| Version | Unicode 3.2.0 |
| Authors | Mark Davis (mark.davis@us.ibm.com), Martin Dürst (duerst@w3.org) |
| Date | 2002-03-26 |
| This Version | http://www.unicode.org/unicode/reports/tr15/tr15-22.html |
| Previous Version | http://www.unicode.org/unicode/reports/tr15/tr15-21.html |
| Latest Version | http://www.unicode.org/unicode/reports/tr15 |
| Tracking Number | 22 |
This document describes specifications for four normalized forms of Unicode text. With these forms, equivalent text (canonical or compatibility) will have identical binary representations. When implementations keep strings in a normalized form, they can be assured that equivalent strings have a unique binary representation.
Note: Unicode 3.1 and Unicode 3.2 introduced changes that may affect backwards compatibility for some implementations; for details see Annex 12: Corrigenda.
This document has been reviewed by Unicode members and other interested parties, and has been approved by the Unicode Technical Committee as a Unicode Standard Annex. It is a stable document and may be used as reference material or cited as a normative reference from another document.
A Unicode Standard Annex (UAX) forms an integral part of the Unicode Standard, but is published as a separate document. Note that conformance to a version of the Unicode Standard includes conformance to its Unicode Standard Annexes. The version number of a UAX document corresponds to the version number of the Unicode Standard at the last point that the UAX document was updated.
A list of current Unicode Technical Reports is found on http://www.unicode.org/unicode/reports/. For more information about versions of the Unicode Standard, see http://www.unicode.org/unicode/standard/versions/.
The References provide related information that is useful in understanding this document. Please mail corrigenda and other comments to the author(s).
The Unicode Standard defines two equivalences between characters: canonical equivalence and compatibility equivalence. Canonical equivalence is a basic equivalency between characters or sequences of characters. The following figure illustrates this equivalence:
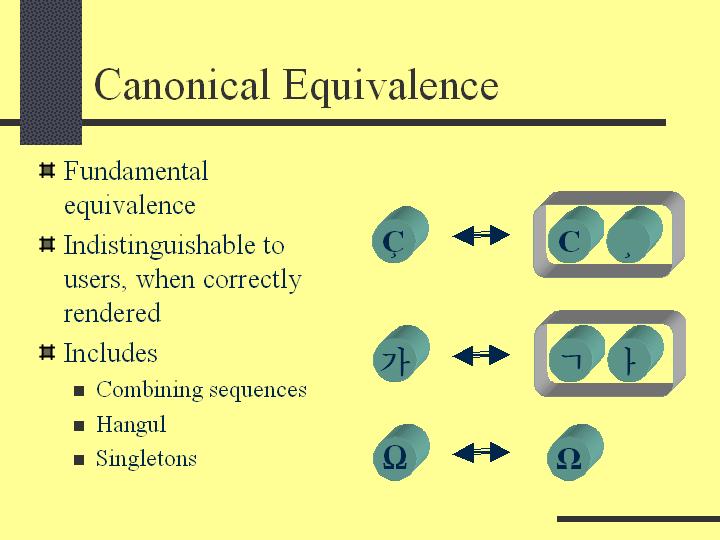
For round-trip compatibility with existing standards, Unicode has encoded many entities that are really variants of existing nominal characters. The visual representations of these character are typically a subset of the possible visual representations of the nominal character. These are given compatibility decompositions in the standard. Because the characters are visually distinguished, replacing a character by a compatibility equivalent may lose formatting information unless supplemented by markup or styling. See the figure below for examples of compatibility equivalents:

Both canonical and compatibility equivalences are explained in more detail in The Unicode Standard, Chapters 2 and 3. In addition, the Unicode Standard describes several forms of normalization in Section 5.7 (Section 5.9 in Version 2.0). These normalization forms are designed to produce a unique normalized form for any given string. Two of these forms are precisely specified in Section 3.6. In particular, the standard defines a canonical decomposition format, which can be used as a normalization for interchanging text. This format allows for binary comparison while maintaining canonical equivalence with the original unnormalized text.
The standard also defines a compatibility decomposition format, which allows for binary comparison while maintaining compatibility equivalence with the original unnormalized text. The latter can also be useful in many circumstances, since it levels the differences between characters which are inappropriate in those circumstances. For example, the half-width and full-width katakana characters will have the same compatibility decomposition and are thus compatibility equivalents; however, they are not canonical equivalents.
Both of these formats are normalizations to decomposed characters. While Section 3.6 also discusses normalization to composite characters (also known as decomposible or precomposed characters), it does not precisely specify a format. Because of the nature of the precomposed forms in the Unicode Standard, there is more than one possible specification for a normalized form with composite characters. This document provides a unique specification for normalization, and a label for each normalized form.
