Date: Wed, 20 Mar 2013 20:49:32 -0600
On 03/09/2013 07:52 PM, Richard Wordingham wrote:
> On Sat, 09 Mar 2013 16:21:17 -0700
> Karl Williamson <public_at_khwilliamson.com> wrote:
>
Sorry, for the delayed reply; I've been under deadline
>> Rendering is not the only consideration. Processing textual content
>> for 0387 is broken because it is considered to be an ID_Continue
>> character, whereas its Greek usage is equivalent to the English
>> semicolon, something that would never occur in the middle of a word
>> nor an identifier.
>
> ID_Continue is for processing things like variable names. How does
> allowing U+0387 in variable names cause problems in the processing of
> text?
My day-to-day tasks involve parsing programming language text. I tend
to therefore conflate identifiers with processing general texts in the
language. Also, in the few languages I'm familiar with, identifier
parsing gives better results than just using the 'word' compatibility
property. Words in these languages don't start with digits nor
connector punctuation, and so the XID_Start property is better than
using the 'word' property, and faster and easier than full-blown word
boundary calculations.
Talking only about identifiers for the moment, no Greek would think to
include the ANO TELEIA in the middle of an identifier -- unless they
were doing so to exploit a security hole. It simply does not belong in
ID_Cont nor XID_Cont. It's a defect in Unicode that it is there.
>
> How would ID_continue allow you to process English «foc’s’le» or
> «co-operate»? The default word boundary determination has been
> tailored to give you the right results,and should work for Greek unless
> you are working with scripta continua, in which case you have massive
> problems regardless.
I claim that these examples are false analogies. These are excluded by
the default XID_Cont; tailoring would allow a program that wishes to go
beyond the basics to include them. The ANO TELEIA is the opposite,
where the default includes something that it shouldn't. This is a
set-up for security holes down the road. Time and again, experience has
shown that the default can't be to allow too much in; programs that just
handle the basics shouldn't be forced to tailor to prevent security
problems.
>
> Note also that word boundary determination is intended to be
> tailorable, which would allow one to exclude U+00B7 and U+0387 from
> words or deal with miscoded accents and breathings physically at the
> start of a word beginning with a capitalised vowel. One should also be
> able to tailor it to deal with word final apostrophes - though doing
> that in the CLDR style could be computationally excessive if the text
> may contain quoting apostrophes. One might even tailor it to allow
> Greek «ὅ,τι», depending on whether one wishes to count it as a word.
Now back to processing general text. Doing any serious analysis of text
will require using regular expressions. That means normalizing the
input, as UTS 18 finally now says. Whatever normalization you choose,
singleton decompositions are taken.
That means that ANO TELEIA becomes a MIDDLE DOT, and GREEK QUESTION MARK
(U+037E) becomes a SEMICOLON (U+003B), among other things. This really
presents a rather untenable situation for a program. You have to
normalize, but if you do, you lose critical information.
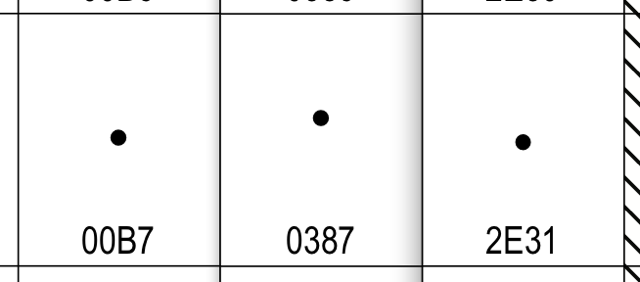
Further, the code chart glyphs for the ANO TELEIA and the MIDDLE DOT
differ, see attachment. If they are canonically equivalent, and one is
a mandatory decomposition of the other, why do they have differing
glyphs? I'm told that the one for 0387 is the correct height for ANO
TELEIA.
This is enough for now.