In a message dated 2001-12-02 11:00:32 Pacific Standard Time,
everson@evertype.com writes:
> "o." and "o-with-underscore" are NOT glyph variants of a ligature of
> e and t (at a character level), no matter what they mean.
I suggested that Stefan's o-underscore "and" might OR might not be a
variation of the ampersand, in all its many existing glyph variants.
The "glyph variant" side is bolstered by the argument that it's a symbol,
just like &, used to mean "and" without any translation necessarily taking
place; that it's only used in Swedish; and that users consider it equivalent
to & and use different forms depending on whether the text is handwritten or
typed.
The "separate character" side can point to the fact that its derivation is
completely different from that of &; that it looks nothing like any of the
existing forms of & (like TIRONIAN SIGN ET); and that it's only used in
Swedish (cf. GREEK QUESTION MARK).
I don't think there is one obvious answer to this. I will say this, however:
The majority of posts stating that some character or other is "not in
Unicode" turn out to be bogus; the proposed character is really a glyph
variant or presentation form. Stefan's original post had the following three
points:
1. Swedish "o-underscore" -- maybe, maybe not
2. Fraction slash -- already encoded
3. Roman numerals -- overextension of compatibility forms; rendering issue
When two of three proposals can be quickly blown off, it is human nature that
sometimes it is difficult to see the potential virtue in the third.
I also want to say that, although Michael is of course correct that & was
originally a ligature of e and t, many, many of the & glyphs seen today do
not even remotely resemble such a ligature. Consider the top three glyphs in
the attached GIF (only 290 bytes). The first is obviously still an e-t
ligature, the second is one with centuries of typographical evolution applied
to it (and today more closely resembles a treble clef), the third is not at
all. If traceability to the original Latin "et" were what made these
characters the same or different, then that might have spoken against the
separate encoding of TIRONIAN SIGN ET.
I never think of & as meaning "et," even the glyph variants that do look like
an e-t ligature. I assume that practically all users of this symbol treat it
as a logograph meaning "and" in the language of the surrounding text. (I
have, rarely, seen & used in Spanish text, which strikes me as funny since
the Spanish words for "and" ("y" and "e") would not seem to need
abbreviating.)
So the question might be posed, do Swedish users think of o-underscore as a
logograph meaning "och" or as an abbreviation for the spelled-out word "och"?
In a message dated 2001-12-02 9:23:51 Pacific Standard Time,
everson@evertype.com writes:
>>> Having said that, it seems to me that U+00B0 would represent Stefan's
>>> character easily enough.
>>
>> No. It's not a degree sign. Nor is 00BA appropriate: the underlined o is
>> not superscripted/raised (much, if at all).
>
> Sorry, I did mean U+00BA, and subscription or superscription of the
> glyph in that character is a matter of glyph choice.
I think, though, that use of U+00BA MASCULINE ORDINAL INDICATOR would be a
classic example of hijacking a character for an unintended and inappropriate
purpose simply because its glyph looks "close enough." This would be like
using U+003B at the end of a Greek question. I stick to my original
suggestion of U+006F U+0332, crossing my fingers that rendering engines will
handle this correctly.
-Doug Ewell
Fullerton, California
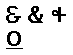
This archive was generated by hypermail 2.1.2 : Sun Dec 02 2001 - 18:48:21 EST