The four normalization forms are labeled as follows.
|
Title |
Description |
Specification |
|---|---|---|
| Normalization Form D (NFD) | Canonical Decomposition | Sections 3.6, 3.10, and 3.11 of The Unicode Standard, also summarized under Annex 4: Decomposition |
| Normalization Form C (NFC) | Canonical Decomposition, followed by Canonical Composition |
see §5 Specification |
| Normalization Form KD (NFKD) | Compatibility Decomposition | Sections 3.6, 3.10, and 3.11 of The Unicode Standard, also summarized under Annex 4: Decomposition |
| Normalization Form KC (NFKC) | Compatibility Decomposition, followed by Canonical Composition |
see §5 Specification |
As with decomposition, there are two forms of normalization to composite characters, Normalization Form C and Normalization Form KC. The difference between these depends on whether the resulting text is to be a canonical equivalent to the original unnormalized text, or is to be a compatibility equivalent to the original unnormalized text. (In NFKC and NFKD, a K is used to stand for compatibility to avoid confusion with the C standing for canonical.) Both types of normalization can be useful in different circumstances.
The following diagram illustrates the effect of applying different normalization forms to denormalized text. In the diagram, glyphs are colored according to the characters they represent (this will not be visible in black & white printouts).
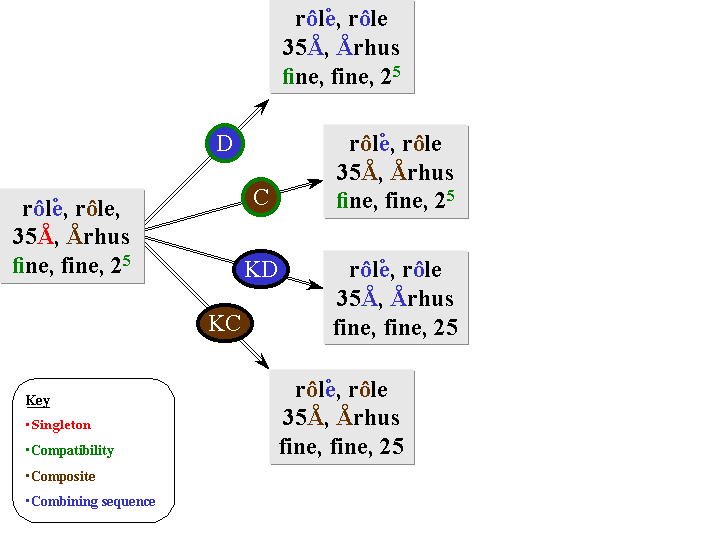
With all normalization forms, singleton characters (those with singleton canonical mappings) are replaced. With NFD and NFC, compatibility composites (characters with compatibility decompositions) are retained; with NFKD and NFKC they are replaced. Notice that this is sometimes loses significant information, unless supplemented by markup or styling.
With NFD and NFKD, composite characters are mapped to their canonical decompositions. With NFC and NFKC, combining character sequences are mapped to composites, if possible. Notice that since there is no composite for e-ring, so it is left decomposed in NFC and NFKC.
All of the definitions in this document depend on the rules for equivalence and decomposition found in Chapter 3 of The Unicode Standard and the decomposition mappings in the Unicode Character Database.
Note: Text containing only ASCII characters (U+0000 to U+007F) is left unaffected by all of the normalization forms. This is particularly important for programming languages (see Annex 7: Programming Language Identifiers).
Normalization Form C uses canonical composite characters where possible, and maintains the distinction between characters that are compatibility equivalents. Typical strings of composite accented Unicode characters are already in Normalization Form C. Implementations of Unicode which restrict themselves to a repertoire containing no combining marks (such as those that declare themselves to be implementations at Level 1 as defined in ISO/IEC 10646-1) are already typically using Normalization Form C. (Implementations of later versions of 10646 need to be aware of the versioning issues — see §3 Versioning and Stability.)
The W3C Character Model for the World Wide Web [CharMod] uses Normalization Form C for XML and related standards (this document is not yet final, but this requirement is not expected to change). See the W3C Requirements for String Identity, Matching, and String Indexing [CharReq] for more background.
Normalization Form KC additionally levels the differences between compatibility-equivalent characters which are inappropriately distinguished in many circumstances. For example, the half-width and full-width katakana characters will normalize to the same strings, as will Roman Numerals and their letter equivalents. More complete examples are provided in Annex 1: Examples and Charts.
Normalization forms KC and KD must not be blindly applied to arbitrary text. Since they erase many formatting distinctions, they will prevent round-trip conversion to and from many legacy character sets, and unless supplanted by formatting markup, may remove distinctions that are important to the semantics of the text. The best way to think of these normalization forms is like uppercase or lowercase mappings: useful in certain contexts for identifying core meanings, but also performing modifications to the text that may not always be appropriate. They can be applied more freely to domains with restricted character sets, such as in Annex 7: Programming Language Identifiers.
To summarize the treatment of compatibility composites that were in the source text:
Note: Normalization Form KC does not attempt to map character sequences to compatibility composites. For example, a compatibility composition of "office" does not produce "o\uFB03ce", even though "\uFB03" is a character that is the compatibility equivalent of the sequence of three characters 'ffi'.
