Ligatures, Digraphs, Presentation Forms vs. Plain Text
Ligatures
Q: What's the difference between a “Ligature” and a “Digraph”?
Digraphs and ligatures are both made by combining two glyphs. In a digraph, the glyphs remain separate but are placed close together. In a ligature, the glyphs are fused into a single glyph. [JC]
Q: I work with manuscripts which use the “hr” ligature (for example) extensively. Can I get “hr” encoded as a ligature?
Ligaturing is a behavior encoded in fonts: if a modern font is asked to display “h” followed by “r”, and the font has an “hr” ligature in it, it can display the ligature. Some fonts have no ligatures, while others (especially fonts for non-Latin scripts) have hundreds of ligatures. It does not make sense to assign Unicode code points to all these font-specific possibilities.
Fonts intended to render the contents and appearance of manuscripts might be expected to have all the requisite ligatures.
The existing ligatures, such as “fi”, “fl”, and even “st”, exist basically for compatibility and round-tripping with non-Unicode character sets. Their use is discouraged. No more will be encoded in any circumstances. [JC] & [AF]
Q:Is there a character for the “ct” ligature in Unicode?
The “ct” ligature is one of many examples of ligatures of Latin letters commonly seen in older type styles. As for the case of the “hr” ligature, display of a ligature is a matter for font design, and does not require separate encoding of a character for the ligature. One simply represents the character sequence <c, t> in Unicode and depends on font design and font attribute controls to determine whether the result is ligated in display (or in printing). The same situation applies for ligatures involving long s “ſ” and many others found in Latin typefaces.
The Unicode Standard is a character encoding standard, and is not intended to standardize ligatures or other presentation forms, or any other aspects of the details of font and glyph design. The ligatures which you can find in the Unicode Standard are compatibility encodings only—and are not meant to set a precedent requiring the encoding of all ligatures as characters.
Digraphs
Q: I can't find the digraph “IE” in Unicode. Where do I look?
Look at “Where is my character?”
Q: My language needs the digraph “xy”. That digraph is distinctly different from “x” + “y” and is treated as a unit in my language. How should it be represented in Unicode?
[Editor's note: “xy” is being used as a stand-in for particular digraphs from particular languages; this question, or something very similar to it, has been asked recently, for instance, about “ch” in Slovak, about “ng” in Tagalog, about “ie” in Maltese, and about “aa” in Danish.]
A digraph, for example “xy”, looks just like two ordinary letters in a row (in this example “x” and “y”), and there is already a way to represent it in Unicode: <U+0078, U+0079>. If instead, the digraph “xy” were represented by some strange symbol, then it would indeed be new; there would not be any existing way to represent it using already encoded Unicode characters. But it is not a strange symbol—it is just the digraph “xy”. [PC] & [AF]
Q: What speaks against encoding a distinct character? It would make it easier for software to recognize the digraph, and there would seem to be enough space in the Unicode Standard?
While it may seem that there is a lot of available space in the Unicode Standard, there are a number of issues. First, while the upper- and lowercase versions of a single digraph like “xy” only constitute a couple of characters, there are many languages in which digraphs may be treated specially. Second, each addition to the standard requires updates to the data tables and to all implementations and fonts that support the digraph. Third, there is the problem that people will not represent data consistently; some will use the new digraph character and some will not—you can count on that. Fourth, existing data will not magically update itself to make use of the new digraph.
Because of these considerations and others, there will be situations in which it will be necessary to represent data using the decomposed form anyway—as for example when passing around normalized data on the Internet.
In summary, the addition of a new digraph character has a fairly substantial (and costly) set of consequences, in return for a minimal set of benefits. Because of that, the UTC has taken the position that no new digraphs should be encoded, and that their special support should be handled by having implementations recognize the character sequence and treat it like a digraph. [PC] & [AF]
Q: How can I implement a different sorting order for a digraph “xy” in my language when I don't have a separate character code?
There are several well-known collation techniques used to handle sorting of digraph sequences in various languages; for example using weights for particular sequences of letters. These techniques are preferable to having a separately encoded digraph, because they are more general and extensible. [PC]
Q: How can I distinguish a true digraph from an accidental combination of the same letters?
