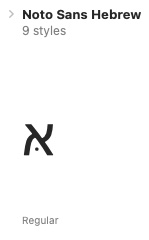Accumulated Feedback on PRI #526
This page is a compilation of formal public feedback received so far. See Feedback for further information on this issue, how to discuss it, and how to provide feedback.
Date/Time: Mon May 19 22:22:17 PDT 2025
ReportID: ID20250519222217
Name: Nick C.
Report Type: Public Review Issue
Opt Subject: Faulty glyph in the CJK Ext. J code chart [CJK]
U+32436 (VN-F1669) has a faulty stroke in the 甲 component
Date/Time: Tue May 20 11:25:15 PDT 2025
ReportID: ID20250520112515
Name: Judith Chen
Report Type: Public Review Issue
Opt Subject: PRI 526 [CJK]
According to IRG N2805R2, the G-source representative glyph for U+29B9A should be modified. However, this was not reflected in the Unicode 17.0 Beta Code Charts. I suggest updating the G-source glyph for U+29B9A, as per IRG N2805R2.
Date/Time: Tue May 20 11:32:38 PDT 2025
ReportID: ID20250520113238
Name: Judith Chen
Report Type: Public Review Issue
Opt Subject: PRI 526 [CJK]
The K-source representative glyphs for U+2A1C5 and U+2A54F have been missing since the alpha review of Unicode 17.0, and the current K-source representative glyph for U+25A38 is the same as UCS2003. I recommend updating these glyphs based on their original proposals IRG N2643R2 (U+2A1C5 and U+2A54F) and IRG N2588R (U+25A38).
Date/Time: Tue May 20 16:29:16 PDT 2025
ReportID: ID20250520162916
Name: Andrew West
Report Type: Public Review Issue
Opt Subject: PRI 526 : kEH_FVal in XML data files [PAG]
There are 15 kEH_FVal entries in Unikemet.txt that include a vertical bar () as a delimiter. In the XML data files for Unicode 17.0 beta all instances of "" in the kEH_FVal text string have been replaced by a space " ". I believe that the vertical bar should be preserved.
Date/Time: Thur May 22 14:45:16 PDT 2025
ReportID: ID20250520162916
Name: Mikael Wilander
Report Type: Public Review Issue
Opt Subject: PRI 526 : Degrees in kEH_Desc of Unikemet.txt [SEW]
There are 19 places in Unikemet.txt that mention degrees both with the degree sign as well as with the word written out. There are 56 places in total that use the degree sign, sometimes alongside the word angle, sometimes not. The grammar seems off to me in several places. Personally I would have gone for a complete removal of the degree sign and only singularily use the word degree(s). A few examples from the text file: at 90 degree at a 45 angle at a 45 degree towards at slightly over 90 degree angle
Date/Time: Mon June 02 13:15:45 PDT 2025
ReportID: ID20250602131545
Name: Biswajit Mandal
Report Type: Public Review Issue
Opt Subject: PRI 526 : Error in the names list for Chisoi [SEW]
16D82 CHISOI LETTER AI should have been CHISOI LETTER AAI. The proposal L2/218r3 had the mistake in the list of character properties on page 8; the character names on page 12 had AAI.
Date/Time: Mon June 09 02:00:04 PDT 2025
ReportID: ID20250609020004
Name: Rikza F. Sh
Report Type: Public Review Issue
Opt Subject: PRI 526 : Arabic honorific ligatures glyphs [SEW]
I have reviewed the Unicode 17.0 beta charts, particularly the Arabic Presentation Forms codepoints, and found several inconsistencies between the updated character names and the representative glyphs. In many cases, the glyphs still reflect the previous character names rather than the newly approved ones, especially regarding harakat placement. I have prepared a corrected reference image illustrating the recommended glyph adjustments for the affected codepoints. Please find it attached.