None of the normalization forms are closed under string concatenation. Consider the following examples:
| Form | String1 | String2 | Concatenation | Correct Normalization |
|---|---|---|---|---|
| NFC | "a" | "^" | "a"+"^" | "â" |
| NFD | "a"+"^" | "." (dot under) | "a"+"^" + "." | "a" + "." +"^" |
Without limiting the repertoire, there is no way to produce a normalized form that is closed under simple string concatenation. If desired, however, a specialized function could be constructed that produced a normalized concatenation. However, all of the normalization forms are closed under substringing.
All of the definitions in this document depend on the rules for equivalence and decomposition found in Chapter 3 of The Unicode Standard and the Character Decomposition Mapping and Canonical Combining Class property in [UCD]. Decomposition must be done in accordance with these rules. In particular, the decomposition mappings found in the Unicode Character Database must be applied recursively, and then the string put into canonical order based on the characters' combining classes.
The following notation is used for brevity:
| E-grave | = | LATIN CAPITAL LETTER E WITH GRAVE | |
| ka | = | KATAKANA LETTER KA | |
| hw_ka | = | HALFWIDTH KATAKANA LETTER KA | |
| ten | = | COMBINING KATAKANA-HIRAGANA VOICED SOUND MARK | |
| hw_ten | = | HALFWIDTH KATAKANA VOICED SOUND MARK |
It is crucial that normalization forms remain stable over time. That is, if a string (that does not have any unassigned characters) is normalized under one version of Unicode, it must remain normalized under all future versions of Unicode. This is the backwards compatibility requirement. To meet this requirement, a fixed version for the composition process is specified, called the composition version. The composition version is defined to be Version 3.1.0 of the Unicode Character Database. For more information, see:
To see what difference the composition version makes, suppose that Unicode 4.0 adds the composite Q-caron. For an implementation that uses Unicode 4.0, strings in Normalization Forms C or KC will continue to contain the sequence Q + caron, and not the new character Q-caron, since a canonical composition for Q-caron was not defined in the composition version. See §6 Composition Exclusion Table for more information.
Note: It would be possible to add more compositions in a future version of Unicode, as long as the backward compatibility requirement is met. That requires that for any new composition XY => Z, at most one of X or Y was defined in a previous version of Unicode. That is, Z must be a new character, and either X or Y must be a new character. However, the Unicode Consortium strongly discourages new compositions, even in such restricted cases.
In addition to fixing the composition version, future versions of Unicode must be restricted in terms of the kinds of changes that can be made to character properties. Because of this, the Unicode Consortium has a clear policy to guarantee the stability of normalization forms: for more information, see Unicode Policies [Policies].
C1. A process that produces Unicode text that purports to be in a Normalization Form shall do so in accordance with the specifications in this document.
C2. A process that tests Unicode text to determine whether it is in a Normalization Form shall do so in accordance with the specifications in this document.
C3. A process that purports to transform text into a Normalization Form, must be able to pass the conformance test described in Annex 9: Conformance Testing.
Note: The specifications for Normalization Forms are written in terms of a process for producing a decomposition or composition from an arbitrary Unicode string. This is a logical description — particular implementations can have more efficient mechanisms as long as they produce the same result. Similarly, testing for a particular Normalization Form does not require applying the process of normalization, so long as the result of the test is equivalent to applying normalization and then testing for binary identity.
This section specifies the format for Normalization Forms C and KC. It uses the following four definitions D1, D2, D3, D4, and two rules R1 and R2.
All combining character sequences start with a character of combining class zero. For simplicity, the following term is defined for such characters:
D1. A character S is a starter if it has a combining class of zero in the Unicode Character Database.
Because of the definition of canonical equivalence, the order of combining characters with the same combining class makes a difference. For example, a-macron-breve is not the same as a-breve-macron. Characters can not be composed if that would change the canonical order of the combining characters.
D2. In any character sequence beginning with a starter S, a character C is blocked from S if and only if there is some character B between S and C, and either B is a starter or it has the same combining class as C.
Note: When B blocks C, changing the order of B and C would result in a character sequence that is not canonically equivalent to the original. See Section 3.9 Canonical Ordering Behavior in the Unicode Standard.
Note: If a combining character sequence is in canonical order, then testing whether a character is blocked only requires looking at the immediately preceding character.
The process of forming a composition in Normalization Form C or KC involves:
Figure 1 shows a sample of how this works. The dark green cubes represent starters, and the light gray cubes represent non-starters. In the first step, the string is fully decomposed, and reordered. In the second step, each character is checked against the last non-starter, and combined if all the conditions are met. Examples are provided in Annex 1: Examples and Charts, and a code sample is provided in Annex 5: Code Sample.

Figure 1. Composition Process
A precise notion is required for when an unblocked character can be composed with a starter. This uses the following two definitions.
D3. A primary composite is a character that has a canonical decomposition mapping in the Unicode Character Database (or has a canonical Hangul decomposition) but is not in the §6 Composition Exclusion Table.
Note: Hangul syllable decomposition is considered a canonical decomposition. See The Unicode Standard, Version 3.0. Also see Annex 10: Hangul.
D4. A character X can be primary combined with a character Y if and only if there is a primary composite Z which is canonically equivalent to the sequence <X, Y>.
Based upon these definitions, the following rules specify the Normalization Forms C and KC.
