- Previous message: Doug Ewell: "Re: [hebrew] Re: Hebrew composition model, with cantillation marks"
- Maybe in reply to: Peter Jacobi: "Encoding Tamil SRI"
- Next in thread: Peter Jacobi: "RE: Encoding Tamil SRI"
- Reply: Peter Jacobi: "RE: Encoding Tamil SRI"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
> -----Original Message-----
> From: unicode-bounce@unicode.org [mailto:unicode-bounce@unicode.org]
On
> Behalf Of Peter Jacobi
> I'm looking for enlightment, how to best (or least bad) encode Tamil
SRI
> in Unicode. The glyph can be seen as codepoint 0x82 of TSCII 1.7 at
> http://www.tamil.net/tscii/charset17.gif...
{kind=link}
> 0x82 : 0x0BB8 0x0BCD 0x0BB0 0x0BC0
That is exactly how it should be encoded.
> So far, feedback from Tamil experts I got, seem to indicate that no
> satisfiable encoding
> exists and they would prefer a distinct codepoint, which was rejected.
Of course, in order to comment, one would need to know why the above is
not satisfactory.
> For example 0x0BB8 0x0BCD 0x0BB0 0x0BC0 is the word 'laughable' in
Tamil.
>
> Alternatives given were
> (0BB8)(0BCD)(0BB1)(0BC0)
> (0BB6)(0BCD)(0BB1)(0BC0) (if and when U+0BB6 becomes Unicode)
> (0B9A)(0BBF)(0BB1)(0BC0)
Alternatives to what? The first and third sequence would have distinct
appearances (see attached file), and would consistute distinct
spellings. The second cannot be evaluated without knowing what they
intend 0BB6 to be.
Peter
Peter Constable
Globalization Infrastructure and Font Technologies
Microsoft Windows Division
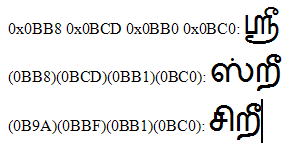
- Next message: Peter Kirk: "Re: Merging combining classes, was: New contribution N2676"
- Previous message: Doug Ewell: "Re: [hebrew] Re: Hebrew composition model, with cantillation marks"
- Maybe in reply to: Peter Jacobi: "Encoding Tamil SRI"
- Next in thread: Peter Jacobi: "RE: Encoding Tamil SRI"
- Reply: Peter Jacobi: "RE: Encoding Tamil SRI"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
This archive was generated by hypermail 2.1.5 : Wed Nov 05 2003 - 19:48:58 EST