Date/Time: Mon June 09 09:24:22 PDT 2025
ReportID: ID20250609092422
Name: Allen Watkins Smith
Report Type: Public Review Issue
Opt Subject: PRI 526: U 17.0.0 Beta (11.4 Egyptian Hieroglyphs) [SEW/EDC]
In subsection 11.4.4, the example use in Figure 11-10 of brackets with
hieroglyphs has inconsistent format controls shown in the sequence starting
with "L1". First, either it should be "L1 * [" (using '*' for the format
control character), as I suspect is true, or "X1 * [" later in the sequence
should not have the "*". Second, "Z2 ( V30" (with "(" format control
character substitution) should be "Z2 * ( V30". Third, either the planned
additional material should (also) explain how brackets (even unpaired)
apparently also cause grouping as if parenthetical format controls, or the
example sequence needs further correcting. (The correct sequence may be "
( L1 * ( [ D21 : X1 * ( [ Z2 * ( V30 : X1 ) ) ) ) * ]", although I am
uncertain due to the necessity of the planned additional material regarding
sequencing of format controls; good thinking on adding that!) The code
point sequence in the paragraph above will also need correcting, and in
addition has a couple of commas missing.
The current text of 11.4 is variable (particularly between subsections) in
the use of "hieroglyph(s)" versus "glyph(s)" versus "hieroglyphic character
(s)" versus "sign(s)" (or even "hieroglyphic sign", before Figure 11-5). If
any distinctions are supposed to be made by the term chosen, they are not
communicating any clear information. For readability, avoidance
of "hieroglyphic character(s)" (or "hieroglyphic sign(s)") when possible is
preferable.
It would be nice if, particularly for the sake of professional font
(and likely specialized rendering engine) implementers who are not also
professional Egyptologists, there was a convenient listing in this section
of the hieroglyphs - as images, not code points - used in examples with the
corresponding
"L1" or whatever code. (Going back and forth between the charts and the
section is rather irritating. Labels inside the figures would be even
nicer, but likely impractical - particularly inside 17.0.0 time limits -
given, for instance, the examples in Figure 11-5.)
Date/Time: Sat June 07 03:23:28 PDT 2025
ReportID: ID20250607032328
Name: Allen Watkins Smith
Report Type: Public Review Issue
Opt Subject: PRI #526: Unicode 17.0.0 Beta (3.5.2, D23) [EDC]
Under 3.5.2 D23, there is an example of possible property values for a specific property, East-Asian_Width. The possible property values given are not correct, which is confusing. According to UAX #11, East Asian Width, the correct possible property values are "East_Asian_Fullwidth", "East_Asian_Halfwidth", "East_Asian_Wide", "East_Asian_Narrow", "East_Asian_Ambiguous", and "Neutral".
Date/Time: Sat June 21 06:37:00 PDT 2025
ReportID: ID20250621063700
Name: Lydia Trusova
Report Type: Public Review Issue
Opt Subject: PRI 526: Error in symbol U+131F5)
[EDC]
There is an error in symbol 𓇵 U+131F5 from block U+13000–U+1342F in Unicode table. According to Gardiner's list, hieroglyph E030 depicts a leopard/panther with key features of a spotted fur, long tail, and feline face.
Date/Time: Mon June 23 02:46:31 PDT 2025
ReportID: ID20250623024631
Name: Eduardo [Larry] Marín Silva
Report Type: Public Review Issue
Opt Subject: PRI 526: Regarding the notes on 027F & 0285
[SEW]
By reviewing the code chart proposed for version 17, I noticed there were new notes for these two characters, explaining that their names are misnomers and should instead be understood as modified version of a long dotless i. I dug more into the Swedish Dialectology alphabet, and it's true, they have a long i that contrasts with the regular size i, and it's used to denote Viby-i. However I was lost afterwards, because if the glyphs are derived from the italic presentation for the i then it should have both a upper left and a lower right hook. This would explain neatly the appearance of 0285, but doesn't explain 027F. Does that letter simply not have an analogue the original Swedish alphabet and was invented by Sinologists (basically having the top half take the properties of a serif font and the bottom half the hook of an italic presentation)? If the bottom hook of 0285 (called a tail here) is meant to contrast with a straight appearance of the letter then shouldn't 027F lack an upper hook as well (making it the same letter intended for Viby-i)? After much tough I believe I have come up with a much clearer notation regarding these characters For 027F I propose: Sinologists often used characters borrowed by Karlgren from the Swedish Dialect Alphabet (Landsmålsalfabetet) for the representation of apical vowels. 027F ɿ and 0285 ʅ are two contrasting versions derived from the same long, italic, dotless i (originally used to denote Viby-i), but over time took on their own identity. This character’s name is misleading as it’s not actually related to 027E ɾ Given this, the other note stating: • this character is not actually a reversed 027E ɾ is made redundant and can be removed I would also change the informative alias from: long i with left hook to long dotless i with upper left hook. The proposed name makes me think of a tall dotted i with a hook opening left below the baseline For 0285 I propose: The lower hook on this character ultimately derives from the hooked terminal stroke of a long, italic, dotless i, but its use for an apical retroflex vowel, has led to its reanalysis as a retroflex hook. Name is misleading as it’s not actually related to 0283 ʃ Similarly, the other note stating: • this character is not actually a reversed esh is made redundant and can be removed. I would also change the informative alias from: long i with left hook and tail to long dotless i with upper left and lower right hooks. The proposed name makes me think of the same character I described previously with an added wavy stroke coming from near the bottom of the shaft. Having said this, it should be now clear that despite being historically related neither of these characters should be used to represent the symbol used by the Landsmålsalfabete to represent Viby-i. As we can see, in the original Swedish context, the presence of the hooks was merely part of the typography and not used for contrast with non-hooked symbols (presumably, changing typography to non-italic sans-serif would have rendered the symbol without either hook), while in Sinology, omitting just one of the hooks means something different and omitting both hooks is meaningless. Therefore that character should be encoded separately as LATIN SMALL LETTER LONG DOTLESS I, it would be confusable with A781 LATIN SMALL LETTER TURNED L, but cannot be unified with that either for what should be obvious reasons.