The Normalization Form C for a string S is obtained by applying the following process, or any other process that leads to the same result:
The result of this process is a new string S' which is in Normalization Form C.
The Normalization Form KC for a string S is obtained by applying the following process, or any other process that leads to the same result:
The result of this process is a new string S' which is in Normalization Form KC.
There are four classes of characters that are excluded from composition.
Two characters may have the same canonical decomposition in the Unicode Character Database. Here is an example of this:
| Source | Same Decomposition |
|---|---|
| 212B 'Å' ANGSTROM SIGN |
0041 'A' LATIN CAPITAL LETTER A + 030A '°' COMBINING RING ABOVE |
| 00C5 'Å' LATIN CAPITAL LETTER A WITH RING ABOVE |
The Unicode Character Database will first decompose one of the characters to the other, and then decompose from there. That is, one of the characters (in this case ANGSTROM SIGN) will have a singleton decomposition. Characters with singleton decompositions are included in Unicode essentially for compatibility with certain pre-existing standards. These singleton decompositions are excluded from primary composition.
A machine-readable form data file is found in the Composition Exclusion Table [Exclusions].
All four classes of characters are included in this file, although the singletons and non-starter decompositions are commented out.
A derived property containing the complete list of exclusions,
Comp_Ex, is described in Derived Properties documentation [DerivedProps]. Implementations can avoid computing the singleton and non-starter decompositions from the Unicode Character Database by using theComp_Exproperty instead.
This annex provides some detailed examples of the results of applying each of the normalization forms. The Normalization Charts [Charts] provide also charts of all the characters in Unicode that differ from at least one of their normalization forms (NFC, NFD, NFKC, NFKD).
The following examples are cases where the NFD and NFKD are identical, and NFC and NFKC are identical.
| Original | NFD, NFKD | NFC, NFKC |
Notes |
|
|---|---|---|---|---|
| a | D-dot_above | D + dot_above | D-dot_above | Both decomposed and precomposed canonical sequences produce the same result. |
| b | D + dot_above | D + dot_above | D-dot_above | |
| c | D-dot_below + dot_above | D + dot_below + dot_above | D-dot_below + dot_above |
By the time we have gotten to dot_above, it cannot be combined with the base character. There may be intervening combining marks (see f), so long as the result of the combination is canonically equivalent. |
| d | D-dot_above + dot_below | D + dot_below + dot_above | D-dot_below + dot_above | |
| e | D + dot_above + dot_below | D + dot_below + dot_above | D-dot_below + dot_above | |
| f | D + dot_above + horn + dot_below | D + horn + dot_below + dot_above | D-dot_below + horn + dot_above | |
| g | E-macron-grave | E + macron + grave | E-macron-grave | Multiple combining characters are combined with the base character. |
| h | E-macron + grave | E + macron + grave | E-macron-grave | |
| i | E-grave + macron | E + grave + macron | E-grave + macron | Characters will not be combined if they would not be canonical equivalents because of their ordering. |
| j | angstrom_sign | A + ring | A-ring | Since Å (A-ring) is the preferred composite, it is the form produced for both characters. |
| k | A-ring | A + ring | A-ring |
The following are examples of NFD and NFC that illustrate how they differ from NFKD and NFKC, respectively.
| Original | NFD | NFC |
Notes |
|
|---|---|---|---|---|
| l | "Äffin" | "A\u0308ffin" | "Äffin" | The ffi_ligature (U+FB03) is not decomposed, since it has a compatibility mapping, not a canonical mapping. (See Normalization Forms KD and KC Examples.) |
| m | "Ä\uFB03n" | "A\u0308\uFB03n" | "Ä\uFB03n" | |
| n | "Henry IV" | "Henry IV" | "Henry IV" | Similarly, the ROMAN NUMERAL IV (U+2163) is not decomposed. |
| o | "Henry \u2163" | "Henry \u2163" | "Henry \u2163" | |
| p | ga | ka + ten | ga | Different compatibility equivalents of a single Japanese character will not result in the same string in NFC. |
| q | ka + ten | ka + ten | ga | |
| r | hw_ka + hw_ten | hw_ka + hw_ten | hw_ka + hw_ten | |
| s | ka + hw_ten | ka + hw_ten | ka + hw_ten | |
| t | hw_ka + ten | hw_ka + ten | hw_ka + ten | |
| u | kaks | ki + am + ksf | kaks |
Hangul syllables are maintained under normalization. |
The following are examples of NFKD and NFKC that illustrate how they differ from NF D and NFC, respectively.
| Original | NFKD | NFKC |
Notes |
|
|---|---|---|---|---|
| l' | "Äffin" | "A\u0308ffin" | "Äffin" | The ffi_ligature (U+FB03) is decomposed in NFKC (where it is not in NFC). |
| m' | "Ä\uFB03n" | "A\u0308\ffin" | "Äffin" | |
| n' | "Henry IV" | "Henry IV" | "Henry IV" | Similarly, the resulting strings here are identical in NFKC. |
| o' | "Henry \u2163" | "Henry IV" | "Henry IV" | |
| p' | ga | ka + ten | ga | Different compatibility equivalents of a single Japanese character will result in the same string in NFKC. |
| q' | ka + ten | ka + ten | ga | |
| r' | hw_ka + hw_ten | ka + ten | ga | |
| s' | ka + hw_ten | ka + ten | ga | |
| t' | hw_ka + ten | ka + ten | ga | |
| u' | kaks | ki + am + ksf | kaks |
Hangul syllables are maintained under normalization.* |
*In earlier versions of Unicode, jamo characters like ksf had compatibility mappings to kf + sf. These mappings were removed in Unicode 2.1.9 to ensure that Hangul syllables are maintained.)