If the same letter pair can sometimes be a digraph, and sometimes be just a pair of letters, then you can insert U+034F COMBINING GRAPHEME JOINER to make the distinction, see: What is the function of U+034F COMBINING GRAPHEME JOINER? [AF]
Q: How can I get Unicode implementations to recognize the digraph more generally?
The Unicode CLDR project provides mechanisms that many software packages use to support the requirements of different languages. If the digraph sorts differently than the two separate characters, then it can be added to a collation table for the language. If the digraph needs to be listed separately, such as in an index, then it can be added to the exemplar characters. To request such a change, first look at the CLDR to determine if it is not already done, and file a change request if needed.
Presentation Forms
Q: What are presentation forms?
Presentation forms are ligatures or glyph variants that are normally not encoded but are forms that show up during presentation of text, normally selected automatically by the layout software. A typical example are the positional forms for Arabic letters. These don't need to be encoded, because the layout software determines the correct form from context.
For historical reasons, a substantial number of presentation forms were encoded in Unicode as compatibility characters, because legacy software or data included them. [AF]
Q: Why are “my” presentation forms NOT included in Unicode?
The Unicode Standard encodes characters, and it is the function of rendering systems to select presentation forms as needed to render those characters. Thus there is no need to encode presentation forms. [EM]
Q: Is it necessary to use the presentation forms that are defined in Unicode?
No, it is not necessary to use those presentation forms. Those forms were selected and identified in the early days of developing Unicode when sophisticated rendering engines were not prevalent. A selected subset of the presentation forms was included to provide users with a simple method to generate them. [MK]
Q: Can one use the presentation forms in a data file?
Use of presentation forms is not recommended because it does not guarantee data integrity and interoperability. In the particular case of Arabic, data files should include only the characters in the main Arabic block (U+0600..U+06FF) and Arabic supplement blocks (U+0750..U+07FF, U+0870..U+089F, U+08A0..U+08FF, U+10EC0..U+10EFF), rather than the presentation form blocks. [MK]
Q: What distinguishes presentation forms from other glyph variants encoded as compatibility characters?
Many characters with compatibility mappings are needed to correctly represent phonetic or mathematical notation. While presentation mechanisms, like styled text, could achieve the same visual representation, they cannot be automatically selected by the layout engine, but must be specified explicitly by the author. By using encoded characters rather than style markup, important semantic content for these notations will be preserved even if the text is converted to plain text.
For example, in Indo-European linguistics, U+2091 LATIN SUBSCRIPT SMALL LETTER E is used to indicate the vowel coloring of a laryngeal or a reduced vowel, indicated in typical notation as Hₑ or hₑ. If styled text subscript formatting were employed, then converting to plain text would result in He or he, with the full vowel 'e' giving a completely different meaning from 'ₑ'. Other examples include 'a' vs 'ɑ' and 'R' vs 'ʀ' in IPA. In physics, ℏ represents Planck's constant divided by 2π while ħ is LATIN SMALL LETTER H WITH STROKE used in IPA. [AF] & [DA]
Q: Why does Unicode contain whole alphabets of “italic” or “bold” characters in Plane 1?
The set of alphabets in Plane 1 in the Mathematical Alphanumeric Symbols block are meant to be used only in mathematics, where the distinction between a plain and a bold letter is fundamentally semantic rather than stylistic, and affects individual letters rather than longer runs of text. These characters systematically extend and complete a more limited set of “Letterlike Symbols” that had been supported in legacy character sets and were encoded in Unicode from the beginning. The use of these alphabets to simulate styled text appearance in plain text environments is an unintended side effect. Putting these alphabets in Plane 1 rather than in Plane 0 was meant to discourage people from using these characters in this way.
Q: Wouldn't it have made more sense to simply have introduced a few new combining characters in Plane 0, such as: “make bold”, “make italic”, “make script”, “make fraktur”, “make double-struck”, “make sans serif”, “make monospace” and “make tag”?
This would have achieved the same effect (and with the same space requirements too, at least for things like “bold uppercase A” in UTF-16). One could have also made other characters bold too, or create combinations of the attributes not currently represented.