Date/Time: Mon June 23 03:59:55 PDT 2025
ReportID: ID20250623035955
Name: Eduardo [Larry] Marín Silva
Report Type: Public Review Issue
Opt Subject: A couple of corrections on my previous feedback
[SEW]
I noticed just a couple of things I could have done better. Instead of writing "Swedish Dialect Alphabet" I could have written "Swedish Dialectology Alphabet". But most importantly I neglected to make similar adjustment related to 02AE & 02AF The note under the header would read: These characters are derived from two contrastive versions of the same italic turned h that was borrowed by Karlgren from the Swedish Dialectology Alphabet (Landsmålsalfabetet), but over time took on their own identity. 02AE would get a cross reference to 0265 ɥ latin small letter turned h and the informative alias would change to turned h with upper left hook (see below for an explanation of this change) I would also change the informative alias of 02AF from turned h with left hook and tail to turned h with upper left and lower right hooks. So now all four characters have aliases and descriptions that harmonize with each other AND are clearer to understand. Once again the distinction of a "tail" and a "left hook" is ambiguous in this context. It's better to talk of both elements being hooks and describe their position on the character.
Date/Time: Wed June 25 07:04:13 PDT 2025
ReportID: ID20250625070413
Name: Marc Lodewijck
Report Type: Public Review Issue
Opt Subject: Suggested reclassification of U+16D98 C [EDC]
In the current draft of NamesList.txt, U+16D98 CHISOI SIGN ANUSVARA appears within the "Letters" section of the Chisoi block. However, this character is not a letter; it is a combining mark used to indicate nasalization. To reflect its actual function and to align with established editorial conventions, I suggest moving U+16D98 into a separate section. Proposed revision: @ Letters 16D80 CHISOI LETTER A 16D81 CHISOI LETTER BA ... 16D97 CHISOI LETTER PA @ Nasalization sign 16D98 CHISOI SIGN ANUSVARA @ Letters 16D99 CHISOI LETTER YA
Date/Time: Sun June 29 11:56:05 PDT 2025
ReportID: ID20250629115605
Name: Marc Lodewijck
Report Type: Public Review Issue
Opt Subject: PRI #526: corrections to section titles [EDC]
In the NamesList.txt file, within the Egyptian Hieroglyphs Extended-A block (U+13460–U+143FF), the following section titles must be corrected. D08. Eye oudjat → D08. Udjat eye Eye oudjat → Udjat eye — “oudjat” must be corrected to “udjat”, and word order adjusted. D09. Eye oudjat components → D09. Udjat eye components Eye oudjat → Udjat eye — “oudjat” must be corrected to “udjat”, with word order adjusted accordingly. F09. Donkey and horse protome → F09. Donkey and horse protomes protome → protomes — plural is required. N03. Sun with Uraeus → N03. Sun with uraeus Uraeus → uraeus — lowercase is required. O11. Double platform (sed festival) → O11. Double platform (sed-festival) sed festival → sed-festival — hyphenation aligns with 15 occurrences of “sed-festival” in Unikemet.txt, and no instance of “sed festival”. T15. Reed float (Object db.) → ? T15. Reed float Please verify whether “(Object db.)” should be included in this section title, as it may be inappropriate.