The following are the design goals for the specification of the normalization forms, and are presented here for reference.
The first, and by far the most important, design goal for the normalization forms is uniqueness: two equivalent strings will have precisely the same normalized form. More explicitly,
The second major design goal for the normalization forms is stability of characters that are not involved in the composition or decomposition process.
Note: The only characters for which Goal 2.2 is not true are those in the §6 Composition Exclusion Table.
The third major design goal for the normalization forms is that it allow for efficient implementations.
There are a number of optimizations that can be made in programs that produce Normalization Form C. Rather than first decomposing the text fully, a quick check can be made on each character. If it is already in the proper precomposed form, then no work has to be done. Only if the current character is combining or in the §6 Composition Exclusion Table does a slower code path need to be invoked. (This code path will need to look at previous characters, back to the last starter. See Annex 8: Detecting Normalization Forms for more information.)
The majority of the cycles spent in doing composition is spent looking up the appropriate data. The data lookup for Normalization Form C can be very efficiently implemented, since it only has to look up pairs of characters, not arbitrary strings. First a multi-stage table (aka trie; see Chapter 5 of the Unicode Standard) is used to map a character c to a small integer i in a contiguous range from 0 to n. The code for doing this looks like:
i = data[index[c >> BLOCKSHIFT] + (c & BLOCKMASK)];
Then a pair of these small integers are simply mapped through a two-dimensional array to get a resulting value. This yields much better performance than a general-purpose string lookup in a hash table.
Since the Hangul compositions and decompositions are algorithmic, memory storage can be significantly reduced if the corresponding operations are done in code. See Annex 10: Hangul for more information.
Note: Any such optimizations must be carefully check to ensure that they still produce conformant results. In particular, the code must still be able to pass the test described in Annex 9: Conformance Testing.
For those reading this document without access to the Unicode Standard, the following summarizes the canonical decomposition process. For a complete discussion, see Sections 3.6 and 3.10 of the Unicode Standard.
Canonical decomposition is the process of taking a string, recursively replacing composite characters using the Unicode canonical decomposition mappings (including the algorithmic Hangul canonical decomposition mappings, see Annex 10: Hangul), and putting the result in canonical order.
Compatibility decomposition is the process of taking a string, replacing composite characters using both the Unicode canonical decomposition mappings and the Unicode compatibility decomposition mappings, and putting the result in canonical order.
A string is put into canonical order by repeatedly replacing any exchangeable pair by the pair in reversed order. When there are no remaining exchangeable pairs, then the string is in canonical order. Note that the replacements can be done in any order.
A sequence of two adjacent characters in a string is an exchangeable
pair if the combining class (from the Unicode Character Database) for the
first character is greater than the combining class for the second, and the
second is not a starter; that is, if combiningClass(first) >
combiningClass(second) > 0.
Examples of exchangeable pairs:
Sequence Combining classes Status <acute, cedilla> 230, 202 exchangeable, since 230 > 202 <a, acute> 0, 230 not exchangeable, since 0 <= 230 <diaeresis, acute> 230, 230 not exchangeable, since 230 <= 230 <acute, a> 230, 0 not exchangeable, since the second class is zero.
Example of decomposition:
- Take the string with the characters "ác´¸" (a-acute, c, acute, cedilla)
- The data file contains the following relevant information:
code; name; ... combining class; ... decomposition.0061;LATIN SMALL LETTER A;...0;... 0063;LATIN SMALL LETTER C;...0;... 00E1;LATIN SMALL LETTER A WITH ACUTE;...0;...0061 0301;... 0107;LATIN SMALL LETTER C WITH ACUTE;...0;...0063 0301;... 0301;COMBINING ACUTE ACCENT;...230;... 0327;COMBINING CEDILLA;...202;...- Applying the canonical decomposition mappings, we get "a´c´¸" (a, acute, c, acute, cedilla).
- This is because 00E1 (a-acute) has a canonical decomposition mapping to 0061 0301 (a, acute)
- Applying the canonical ordering, we get "a´c¸´" (a, acute, c, cedilla, acute).
- This is because cedilla has a lower combining class (202) than acute (230) does. The positions of 'a' and 'c' are not affected, since they are starters.
A code sample is available for the four different normalization forms. For clarity, this sample is not optimized. The implementations for NFKC and NFC transform a string in two passes: pass 1 decomposes, while pass 2 composes by successively composing each unblocked character with the last starter.
In some implementations, people may be working with streaming interfaces that read and write small amounts at a time. In those implementations, the text back to the last starter needs to be buffered. Whenever a second starter would be added to that buffer, the buffer can be flushed.