However, it would have provided too much flexibility at the character encoding level and would have duplicated, and therefore conflicted with, some of the features present in proper markup languages such as SGML/HTML/XML. [JC] & [AF]
Q: Why doesn't Unicode have a full set of superscripts and subscripts?
The superscripted and subscripted characters encoded in Unicode are either compatibility characters encoded for roundtrip conversion of data from legacy standards, or are actually modifier letters used with particular meanings in technical transcriptional systems such as IPA and UPA. Those characters are not intended for general superscripting or subscripting of arbitrary text strings—for such textual effects, you should use text styles or markup in rich text, instead.
Notational systems may use super- and subscripts for entire expressions, or use both super- and subscripts on the same base:
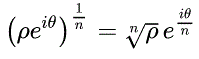
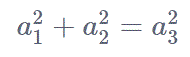
These and other complex layouts (such as recursively nested super- and subscripts) cannot be represented with dedicated character codes. For these systems, styling or markup is the appropriate method, even though that styling clearly conveys a semantic distinction. In other words, it is not a requirement that all facets of a notational system be representable in plain text. See also UTR#25 Unicode Support for Mathematics
Q: Why doesn't Unicode have a superscript modifier letter for French “è”?
This is a good example of a case where a superscripted Latin letter that looks superficially as if it should be encoded as a modifier letter is not actually represented appropriately that way.
French has ordinal numbers that use an e-grave (è) in their spelling, for example, deuxième for “second”. There are a number of abbreviations that occur for this kind of ordinal. For deuxième, the standard abbreviation is 2e, but there are also many other abbreviations that are not considered standard, but which nonetheless are commonly seen. For example, 2e, 2ème, or 2ème.
In the case of 2ème, it might seem that the abbreviation could be represented as a “2” followed by three modifier letters. The Unicode Standard has U+1D50 MODIFIER LETTER SMALL M and U+1D49 MODIFIER LETTER SMALL E, encoded for the Uralic Phonetic Alphabet, but no modifier letter for è. One might consider that an oversight in the Unicode Standard and ask for the encoding of a MODIFIER LETTER SMALL E WITH GRAVE, but that actually wouldn't be correct. The superscripted letters in 2ème are not actually modifier letters as used in phonetic transcriptional systems. Rather, they are just an example of an arbitrary portion of a word shown in a superscripted style to indicate an abbreviated form. Such a pattern is quite common in the writing systems of many European languages. For such usage, it is perfectly adequate and appropriate to use superscript styling, which can be applied to any sequence of letters, with or without accents, and which does not depend on letter-by-letter encoding of specific modifier letters in the Unicode Standard.
Plain Text
Q: What is the difference between “rich text” and “plain text”?
Rich text is text with all its formatting information: typeface, point size, weight, kerning, and so on. Plain text is the underlying content stream to which formatting is applied.
One key distinction between the two is that rich text breaks the text up into runs and applies uniform formatting to each run. As such, rich text is inherently stateful. Plain text is not stateful. It should be possible to lose the first half of a chunk of plain text without any impact on rendering.
Unicode, by design, only deals with plain text. It doesn't provide a generalized solution to rich text issues. [JJ]
Q: I'm reading a book which uses italic text to mean something distinct from roman text. Doesn't that mean that italics should be encoded in Unicode?
No. It's common for specific formatting to be used to convey some of the semantic content—the meaning—of a text. Unicode is not intended to reproduce the complete semantic content of all texts, but merely to provide plain text support required by minimum legibility for all languages. [JJ]
Q: What does “minimum legibility” mean?
Minimum legibility refers to the minimum amount of information necessary to provide legible text for a given language and nothing more. Minimally legible text can have a wide range of default formatting applied by the rendering system and remain recognizably text belonging to a certain language as generally written. [JJ]
Q: I've spotted a sign which uses superscript text for a meaningful abbreviation. Doesn't that mean that all the superscripted letters should be encoded in Unicode?
No. It's common for specific formatting to be used to convey some of the semantic content—the meaning—of a text. As for italics, bold, or any other stylistic effect of this sort conveying meaning, the appropriate mechanism to use in such cases is style or markup in rich text.