Date/Time: Sun June 29 12:42:18 PDT 2025
ReportID: ID20250629124218
Name: Marc Lodewijck
Report Type: Public Review Issue
Opt Subject: PRI #526: ISO/IEC 14651 CTT_V17_0 [PAG]
A few corrections are needed in the draft ISO/IEC 14651 Common Template Table (CTT_V17_0), specifically in the section describing how to compute implicit weights for siniform ideographic characters or any code point not explicitly mentioned in the CTT. The following subsections require updates. 1. Han unified ideographs The 12 unified Han characters in the CJK compatibility area should be explicitly listed, as currently only mentioned but not covered by any code range. There is also an inconsistent wording in the comment for WEIGHT_BASE: it currently states “Extension A through Extension I”, but the ranges actually include Extension J as well. % Weights for unified Han characters follow the Unified Repertoire and % Ordering, which is a language-neutral, traditional radical-stroke order. % The original URO and Extensions A through J, plus the 12 unified Han characters % in the CJK compatibility area are weighted implicitly as defined here. % WEIGHT_BASE = 0xFB40 for original URO and 12 unified Han from CJK compat area. % cp >= 0x04E00 && cp <= 0x09FFF % URO + % cp == 0x0FA0E % CJK compatibility character + % cp == 0x0FA0F % CJK compatibility character + % cp == 0x0FA11 % CJK compatibility character + % cp == 0x0FA13 % CJK compatibility character + % cp == 0x0FA14 % CJK compatibility character + % cp == 0x0FA1F % CJK compatibility character + % cp == 0x0FA21 % CJK compatibility character + % cp == 0x0FA23 % CJK compatibility character + % cp == 0x0FA24 % CJK compatibility character + % cp >= 0x0FA27 && cp <= 0x0FA29 % CJK compatibility characters - % WEIGHT_BASE = 0xFB80 for Extension A through Extension I Han characters. + % WEIGHT_BASE = 0xFB80 for Extension A through Extension J Han characters. % cp >= 0x03400 && cp <= 0x04DBF % Ext. A % cp >= 0x20000 && cp <= 0x2A6DF % Ext. B % cp >= 0x2A700 && cp <= 0x2B73F % Ext. C % cp >= 0x2B740 && cp <= 0x2B81D % Ext. D % cp >= 0x2B820 && cp <= 0x2CEAD % Ext. E % cp >= 0x2CEB0 && cp <= 0x2EBE0 % Ext. F % cp >= 0x2EBF0 && cp <= 0x2EE5D % Ext. I % cp >= 0x30000 && cp <= 0x3134A % Ext. G % cp >= 0x31350 && cp <= 0x323AF % Ext. H % cp >= 0x323B0 && cp <= 0x33479 % Ext. J % For a given Han character at code point cp: % base1 = WEIGHT_BASE + ( cp >> 15 ) % base2 = ( cp & 0x7FFF ) 0x8000 % Then weight the character as: "";;; 2. Tangut ideographs Minor clarification: the current comment labels (“Tangut ideographs” and “Tangut ideograph supplement”) do not match the Unicode block names. These should be corrected to “Tangut” and “Tangut Supplement”. % Tangut ideographic characters are weighted implicitly as defined here. % WEIGHT_BASE = 0xFB00 - % cp >= 0x17000 && cp <= 0x187FF % Tangut ideographs - % cp >= 0x18D00 && cp <= 0x18D1E % Tangut ideograph supplement + % cp >= 0x17000 && cp <= 0x187FF % Tangut + % cp >= 0x18D00 && cp =< 0x18D1E % Tangut Supplement % For a given Tangut character at code point cp: % base1 = WEIGHT_BASE % base2 = ( cp - 0x17000 ) 0x8000 % Then weight the character as: "";;; 3. Tangut component characters Minor comment label adjustment: the current comment labels (“Tangut components” and “Tangut component supplement”) differ slightly from the Unicode block names, notably in casing. These should be updated to match exactly: “Tangut Components” and “Tangut Components Supplement”. Range boundary update: the upper bound for “Tangut Components Supplement” should be 0x18DF2, as the remaining code points in the block are currently unassigned. Offset correction: the expression for base2 mistakenly uses 0x17000 as the starting point. This should be corrected to 0x18800, which is the beginning of the “Tangut Components” block. % Tangut component characters are weighted implicitly as defined here. % WEIGHT_BASE = 0xFB01 - % cp >= 0x18800 && cp <= 0x18AFF % Tangut components - % cp >= 0x18D80 && cp <= 0x18DFF % Tangut component supplement + % cp >= 0x18800 && cp <= 0x18AFF % Tangut