The sample is written in Java, though for accessibility it avoids the use of object-oriented techniques. For access to the code, and for a live demonstration, see Normalizer.html [Sample]. Equivalent Perl code is available on the W3C site [CharLint].
While the Normalization Forms are specified for Unicode text, they can also be extended to non-Unicode (legacy) character encodings. This is based on mapping the legacy character set strings to and from Unicode using definitions D5 and D6.
D5. An invertible transcoding T for a legacy character set L is a one-to-one mapping from characters encoded in L to characters in Unicode with an associated mapping T-1 such that for any string S in L, T-1(T(S)) = S.
Note: Typically there is a single accepted invertible transcoding for a given legacy character set. In in a few cases there may be multiple invertible transcodings: for example, Shift-JIS may have two different mappings used in different circumstances: one to preserve the '/' semantics of 2F16, and one to preserve the '¥' semantics.
Note: The character indexes in the legacy character set string may be very different than character indexes in the Unicode equivalent. For example, if a legacy string uses visual encoding for Hebrew, then its first character might be the last character in the Unicode string.
If you implement transcoders for legacy character sets, it is recommended that you ensure that the result is in Normalization Form C where possible. See UTR #22: Character Mapping Tables for more information.
D6. Given a string S encoded in L and an invertible transcoding T for L, the Normalization Form X of S under T is defined to be the result of mapping to Unicode, normalizing to Unicode Normalization Form X, and mapping back to the legacy character encoding, e.g., T-1(NFX(T(S))). Where there is a single accepted invertible transcoding for that character set, we can simply speak of the Normalization Form X of S.
Legacy character sets fall into three categories based on their normalization behavior with accepted transcoders.
This section discusses issues that must be taken into account when considering normalization of identifiers in programming languages or scripting languages. The Unicode Standard provides a recommended syntax for identifiers for programming languages that allow the use of non-ASCII languages in code. It is a natural extension of the identifier syntax used in C and other programming languages:
<identifier> ::= <identifier_start> ( <identifier_start> | <identifier_extend> )*
<identifier_start> ::= [{Lu}{Ll}{Lt}{Lm}{Lo}{Nl}]
<identifier_extend> ::= [{Mn}{Mc}{Nd}{Pc}{Cf}]
That is, the first character of an identifier can be an uppercase letter, lowercase letter, titlecase letter, modifier letter, other letter, or letter number. The subsequent characters of an identifier can be any of those, plus non-spacing marks, spacing combining marks, decimal numbers, connector punctuations, and formatting codes (such as right-left-mark). Normally the formatting codes should be filtered out before storing or comparing identifiers.
Normalization as described in this report can be used to avoid problems where apparently identical identifiers are not treated equivalently. Such problems can appear both during compilation and during linking, in particular also across different programming languages. To avoid such problems, programming languages can normalize identifiers before storing or comparing them. Generally if the programming language has case-sensitive identifiers then Normalization Form C may be used, while if the programming language has case-insensitive identifiers then Normalization Form KC may be more appropriate.
If programming languages are using NFKC to level ("fold") differences between characters, then they need to use a slight modification of the identifier syntax from the Unicode Standard to deal with the idiosyncrasies of a small number of characters. These characters fall into three classes:
U+00B7 MIDDLE DOT needs to be allowed in <identifier_extend>.
(If the programming language is using a dot as an operator, then U+2219
BULLET OPERATOR or U+22C5 DOT OPERATOR should be used
instead. However, care should be taken when dealing with U+00B7
MIDDLE DOT, as many processes will assume its use as punctuation,
rather than as a letter extender.)<identifier_start>,
but rather in <identifier_extend>, along with combining
characters. In most cases, the mismatch does not cause a problem, but when
these characters have compatibility decompositions, they can cause
identifiers not to be closed under Normalization Form KC. In particular,
the following four characters should be in <identifier_extend>
and not <identifier_start>:
0E33 THAI CHARACTER SARA AM0EB3 LAO VOWEL SIGN AMFF9E HALFWIDTH KATAKANA VOICED SOUND MARKFF9F HALFWIDTH KATAKANA SEMI-VOICED SOUND MARKU+037A GREEK
YPOGEGRAMMENI and certain Arabic presentation forms have irregular
compatibility decompositions, and need to be excluded from both <identifier_start>
and <identifier_extend>. It is recommended that all
Arabic presentation forms be excluded from identifiers in any event,
although only a few of them are required to be excluded for normalization
to guarantee identifier closure.With these amendments to the identifier syntax, all identifiers are closed under all four Normalization forms. This means that for any string S,
isIdentifier(S) implies
isIdentifier(NFD(S))
isIdentifier(NFC(S))
isIdentifier(NFKD(S))
isIdentifier(NFKC(S))
Identifiers are also closed under case operations (with one exception), so that for any string S,
isIdentifier(S) implies
isIdentifier(toLowercase(S))
isIdentifier(toUppercase(S))
isIdentifier(toFoldedcase(S))
The one exception is U+0345 COMBINING GREEK YPOGEGRAMMENI. In
the very unusual case that U+0345 is at the start of S, U+0345
is not in <identifier_start>, but its uppercase and
case-folder version are. In practice this is not a problem, because of the way
normalization is used with identifiers.
