- Previous message: Dean Snyder: "Re: Cuneiform - Dynamic vs. Static"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
The current suggested methodology for dealing with cuneiform merger and
split trees is to encode just the roots of the mergers and leaves of the
splits. I have always objected to this and here is why.
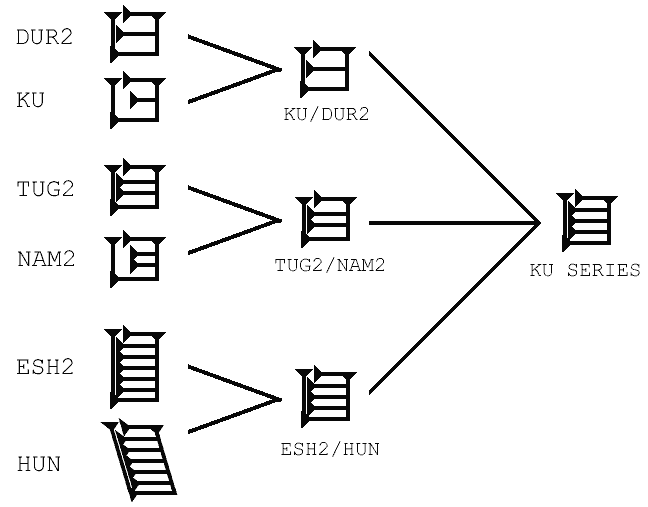
If you look at the attached example of the KU series of mergers (taken
from D. O. Edzard's Reallexikon der Assyriologie "Keilschrift" article),
the current suggestion would be to encode only the 6 roots - DUR2, KU,
TUG2, NAM2, ESH2, and HUN. The problem with this is the ambiguity that
results in plain text from such an approach.
If I input "KU" how do I know in plain text which KU this is? The one
with 6 ancestors, the one with 2, or the one with none? The reality is
that, due to the diachronic nature of cuneiform, there is only one KU
sign, then there is a KU/DUR2 sign, and finally a KU SERIES sign. There
are not 6 characters in this tree; there are 10, and that's what we
should encode.
The complexity can be handled easily by input methods, one for each level
in the tree. So when I am working on a later text I will input the
character sequence "k" + "u" + SYLLABLE TERMINATOR and the input method
for that period will enter the CUNEIFORM KU SERIES character; when I do
the same thing for text in the earlier period the input method for that
period enter the CUNEIFORM KU AND DUR2 character.
Respectfully,
Dean A. Snyder
Assistant Research Scholar
Manager, Digital Hammurabi Project
Computer Science Department
Whiting School of Engineering
218C New Engineering Building
3400 North Charles Street
Johns Hopkins University
Baltimore, Maryland, USA 21218
office: 410 516-6850
www.jhu.edu/digitalhammurabi
- Next message: John Hudson: "Re: Panther PUA behavior (was RE: Cuneiform - Dynamic vs. Static)"
- Previous message: Dean Snyder: "Re: Cuneiform - Dynamic vs. Static"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
This archive was generated by hypermail 2.1.5 : Tue Jan 13 2004 - 20:21:20 EST