Components + % cp >= 0x18D80 && cp <= 0x18DF2 % Tangut Components Supplement % For a given Tangut character at code point cp: % base1 = WEIGHT_BASE - % base2 = ( cp - 0x17000 ) 0x8000 + % base2 = ( cp - 0x18800 ) 0x8000 % Then weight the character as: "";;; % Nushu ideographic characters are weighted implicitly as defined here. 4. Khitan Small Script ideographs A separate line should be introduced for the character U+18CFF, which is part of the “Khitan Small Script” block but lies outside the main contiguous range. This ensures that it is explicitly included in the weighting logic. % Khitan Small Script ideographic characters are weighted implicitly as defined here. % WEIGHT_BASE = 0xFB03 % cp >= 0x18B00 && cp <= 0x18CD5 % Khitan Small Script + % cp == 0x18CFF % Khitan Small Script % For a given Khitan Small Script character at code point cp: % base1 = WEIGHT_BASE % base2 = ( cp - 0x18B00 ) 0x8000 % Then weight the character as: "";;; No changes are required for the Nüshu ideographic characters section; the existing definitions are accurate and complete.
Date/Time: Mon June 30 17:11:53 PDT 2025
ReportID: ID20250630171153
Name: Pentsok W Rtsang
Report Type: Public Review Issue
Opt Subject: U+0F0E ༎ TIBETAN MARK NYIS SHAD and other feedback [SEW]
I am making a comment on the PRI #526 concerning the discussion about the double shad in Tibetan: U+0F0E ༎ TIBETAN MARK NYIS SHAD, the core specs revision, improving the names of the characters, and fixing typos in the transliteration. The double shad is key for any number of pairs of double shad, such as the quadrople, sexdecuple (6x), octuple (8x), duodecuple (12x), and even sexdecuple (16x) shad (observed in a old manuscripts). Since they are just repeated double-shad with desired spaces, sometimes with punctuation marks or words in between them. Without a double shad with proper spacing, the use of the single shad to typeset large texts gets messy and chaotic, because of the bigger space that is needed before the next sentence. In sum, the double shad should have a little bit of space between them, but the space should be less than a normal space to have the necessary contrast with a normal space. That said, this is not a simple problem, as it seems to be related to many other issues. For example, the lack of a strong grammar, language, publishing, and typesetting policy enforcement for Tibetan, as there is in Bhutan: DDC. Regarding Tibetan Punctuation. Statements such as "The punctuation apparatus of Tibetan is relatively limited" should be removed, as the punctuation apparatus of Tibetan is more diverse and abundant than that of English. However, in my opinion, the follwing statemnets about the double shad should be kept: "Two shays are used at the end of whole topics (“don-tshan”); the double shay has been coded at U+0F0E with the intent that it would have a larger spacing between component shays than if two shays were simply written together" and "Additionally, font designers will have to decide whether to implement these shays with a larger than normal gap". I tested all the publicly released Tibetan Unicode fonts in the world (300+ currently) and identified the following 15 fonts that have been explicitly designed with more space between the two shad for the double shad character U+0F0E, while the rest of the fonts have no space between the two shad for the double shad. I think this has to do with the default samples of Kailasa, Kokonor, and Microsoft Himalaya that the type designers use as models to design their fonts, rather than making their own conscious decisions about the spacing for the double shad. I guess this is also why this discussion is happening. But regarding the double shad, I want to point out its usage in Tibetan, while also using the text to illustrate some points about typesetting differences between the use of two singles shad to form a double shad and using the actual double shad character.The most fundamental rules for using the double shad are from the Commentaries on the Treatises on Tibetan Grammar in Thirty Verses (Sum