Note: Those programming languages with case-insensitive identifiers should use the case foldings described in UAX #21: Case Mappings [Case] to produce a case-insensitive normalized form.
When source text (such as program source) is parsed for identifiers, the identifiers must be parsed before folding distinctions using case mapping or NFKC.
When source text (such as program source) is parsed for identifiers, the folding of distinctions (using case mapping or NFKC) must be delayed until after parsing has located the identifiers. Thus such folding of distinctions should not be applied to string literals or to comments in program source text.
Note: The Unicode Character Database [UCD] provides derived properties that can be used by implementations for parsing identifiers, both normalized and unnormalized. These are the properties
ID_Start,ID_Continue,XID_Start, andXID_Continue. Unicode 3.1 also provides support for handling case folding with normalization: the propertyFNCcan be used in case folding, so that a case folding of an NFKC string is itself normalized. These properties, and the files containing them, are described in the Derived Properties documentation [DerivedProps].
The Unicode Character Database supplies properties that allow implementations to quickly determine whether a string is in a particular normalization form. For each normalization form, the properties provide for each Unicode code point the following values:
| Value | Meaning |
|---|---|
| NO | The codepoint cannot occur in that normalization form. |
| YES | The codepoint can occur, subject to canonical ordering, but without any other constraints. |
| MAYBE | The codepoint can occur, subject to canonical ordering, but with constraints. In particular, the text may not be in the specified normalization form if this codepoint is preceded by certain other characters. |
Code that uses this property can do a very fast first pass over a string to determine the normalization form. The result is also either NO, YES, or MAYBE. For NO or YES, the answer is definite. In the MAYBE case, a more thorough check must be made, typically by putting a copy of the string into the normalization form, and checking for equality with the original.
This check is much faster than simply running the normalization algorithm, since it avoids any memory allocation and copying. The vast majority of strings will return a definitive YES or NO answer, leaving only a small percentage that require more work. The sample below is written in Java, though for accessibility it avoids the use of object-oriented techniques.
public int quickCheck(String source) {
short lastCanonicalClass = 0;
int result = YES;
for (int i = 0; i < source.length(); ++i) {
char ch = source.charAt(i);
short canonicalClass = getCanonicalClass(ch);
if (lastCanonicalClass > canonicalClass && canonicalClass != 0) {
return NO;
}
int check = isAllowed(ch);
if (check == NO) return NO;
if (check == MAYBE) result = MAYBE;
lastCanonicalClass = canonicalClass;
}
return result;
}
public static final int NO = 0, YES = 1, MAYBE = -1;
The isAllowed() call should access the data from Derived
Normalization Properties file [NormProps] for the
normalization form in question. (For more information, see the Derived
Properties documentation [DerivedProps] file.) For
example, here is a segment of the data for NFC:
... 0338 ; NFC_MAYBE # Mn COMBINING LONG SOLIDUS OVERLAY ... F900..FA0D ; NFC_NO # Lo [270] CJK COMPATIBILITY IDEOGRAPH-F900..CJK COMPATIBILITY IDEOGRAPH-FA0D ...
These lines assign the value NFC_MAYBE to the code point U+0338, and the
value NFC_NO to the codepoints in the range U+F900 .. U+FA0D. Note that there
are no MAYBE values for NFD and NFKD: the quickCheck function
will always produce a precise result for these normalization forms. All
characters that are not specifically mentioned in the file have the values
YES.
The data for the implementation of the isAllowed() call can be
accessed in memory with a hashtable or a trie (see Annex
3: Implementation Notes); the latter will be the fastest.
Implementations must be thoroughly tested for conformance to the normalization specification. In Unicode 3.0.1, the Normalization Conformance Test [Test] file was added for use in testing conformance. This file consists of a series of fields. When normalization forms are applied to the different fields, the results shall be as specified in the header of that file.
Since the Hangul compositions and decompositions are algorithmic, memory storage can be significantly reduced if the corresponding operations are done in code rather than by simply storing the data in the general purpose tables. Here is sample code illustrating algorithmic Hangul canonical decomposition and composition done according to the specification in Section 3.11 Combining Jamo Behavior. Although coded in Java, the same structure can be used in other programming languages.
static final int
SBase = 0xAC00, LBase = 0x1100, VBase = 0x1161, TBase = 0x11A7,
LCount = 19, VCount = 21, TCount = 28,
NCount = VCount * TCount, // 588
SCount = LCount * NCount; // 11172
public static String decomposeHangul(char s) {
int SIndex = s - SBase;
if (SIndex < 0 || SIndex >= SCount) {
return String.valueOf(s);
}
StringBuffer result = new StringBuffer();
int L = LBase + SIndex / NCount;
int V = VBase + (SIndex % NCount) / TCount;
int T = TBase + SIndex % TCount;
result.append((char)L);
result.append((char)V);
if (T != TBase) result.append((char)T);
return result.toString();
}
Notice an important feature of Hangul composition: whenever the source string is not in Normalization Form D, you can not just detect character sequences of the form <L, V> and <L, V, T>. You also must catch the sequences of the form <LV, T>. To guarantee uniqueness, these sequences must also be composed. This is illustrated in Step 2 below.
