- Previous message: Bob_Hallissy@sil.org: "Re: interesting SIL-document"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
Dean Snyder wrote,
> In preparation for tomorrow's Unicode Technical Committee meeting, and
> for general review and comments, I have uploaded a 140kb PDF file that
> illustrates some usage examples of the proposed Cuneiform Ideographic
> Descriptors.
>
> <http://www.jhu.edu/ice/basesigns/CuneiformDescriptorUsage.pdf>
>
> Circumstances have forced me to get this out in a hurry and I know there
> are mistakes in it, but I believe it will still be useful as a point of
> departure for discussion. [As an exercise for the reader, see if you can
> find any mistakes ;-)]
>
In circled 9 and 10, the same code point (1221B) is given for "LU2 SQUARED"
and "LU2 TENU".
In circled 15, the same glyph is used for 1240A INFIX and 1240B OUTFIX.
Glyph descriptors could theoretically be applied to any script. Once
more than one or two strokes are used to form glyphs, there are bound
to be recognizable components.
So, I think I understand how the system you are proposing works, although
some of the sequences are less than clear for me, perhaps because I'm not a
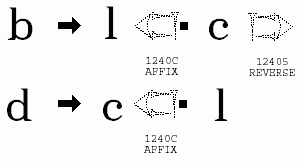
Cuneiform expert. Please see attached 4KB GIF picture in which graphics
from the PDF file were borrowed and applied to some Latin glyphs. What
I'm not understanding is why this approach should be considered superior
to the "static" approach underlying the current Cuneiform proposal.
Cuneiform ideographic descriptors could be quite useful for illustrating
the components of existing Unicode Cuneiform characters as well as
providing a method for scholars to describe hitherto unknown and/or
unencoded characters.
But, I share the concern expressed by others on this list that bringing
up an alternative encoding method for Cuneiform at this stage might
derail the existing proposal, which appears to be "on-track".
Best regards,
James Kass
- Next message: jcowan@reutershealth.com: "Re: interesting SIL-document"
- Previous message: Bob_Hallissy@sil.org: "Re: interesting SIL-document"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
This archive was generated by hypermail 2.1.5 : Tue Feb 03 2004 - 12:13:54 EST