cu pa) by G.Yang can grub pa'i dro rje, which is the easiest to understand and is being taught in Tibetan textbooks in compulsury education stage. Below is the passage that concerns the use of shad, I added the last shad-s as though it is the end of a chapter to illustrate the use of the quadrople shad: ལྷུག་པའི་དོན་མང་མིང་མཚམས་དང་། །དོན་འབྲིང་འབྱེད་དང་དོན་ཉུང་རྫོགས། །ཚིགས་བཅད་ག་མཐར་ཆིག་ཤད་བྱ། །རྫོགས་ཚིག་མཐའ་ཅན་ལྷུག་པ་དང་། །ཚིགས་བཅད་རྐང་མཐར་ཉིས་ཤད་འཐོབ། །དོན་ཚན་ཆེན་མོ་རྫོགས་པ་དང་། །ལེའུའི་མཚམས་སུ་བཞི་ཤད་དགོས། །ང་ཡིག་མ་གཏོགས་ཡིག་ཤད་དབར། །ཚེག་མེད་དེ་སོགས་ཞིབ་ཏུ་འབད། ། ། ། (this text here is typeset with the single shad character U+0F0D followed by a space, and then repeating the single shad again to form the double shad for the reader. But as you can see at the end, if this is to be implemented consistantly in publications, it reqiures the editors and typesetters to put at least 4 spaces between the double shad to form a quadruple shad, which would get inconsistant and messy. And most writers and general readers do not look at the details of the spaces.) The following is my translation: A single shad is used, in prose with multiple topics: to delimit nouns, indicate the end of medium-and short-length topics, and the consonant ག in verses (+ letters ཀ and ཤ). A double shad is used at the end of terminative particles (includes, གོ་ངོ་ཏོ་ནོ་བོ་མོ་འོ་རོ་ལོ་སོ།) in prose and the ends of lines in verses. A quadrople shad is used at the end of a long topic or chapter. There is no tseg before shad, except for nga ང་, so be aware of cases such as da ད. Just to provide an example of the different typesetting practices using a double shad, the above Tibetan text can alternatively be typeset as below, which is typeset with the double shad character U+0F0E, followed by a space: ལྷུག་པའི་དོན་མང་མིང་མཚམས་དང་༎ དོན་འབྲིང་འབྱེད་དང་དོན་ཉུང་རྫོགས༎ ཚིགས་བཅད་ག་མཐར་ཆིག་ཤད་བྱ༎ རྫོགས་ཚིག་མཐའ་ཅན་ལྷུག་པ་དང་༎ ཚིགས་བཅད་རྐང་མཐར་ཉིས་ཤད་འཐོབ༎ དོན་ཚན་ཆེན་མོ་རྫོགས་པ་དང་༎ ལེའུའི་མཚམས་སུ་བཞི་ཤད་དགོས༎ ང་ཡིག་མ་གཏོགས་ཡིག་ཤད་དབར༎ ཚེག་མེད་དེ་སོགས་ཞིབ་ཏུ་འབད༎ ༎ In my opinion, the double shad should have more space than it currently has on Kailasa and Kokonor, but LESS than a normal space (so, I guess half a space?), to have the necessary contrast with the full space before the next sentence begins. This would make it easier to be consistent, and the use of one space can be implemented for both after single shad-s and between double shad-s.
Date/Time: Mon June 30 20:22:56 PDT 2025
ReportID: ID20250630202256
Name: Pentsok W Rtsang
Report Type: Public Review Issue
Opt Subject: Typos in the names for Tibetan characters or error [SEW]
There seem to be many typos in the names for Tibetan characters or errors when the Tibetan names the characters are transliterated into Roman letters,
as below:
GTER YIG MGO (0F01-3) should be "GTER YIG GI YIG MGO", because "GTER YIG MGO" would mean "the head of GTER YIG", whereas "GTER YIG GI YIG MGO" would
actually mean "head marks/initial signs for gter yig (hidden treasure texts or revealed texts)". It can also be shortened to "gter yig yig mgo", but
the part of the name for gter yig cannot be deleted.
SGAB MA as in "yig mgo sgab ma" should be "འགབ་མ། 'gab ma", because there is no such word as "སྒབ་མ། sgab ma". It seems to be a common typo for transliterating
Tibetan into Wylie, for the prefix 'a is mistaken for the superscript sa. I couldn't find such a word in Dzongkha either. According to the names for the
Tibetan unicode characters, the small letter 'a is transliterated as "-", in this case, it would be "-GAB MA", instead of "SGAB MA". But, the name for
this part of the Uchud (དབུ་ཁྱུད། dbu khyud), might be better called "Yig mgo rjes ma" or "Yig mgo rgyab ma", as this would mean "the latter part of the initial
sign" whereas " 'gab ma" is "lower one". These two would make the most sense, especially the latter one since, the words mdun and rgyab are direct
antonyms. So, U+0F04 is the front part and U+0F05 is the latter part. Whereas one is front (mdun) and the other being lower ('gab), is illogical as well.