public static String composeHangul(String source) {
int len = source.length();
if (len == 0) return "";
StringBuffer result = new StringBuffer();
char last = source.charAt(0); // copy first char
result.append(last);
for (int i = 1; i < len; ++i) {
char ch = source.charAt(i);
// 1. check to see if two current characters are L and V
int LIndex = last - LBase;
if (0 <= LIndex && LIndex < LCount) {
int VIndex = ch - VBase;
if (0 <= VIndex && VIndex < VCount) {
// make syllable of form LV
last = (char)(SBase + (LIndex * VCount + VIndex) * TCount);
result.setCharAt(result.length()-1, last); // reset last
continue; // discard ch
}
}
// 2. check to see if two current characters are LV and T
int SIndex = last - SBase;
if (0 <= SIndex && SIndex < SCount && (SIndex % TCount) == 0) {
int TIndex = ch - TBase;
if (0 <= TIndex && TIndex <= TCount) {
// make syllable of form LVT
last += TIndex;
result.setCharAt(result.length()-1, last); // reset last
continue; // discard ch
}
}
// if neither case was true, just add the character
last = ch;
result.append(ch);
}
return result.toString();
}
Additional transformations can be performed on sequences of Hangul jamo for various purposes. For example, to regularize sequences of Hangul jamo into standard syllables, the choseong and jungseong fillers can be inserted, as described in Chapter 3. (In the text of the 2.0 version of the Unicode Standard, these standard syllables were called canonical syllables, but this has nothing to do with canonical composition or decomposition.) For keyboard input, additional compositions may be performed. For example, the trailing consonants kf + sf may be combined into ksf. In addition, some Hangul input methods do not require a distinction on input between initial and final consonants, and change between them on the basis of context. For example, in the keyboard sequence mi + em + ni + si + am, the consonant ni would be reinterpreted as nf, since there is no possible syllable nsa. This results in the two syllables men and sa.
However, none of these additional transformations are considered part of the Unicode Normalization Formats.
Hangul decomposition is also used to form the character names for the Hangul syllables. While the sample code that illustrates this process is not directly related to normalization, it is worth including because it is so similar to the decomposition code.
public static String getHangulName(char s) {
int SIndex = s - SBase;
if (0 > SIndex || SIndex >= SCount) {
throw new IllegalArgumentException("Not a Hangul Syllable: " + s);
}
StringBuffer result = new StringBuffer();
int LIndex = SIndex / NCount;
int VIndex = (SIndex % NCount) / TCount;
int TIndex = SIndex % TCount;
return "HANGUL SYLLABLE " + JAMO_L_TABLE[LIndex]
+ JAMO_V_TABLE[VIndex] + JAMO_T_TABLE[TIndex];
}
static private String[] JAMO_L_TABLE = {
"G", "GG", "N", "D", "DD", "R", "M", "B", "BB",
"S", "SS", "", "J", "JJ", "C", "K", "T", "P", "H"
};
static private String[] JAMO_V_TABLE = {
"A", "AE", "YA", "YAE", "EO", "E", "YEO", "YE", "O",
"WA", "WAE", "OE", "YO", "U", "WEO", "WE", "WI",
"YU", "EU", "YI", "I"
};
static private String[] JAMO_T_TABLE = {
"", "G", "GG", "GS", "N", "NJ", "NH", "D", "L", "LG", "LM",
"LB", "LS", "LT", "LP", "LH", "M", "B", "BS",
"S", "SS", "NG", "J", "C", "K", "T", "P", "H"
};
Transcript of letter regarding disclosure of IBM Technology
(Hard copy is on file with the Chair of UTC and the Chair of NCITS/L2)
Transcribed on 1999-03-10February 26, 1999
The Chair, Unicode Technical Committee
Subject: Disclosure of IBM Technology - Unicode Normalization Forms
The attached document entitled "Unicode Normalization Forms" does not require IBM technology, but may be implemented using IBM technology that has been filed for US Patent. However, IBM believes that the technology could be beneficial to the software community at large, especially with respect to usage on the Internet, allowing the community to derive the enormous benefits provided by Unicode.
This letter is to inform you that IBM is pleased to make the Unicode normalization technology that has been filed for patent freely available to anyone using them in implementing to the Unicode standard.
Sincerely,
W. J. Sullivan,
Acting Director of National Language Support
and Information Development
For information on the stability policies of the Unicode Consortium, especially regarding normalization, see Unicode Policies [Policies].
The following summarizes modifications from the previous version of this document.
| 22 |
|
Copyright © 1998-2002 Unicode, Inc. All Rights Reserved.
The Unicode Consortium makes no expressed or implied warranty of any kind, and assumes no liability for errors or omissions. No liability is assumed for incidental and consequential damages in connection with or arising out of the use of the information or programs contained or accompanying this technical report.
Unicode and the Unicode logo are trademarks of Unicode, Inc., and are registered in some jurisdictions.