- Previous message: Alan Wood: "RE: Why isn't my character displaying"
- Maybe in reply to: Andy White: "Proposal to add Bengali Khanda Ta"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
Andy White wrote:
> Marco wrote
> >
> > I have a few questions:
> >
> > - What is the meaning of "satmaa" and "sadaatmaa"?
>
> 'satmaa' means stepmother. 'sadaatmaa' means 'good soul' / 'virtuous'
Bingo! Well, nearly... My guess was that "satmaa" was the Bengali for
"Wachstube". :-)
German has two different words spelled "Wachstube" which pose similar
problems, when set in Fraktur. In "Wach(-)stube" ("guards room"), "s" and
"t" should form an "st" ligature, while in "Wachs(-)tube" ("wax tube"), "s"
and "t" should remain separate because they are parts of two different
roots. For Fraktur, the proposed solution is to encode the second case as
"Wachs<ZWNJ>tube".
But unluckily this cannot work for "satmaa" because of the special Indic
behavior of ZWNJ.
> > - Why is /tmaa/ spelled differently in the two words?
>
> 'satmaa' has the roots of 'sat' = good & 'Maa' = mother. As
> 'Sat' is correctly spelt with a khandaTa under the rules of
> samaas it becomes 'sat'maa'
> sadaatmaa has the roots 'sat' = good & 'aatma' = soul /
> spirit, and falls under the rules of sandhi and hence becomes
> sadaatmaa.
> (aatma is spelt with a tma conjunct).
>
> > - Does ISCII have a way to distinguish the two cases above
> > and the other possible combinations? I mean:
> > 1. Ta_Ma_Ligature,
> > 2. Khanda_Ta + Ma,
> > 3. Half_Ta + Ma,
> > 4. Ta + Virama + Ma.
>
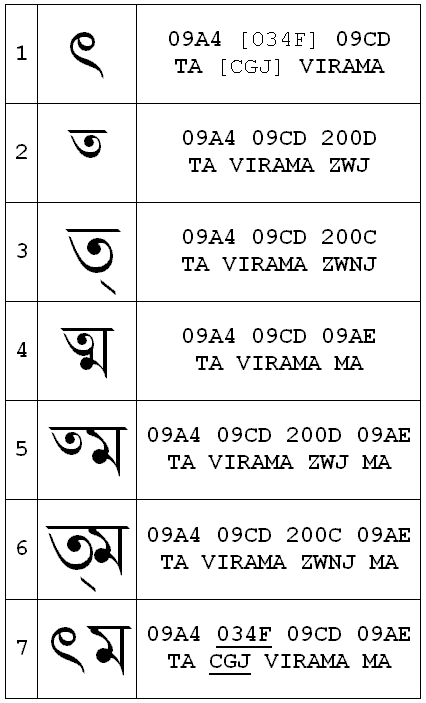
> 1. Ta_Ma_Ligature is simply 'ta virama ma'
> 2. Khanda_Ta + Ma, is 'ta virama virama ma' (equivalent to
> 'ta virama zwnj ma')
> 3. Half_Ta + Ma is 'ta virama inv ma' (equivalent to 'ta
> virama zwj ma')
> 4. Ta + Virama + Ma should be 'ta virama virama inv ma' but
> this is not implemented in the iLeap application I am using!
Cases 1, 2 and 3 are fine. For case 4, personally, I agree that you need
that Khanda Ta is unambiguously encoded.
But does this unambiguous encoding of Khanda Ta necessarily have to be a new
code point in the Bengali block? IMHO, it is possible to define an
unambiguous sequence for Khanda Ta also using existing code points, and
without violating their semantics.
My counter-proposal is:
09A4 + 034F + 09CD
(TA + CGJ + VIRAMA)
CGJ, "Combining Grapheme Joiner", is a (relatively new) zero-width character
which has been introduced to cover some functions that could not be carried
on well by ZWJ.
My idea is that a display engine should uncoditionally transform the above
sequence in a Khanda Ta glyph, *before* doing any other glyph
transformation.
This "strong" way of encoding Kanda Ta would anyway not exclude the default
"soft" formation of Khanda Ta at the end of a word, whith the simple
sequence:
09A4 + 09CD
(TA + VIRAMA)
The reasons for proposing such a (relatively) complicated solution as
opposed to the simpler solution of adding a new code point are:
- To keep a certain compatibility with existing display engines. Upon
sequence <09A4 + 034F + 09CD>, an old display engine would display something
odd but, however, the text should stay *readable*.
- To keep a good compatibility with existing non-visual software. All code
which searches or compares text should already know what to do with CGJ:
ignore it.
- To try and keep the architecture of the Bengali block in sync with the
other Indic blocks, because this helps implementers in re-using code.
I have summarized my counter-proposal in the attached picture. Comments? Can
it work? Is it possible to implement it in, e.g., OpenType fonts?
_ Marco
- Next message: Tom Gewecke: "RE: Why isn't my character displaying"
- Previous message: Alan Wood: "RE: Why isn't my character displaying"
- Maybe in reply to: Andy White: "Proposal to add Bengali Khanda Ta"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
This archive was generated by hypermail 2.1.5 : Fri Nov 29 2002 - 10:12:46 EST