But the encoding of Uchud (this sign: ༄༅།།) into two parts (actually three parts, counting the shad as separate characters) is quite genius, as Tibetans do
not think of them as two parts, but they almost always come together as one initial mark. The reason is that in old texts and manuscripts from ~13th
century until before the pre-modern era, this initial sign had more of the latter part of like this: ༄༅༅།།. Although most people no longer use this
elaboration, it is, of course, necessary to have the function to type this way. But the most elaborate Uchud I have ever seen is as follows, it would be
great if these historical variations can also be encoded:
The “Translated Words (of the Buddha)”, part of the Tibetan Buddhist Canon, original manuscript from Namgyal Monastery in Mustang, Nepal. In the
Collection of Ancient Tibetan Manuscripts from Namgyal Monastery, BDRC, MW2KG229028, vol. 7, img. 3.
Yet, the initial signs are much simpler and completely different for Umed scripts, which would be another topic.
The name for 0FC6, "PADMA GDAN", needs a connecting particle known as 'brel sgra, which would be "PADMA'i GDAN", if the small letter 'a is represented
as "-", then it would be "PADMA-i GDAN". Otherwise, "PADMA GDAN" would be two separate things, "Lotus, mattress", instead of "lotus mattress" as in
English.
For the religious symbols 0FD5-8, the names should be consistent and match the translations as "G.YAS 'KHOR" (right-facing) for "nang -khor"
(inward-facing) and "G.YON 'KHOR" (left-facing) for "phyi -khor" (outward-facing), as other names are, such as 0F3A-D "GUG RTAGS GYAS" and "GUG RTAGS
GYON". But if the transliteration is following the Wylie system, they should be "G.YAS" and "G.YON", unless it messes up some encoding or something,
but I assume they should be fine for the names.
Date/Time: Mon June 30 11:22:05 PDT 2025
ReportID: ID20250630112205
Name: Marc Lodewijck
Report Type: Public Review Issue
Opt Subject: [PRI #526] Reclassification of U+1E6E3 and U+1E6E6 [EDC]
In the current draft of NamesList.txt, two rime signs in the “Tai Yo” block — U+1E6E3 TAI YO SIGN UE and U+1E6E6 TAI YO SIGN AU — are listed under the “Vowels” section. However, according to section 3.2.4 (“Rime signs”) of the Tai Yo script proposal, these are not vowel letters but distinct rime components. Would it not be more accurate to list them under separate “Rime sign” headings, rather than grouping them with vowels, to better reflect their function? Suggested revision: @ Vowels 1E6E0 TAI YO LETTER AA 1E6E1 TAI YO LETTER I 1E6E2 TAI YO LETTER UE +@ Rime sign 1E6E3 TAI YO SIGN UE +@ Vowels 1E6E4 TAI YO LETTER U 1E6E5 TAI YO LETTER AE +@ Rime sign 1E6E6 TAI YO SIGN AU +@ Vowels 1E6E7 TAI YO LETTER O 1E6E8 TAI YO LETTER E 1E6E9 TAI YO LETTER IA 1E6EA TAI YO LETTER UEA 1E6EB TAI YO LETTER UA 1E6EC TAI YO LETTER OO 1E6ED TAI YO LETTER AUE The “Finals” section, by contrast, is consistent and appropriate: all characters listed there serve final (coda) functions, regardless of whether they are represented as letters or signs. Therefore, no further subdivision is needed in that section.
Date/Time: Tue July 01 19:42:15 PDT 2025
ReportID: ID20250701194215
Name: Erik Carvalhal Miller
Report Type: Public Review Issue
Opt Subject: PRI 526 Unicode 17.0.0 Beta: Core Spec §6.2.4 [EDC]
Core Spec §6.2.4 “Dashes and Hyphens” ¶1 says, ‘U+2010 ‐ HYPHEN represents the hyphen as found in words such as “left-to-right.” ’; however, the example is confusing and false, since both hyphens are actually instances of U+002D HYPHEN-MINUS (as are, indeed, most of the hyphens in that chapter and throughout the Core Spec generally). Please revise accordingly.
