Date: Sun, 17 Sep 2017 20:07:55 +0100
In philological work, one encounters the problem that two or more
abstract characters have only same 'natural' transliteration; the same
problem can apply to reconstructed phonemes, where there is no sound
indication of the actual pronunciation. A common solution is to use a
subscript or superscript numeral to distinguish them. The habit of
using Western Arabic numbers ('0', '1' etc.) for this purpose has spread
to such an extent that they occur in Sanskrit in the Tamil script, and
this is recognised by SUBSCRIPT/SUPERSCRIPT TWO..FOUR having the Indic
syllabic category of syllable modifier.
Where may the superscript digits go in encoding Sanskrit in the Tamil
script? I have recently seen the digits placed after the more
conventional askhara (counting visible pulli as terminating an
askshara), but I though I had also seen them rendered between a
consonant and U+0B86 TAMIL LETTER AA. This scheme I had internalised as
placement to the right of the glyph containing the consonant.
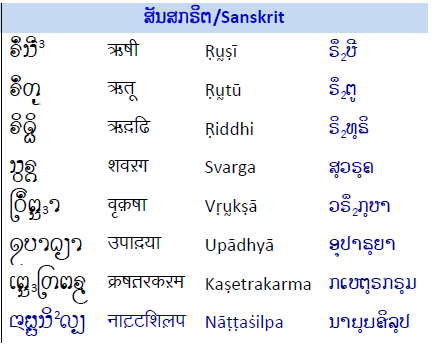
Now, I have just come across a similar device in a Lao description of
the Tai Tham script. I came across the attached table on p33 of
"Venez Apprendre des Carartères Dhammiques en Écriture de Pālī et de
Sanskrit" by Chanthanom Deuanhaksa
(http://lao-online.com/all_files/books/B01833.pdf). Rather than use ᩆ
U+1A46 TAI THAM LETTER HIGH SHA and ᩇ U+1A47 TAI THAM LETTER HIGH SSA,
which are in the font being used, the author has chosen to use the
sequences ᩈ² <U+1A48 TAI THAM LETTER HIGH SA, U+00B2 SUPERSCRIPT TWO>
and ᩈ³ <U+1A48, U+00B3 SUPERSCRIPT THREE>.
The 'only' problem with representing the text in the Lao column (the
4th column) is that it uses letters that were officially removed from
the alphabet a couple of generations ago, and therefore aren't yet in
Unicode. I'd have to hope that I don't get script run breaks between
base and combining mark. The subscript digits would go in their own
grapheme clusters. Or am I wrong about them?
However, encoding the Tai Tham column presents several issues, for the
sequences with digits also occur subscript.
A simple ad hoc solution is to treat the sequences as glyph variants of
HIGH SHA and HIGH SSA. However, would that would comply with the
Unicode standard? I think it would violate the character identities.
A secondary question is the character identity of the subscript SA.
As the writing style used does not seem to contrast the non-spacing
tailless subscript SA and the spacing 'subscript' SA with an ascending
tail, I believe the appropriate encoding for them would be <U+1A60 TAI
THAM SIGN SAKOT, U+1A48> rather than <U+1A5E TAI THAM CONSONANT SIGN
SA>. Does anyone demur?
For the fifth word, with usual transliteration _vṛkṣa_, I see several
possibilities for the encodinɡ of the second syllable:
A: <U+1A20 TAI THAM LETTER HIGH KA, U+1A60, U+1A48, U+00B3, U+1A63 TAI
THAM VOWEL SIGN AA>.
This recognises <U+1A48, U+00B3> as a semantic unit, interpreting
U+00B3 as a syllable modifier actinɡ as a spacing nukta.
Implementations of USE will object to having a syllable modifier before
a dependent vowel, but I'd just have to relax the conditions for
deleted dotted circles.
An issue with this scheme is that without a logically following
vowel, I'd have to separate digit applying to the whole word, e.g.
for a plain text endnote, I'd have to separate consonant and digit by
at least ZWNJ.
Under this solution, the second syllable of the first Tai Tham word in
the table would be encoded <U+1A48, U+00B3, U+1A66 TAI THAM VOWEL SIGN
II>. In plain text, the visually identical (or very similar) <U+1A48,
U+1A66, U+00B3> would be used to indicate that an endnote applied.
B: <U+1A20, U+1A60, U+1A48, U+2083 SUBSCRIPT THREE, U+1A63>.
Compared to A, this solves the end note problem. However, it would
look wrong if it were then rendered in a font that uses a rising tail
for <SAKOT, SA>! It also violates the character identity of U+00B3.
C: <U+1A20, U+1A60, U+1A48, U+1A63, U+00B3>
This scheme respects USE's rule that syllable modifiers come at the
end of the syllable. However, there is a problem of knowing which
consonant to associate it with. For example, in the Sanskrit form
of Vishnu written in this style, the final syllable would be <U+1A48,
U+1A60, U+1A31 TAI THAM LETTER RANA, U+1A69 TAI THAM VOWEL SIGN U,
U+00B3>, and one would need special rules to associate the digit with
U+1A48 rather than with U+1A31.
D: Encode special 'nukta' marks for spacing digit diacritics when there
are problems with using plain spacing superscript and subscript digits.
Overall, I think solution A is better than Solution D. What do others
think?
Richard.