mean the comparison of strings to obtain a dictionary ordering, or some other ordering that is more useful than what is yielded by comparing the raw character codes.
In the old 8-bit build of EPOC the collation system was very simple and worked on a character by character basis. Each character was converted using a 256-element table into a collation value, and the translated strings were compared in the usual way.
Unicode collation is more difficult, partly because of the increase in the code space, and partly because collation as understood nowadays means much more. We want to be able to do all of the following:
As usual, EPOC follows the suggestions of the Unicode Consortium and makes use of the Unicode Collation Algorithm, which enables us to do all of these things. Collation keys are stored in a very similar way to character attributes; a table contains ranges of Unicode characters with the same key, plus an index into the key table, which stores the actual key values.
Collation is very locale-dependent. An interesting question was how to split the collation data into two sets: general and locale-specific. For a given locale it is more efficient to store a single table containing the tailored data for that locale; but for two reasons we did not take that approach. Firstly, we need to provide a predictable and uniform 'basic collation method' that is available in all locales. Secondly, some licensees want to be able to store data for many locales and choose a particular data set on first bootstrapping the device; completely separate tables for ten or twenty locales might take up too much space.
What I eventually decided was to store in the basic table just the collation keys for the WGL4 character repertoire (Windows Glyph List 4 - a Microsoft standard), which contains Latin, Greek and Cyrillic letters and a good set of symbols, with the addition of the most common control characters and spaces. A typical European collation locale would be able to use this table together with an extremely small tailoring table to get exactly the results it needed. For example, tailoring for Swedish collation requires 168 bytes of data in addition to the standard table.
Chinese, Japanese and Korean collation is difficult, because these locales use a variety of different orderings for the Han characters; and another problem is that multiple collation methods are needed for a single locale. This means that the tailoring tables are much larger for these locales, but that is unavoidable. We also had to invent new comparison functions that allow the collation method to be specified, if it is different from the default method for the locale; and we may have to introduce a way of setting the default collation method for an application, although we have not done that yet.
Strings are compared by the collation system in a rather obvious way. Rather than translating entire strings to sequences of collation keys, the translation is done on the fly until the strings are found to be different, or one of them ends. A further complication is Unicode normalisation; this is also done on the fly by fully decomposing each character, if possible, into its canonical decomposition.
The Unicode collation system has four levels which successively take into account the following information:
1. Basic character identity ('A', 'a', and 'ã' are the same; 'a' is different from 'b').
2. Diacritics ('a', 'ã' and 'ä' are distinct).
3. Case and other minor distinctions ('R', 'r' and U+211C (black-letter capital R) are distinct).
4. Unicode character value (distinguish Greek coronis (U+1FBD) and psili (U+1FBF), which have identical collation keys at levels 1-3).
There are up to four comparison passes, one for each of the levels, but to avoid the time-consuming looking up of the collation keys each time, all four collation values for the first 16 characters of each of the two strings being compared are cached during the first pass.
The old EPOC font system was simple. Fonts were vectors of bitmaps at a few fixed sizes and were stored in ROM. A character code could be used to select a glyph uniquely. The encoding of characters in a font was arbitrary.Independently of the move to Unicode there was a need to support scaleable outline fonts in formats like TrueType. This requirement enabled me to re-engineer the font system and ultimately (although this work is not yet finished) to provide the information needed for complex script support.
The font system has been changed in two ways. First, naturally, the encoding has been changed to Unicode for all fonts, including those in the traditional bitmap format. Secondly, there is now a plug-in system for rasterizers so that pretty much any font format can be supported. The most important of the standard font formats is TrueType, and we support it by means of a rasterizer based on the excellent open source FreeType library.
A font system now has to do much more than accepting a character code and returning a glyph and a few simple metrics. There is no longer a one-to-one mapping between character codes and glyphs; and glyphs can no longer be laid out in a simple way. Ligations can occur, glyph choice can depend on context, and floating diacritics must be placed properly.
This problem can be solved quite easily by insisting on a particular font format, for instance TrueType or OpenType, and allowing modules at various levels, up as far as text layout, knowledge of that format and its data structures. This is, however, a bad idea. It defeats the idea of a plug-in rasterizer system and takes away all the flexibility that gives us. EPOC licensees don't want to be tied to TrueType or OpenType. Other more compact font formats are available, and some of these might give us the information we need for complex layout.
A better way is to generalise the problem of glyph selection and positioning and provide an interface through which any rasterizer can provide the information needed for text measurement and layout. This is in progress at the moment, so I won't go into very much detail, except to say that it enables EPOC to do ligation, contextual glyph selection, kerning and diacritic placement in a completely general way, and will also include support for vertical text. By the time this talk is presented I hope to be able to demonstrate some of these features and explain how they work.
EPOC has always provided rich text storage and layout as a fundamental operating system service. This is part of the code sharing approach that has allowed EPOC to do so much in such a small amount of ROM. There are two main components:
ETEXT stores the text content and attributes but not the layout. The content is a string of Unicode characters separated into paragraphs by the unambiguous Unicode paragraph separator, U+2029. The text is stored in logical order - that is, the order used to input the text, which is not necessarily the same as the display order. The attributes are what you would expect: paragraph alignment and indents, character size and font, line spacing, and so on. ETEXT class objects are essentially containers for rich text.
FORM formats the text for display. FORM class objects contain the layout information for some text, but not the text itself, or the attributes. These are obtained, usually from ETEXT, via an abstract interface class.
Higher-level objects like text edit controls typically own one object from each of these components: an ETEXT object to hold the rich text and attributes, and a FORM object to store the layout and draw the text.