Date/Time: Tue July 01 20:24:31 PDT 2025
ReportID: ID20250701202431
Name: Erik Carvalhal Miller
Report Type: Public Review Issue
Opt Subject: PRI 526 Unicode 17.0.0 Beta: Core Spec ch. 6 [EDC]
Core Spec chapter 6 “Writing Systems and Punctuation” > introductory section > ¶2 headed “Scripts and Blocks”: In the sentence beginning, “Discussion of scripts and other groups of characters are[…]”, “are” → “is” (for subject–verb agreement).
Date/Time: Tue July 01 20:38:52 PDT 2025
ReportID: ID20250701203852
Name: Erik Carvalhal Miller
Report Type: Public Review Issue
Opt Subject: PRI 526 Unicode 17.0.0 Beta: Core Spec chapter 6 [EDC]
Core Spec §6.1 “Writing Systems” > introductory section > paragraph headed “Abjads”: The first sentence — “A writing system in which only consonants are indicated is an abjad.” — is contradicted by the following sentence at the phrases “or long vowels” and “or optionally indicated[…]”. Possible revision: change first sentence to “A writing system which indicates only or primarily consonants is an abjad.”
Date/Time: Tue July 01 20:59:12 PDT 2025
ReportID: ID20250701205912
Name: Erik Carvalhal Miller
Report Type: Public Review Issue
Opt Subject: PRI 526 Unicode 17.0.0 Beta: Core Spec §6.1 [EDC]
Core Spec §6.1 “Writing Systems” > introductory section > 1st paragraph following paragraph headed “Syllabaries”: The first sentence, beginning, “In syllabaries such as Cherokee, Hiragana, Katakana, and Yi[…]”, has awkward mixing of singular and plural, whereas the use of each suggests singular only. Suggested revision: “any of the consonant(s) or vowels of the syllables” → “any consonant or vowel of the syllable”.
Date/Time: Tue July 01 23:51:41 PDT 2025
ReportID: ID20250701235141
Name: Erik Carvalhal Miller
Report Type: Public Review Issue
Opt Subject: PRI 526 Unicode 17.0.0 Beta: Core Spec §5.21.6 [EDC]
Core Spec §5.21.6 “Characters Ignored for Display” > 3rd paragraph, headed by “Normal Rendering”: In second sentence, “dotted box” → “dashed box”. for consistency with the description of the “Dashed Box Convention” described in §24.1.2 “Special Characters and Code Points”, as well as accuracy (for the representations thus described and used throughout Unicode Standard documentation indeed do have borders made up of dashes, i.e., lines like “- - -”, and not of dots, i.e., circles or squares like “· · ·”).
Date/Time: Tue July 08 19:17:26 PDT 2025
ReportID: ID20250708191726
Name: Erik Carvalhal Miller
Report Type: Public Review Issue
Opt Subject: PRI 526⁓Unicode 17.0.0 Beta: Core Spec Table 4-10 [EDC]
Chapter 4ʼs table 4-10 (“Unusual Properties”) has not been updated to reflect additional ideographic description characters encoded in v15.1; row “Ideographic description” should list 2FF0‥2FFF & 31EF (instead of just 2FF0‥2FFB).
Date/Time: Mon July 14 14:33:51 PDT 2025
ReportID: ID20250714143351
Name: Mark David
Report Type: Public Review Issue
Opt Subject: Incorrect Glyph in UnicodeChart for U+FB30 H [CHARTS]
In chart for FBxx the glyph shown for U+FB30 is wrong. The diacritic component of this precomposed character (equivalent to U+05BC [ּ] HEBREW_POINT_DAGESH_OR_MAPIQ) is a dot always intended to be placed somewhere in the middle of its base character above the baseline. However, in the glyph for this Unicode 16.0 chart, it is placed below the baseline and horizontally centered, such that it looks exactly like the diacritic U+05B4 [ִ] HEBREW_POINT_HIRIQ, which is wrong. Here's an image of how it looks in Unicode 16.0 chart with URL https://www.unicode.org/charts/PDF/UFB00.pdf. Notice the dot is below the baseline (which coincides with the bottom of the alef base character).Here's how it looks in a typical font, Noto Sans, Regular weight, as rendered in FontBook. Notice the dot is above the baseline.