Implementing full Unicode support, including all the behaviour needed for multilingual text and complex scripts, was doubly difficult in EPOC because of the need for applications written for the 8-bit system to be ported easily to the Unicode build. The FORM and ETEXT API had to be preserved as far as possible intact, at least in the medium term; there was no prospect of rewriting all the applications and GUI components for a new API that would not even be in a mature and stable state during the rewriting process.
I realised quite early on that FORM's layout engine could not be adapted to provide the new features needed for Unicode support, particularly bidirectional reformatting, contextual glyph shaping, ligation and diacritic placement. FORM was based on the following assumptions:
These assumptions worked well when a restricted set of fonts supplied with EPOC was used, and the only locales supported were those that could be accommodated by Windows code page 1252. All of them, though, are incorrect for the new scripts that EPOC needs to support.
The solution I adopted was to replace the layout engine with a new low-level component called (rather arbitrarily) TAGMA, and rebuild FORM on top of it, using an identical API, so that legacy code, which is actually still the whole of EPOC and its applications, could go on working. The success of this is demonstrated by the fact that the web browser and word processor can display Arabic and Chinese properly, without their source code being changed in the slightest, even if they do not have quite the right editing and selection tools at higher levels.
TAGMA attempts to do everything properly, and exposes a simple API that can be used by FORM and ultimately by a new set of higher-level text layout classes. The fundamental TAGMA class is CTmTextLayout, which owns a piece of layout for some Unicode text supplied by ETEXT via an interface class; and CTmText, which is a label class, in other words it owns both its text and layout and is a graphic object that can be used for drawing small pieces of text.
A CTmText object is lightweight, if not quite flyweight. It is also very quick and easy to construct, and so it is feasible, when drawing rich text, to construct a CTmText object on the fly, draw it, then throw it away. This would typically be done when drawing the text of a spreadsheet cell, a menu item, or a filename on the desktop, all of which potentially require the full power of multilingual complex text support.
Although text input is not an essential part of Unicode compliance, and of course the problem of inputting text in complex or large scripts predates Unicode, I'll briefly describe how EPOC handles the task.
Languages like Chinese have too many characters for a keyboard and require input method editors that allow a user to select characters phonetically or by some other multi-keystroke method. EPOC does this by means of front end processors (FEPs).
The FEP is loaded by the control environment, which handles controls like editors and the events that are consumed by them. Controls are organised as a priority queue, and FEPs have the highest priority and receive keyboard events before nearly all other controls. That allows them to convert sequences of keystrokes into other key events which are then sent to the control list again, ignored by the FEP, and optionally consumed by one of the other controls in the list, like an editor.
FEPs can display a small window in which characters are entered or selected from lists, and the current settings and modes are shown; or, if the application supports it, they can allow the editing and composition to happen in the application's own window; this is called in-line editing. FEPs can also be written to recognise handwriting. The picture below shows Chinese being entered using an FEP.
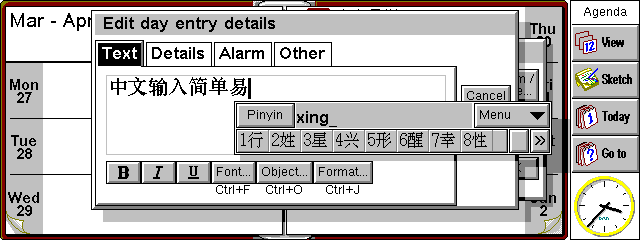
Some languages with relatively few characters, which have no need of a FEP, nevertheless require something more than a straight mapping from keystrokes to character codes, even with the extra choices given by control and shift keys. For example, it may be convenient to input accented characters by means of dead keys. A state machine at the keyboard translation stage does this. It is customisable for different locales.
Here is what EPOC provides in the way of Unicode support so far:
Encoding conformance. Characters are 16-bit units. All 16-bit characters can be used in text. All character values can be stored and retrieved unchanged, and imported and exported as plain text. Character values that have some meaning always have the standard Unicode meaning, apart from private-use characters, of course.
Standard Compression. The Standard Compression Scheme for Unicode is used by default to store text in files. No extra work is needed by applications for this to happen.
Character attributes. Character attributes, mappings, compositions and decompositions are as defined in the Unicode standard. Character attributes and mappings can be tailored for locales.
Collation. The Unicode Collation Algorithm is used for collated string comparison. Collation is fully tailorable for locales.
Line breaking. The Unicode Consortium's technical report on line breaking was used as a basis for the line breaking rules employed by the text layout system. Line breaking behaviour can be tailored for locales.
Bidirectional reordering. The text layout system uses the Unicode Bidirectional Algorithm for resolving the display order of text containing Arabic, Hebrew and other right-to-left scripts.
Complex scripts. The text layout system co-operates with the font system to support complex scripts, by obtaining presentation forms, performing ligation and positioning diacritics.
Unicode values greater than U+FFFF. EPOC does nothing yet with surrogates or Unicode values outside the range U+0000 to U+FFFF, but support has already been built in to the API; functions that accept and return single character values (e.g., TChar::GetLowerCase) use 32-bit unsigned integers.
General text searching. Many EPOC applications need to search for text, and at the moment they all have their own searching routines. Proper general text searching, making use of the collation system, and possibly including support for regular expressions or some other wild-card notation, is exceedingly complicated and ought to be implemented just once, as a system facility, possibly allowing searching across multiple files.
Fallback fonts. If a character is not present in a font it is not displayed; you have to choose a font that contains the character. EPOC might in the future automatically look for a 'fallback font' that contains the desired character, and use that instead. This is made easier by the fact that now all fonts share the same encoding, Unicode.