Myanmar
Myanmar Encoding in Unicode
Q: How is the Myanmar script encoded?
The Myanmar script was added to the Unicode Standard in Version 3.0 (September, 1999). Version 5.2 significantly extended the script in 2009. The Myanmar encoding of Unicode includes these blocks for characters of this script:
- The base Myanmar characters (U+1000-U+109F)
- Myanmar Extended-A (U+AA60–U+AA7F)
- Myanmar Extended-B (U+A9E0–U+A9FF)
Code points include letters (consonants and independent vowels), vowel signs, medial signs, digits, various signs, and punctuation. Medial and vowel signs, anusvara, visarga, virama, asat and others combine with letters.
UTN #11 "Representing Myanmar in Unicode" presents detailed information on using Unicode with the Myanmar script across a range of typical implementation issues, from keyboards to collation.
Q: Where are Unicode characters for the Myanmar script described in the standard?
The Myanmar script is documented in Section 16.3, Myanmar in The Unicode Standard. See all Myanmar script characters listed by Unicode block. Click on the links alongside each code point to see detailed character properties.
Q: What languages can be written with Unicode Myanmar characters?
The Unicode encoding for the Myanmar script covers the characters needed for both modern and old Myanmar (Burmese) and about 30 additional languages. An incomplete listing of covered languages includes:
- Myanmar (Burmese)
- Mon
- Arakanese
- S'gaw Karen
- Eastern and Western Pwo Karen
- Pa'O Karen
- Geba Karen
- Kayah
- Shan
- Tai Khamti
- Tai Laing
- Aiton
- Phake
- Jingpho
- Rumai Palaung
- Shwe Palaung
- Pali (in several orthographies)
Some of these languages require characters beyond those needed for the Myanmar language (Burmese). Font vendors interested in covering a wide range of languages would need to include the fuller range of characters across the Myanmar code blocks, as well the necessary conjunct and contextual forms. To enter text, language-specific keyboards that have the characters for the language may be required. These may be available as web applications and as soft keyboards on mobile devices.
UTN #11 "Representing Myanmar in Unicode" presents detailed information on using the Myanmar script for many of these languages. [SRL] & [CWC] & [NL] & [BM]
Q: What about collation of Myanmar language data? Is that just a binary sort?
Generally, a binary sort is not recommended. Instead, use Unicode Collation. The collation chart for Myanmar is here.
Q: How do I enter a subjoined consonant?
The Unicode encoding for subjoined consonants uses U+1039 MYANMAR VIRAMA. Some keyboards provide a key for this character, so that a subjoined consonant can be entered as a two-key sequence of VIRAMA and the consonant. Other keyboards provide keys that enter the VIRAMA and the consonant together. [NL]
Q: I cannot find the code points for the kinzi in Unicode. What do I do?
The Unicode sequence for the kinzi for NGA is U+1004 NGA, U+103A ASAT, U+1039 VIRAMA, followed by the next letter (base consonant).
A kinzi is a mark above the base consonant that represents a final consonant of a phonetic syllable that has become the initial consonant in an orthographic syllable. The Burmese language has a kinzi only for the consonant NGA (င). This kinzi looks like a small Greek Epsilon shape (င်္) placed over the following letter. Other languages have kinzi forms for additional consonants, as described in UTN #11, page 7.
Here is an example of a kinzi in text:
The code points are: 101E 1004 103A 1039 1018 1031 102C.
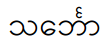
The linguistic syllables are saŋ-bhàw, but the orthographic syllables are sa-ŋbhàw. This allows searching for the NGA letter as a character. The "Kinzi Visualizer " shows the transformation.
" shows the transformation.
Note that some Unicode keyboards may provide an input key for the kinzi. In this case, the output is the series of code points defined above.
Contributions to this Q&A by [NL] and [SM].
Q: Are there recommended Unicode fonts for Myanmar text? Where can I find them?
Several Unicode-based fonts support the Burmese language, including Myanmar Text (included in Windows), Myanmar Sangam MN (included in macOS and iOS), and Noto Sans Myanmar (included in Android). For other languages using the Myanmar script, the best font as of early 2022 is Padauk, an open source font from SIL International.
Q: I am using a Unicode-compliant font on Unicode text. However, some characters are rendered incorrectly. What is wrong?
Some rendering engines may not properly render with all Unicode fonts. Make sure the font and rendering software are compatible. In some cases, changing to a different Unicode-compliant font may fix the problem. The Display Problems page has some general help that may be useful.
Another possibility is that the Unicode text is malformed, that is, the code points are incorrectly ordered.
Q: Is Unicode just another font for Myanmar?
Unicode is neither a font nor a font encoding. It is a character encoding, which means it stores text as a sequence of characters in a well-defined order, so that any device will interpret the text as Myanmar script and display it correctly. Unicode can be used with different fonts, so that text can be shown in different styles, but will remain the same text. Unicode encodes abstract characters, so that for example (![]() ) is always stored the same way: a search for it will include all instances independent of context. However, a font would display this character with a different form for different contexts, such as different base characters.
) is always stored the same way: a search for it will include all instances independent of context. However, a font would display this character with a different form for different contexts, such as different base characters.
As a published standard, Unicode describes the identity of the character assigned to each code point, including the character characteristics used for other text processing functions such as collation, combining status, and combining order. These data are available via the ICU C++ and Java libraries. [NL] & [BM]
Legacy Encodings for Myanmar
Q: What other encodings are commonly used for the Myanmar language?
There are several ad hoc font encodings in common use, all needing specific fonts to render text. ZawgyiOne, Zawgyi 2008, and Myazedi are most commonly used.
Q: What are the differences between Unicode and the ad hoc encodings, such as Zawgyi?
Unicode's Myanmar script provides:
- Compatibility across platforms, operating systems, and programming languages
- Unique code points for each consonant, vowel, and modifier, regardless of visual appearance
- Efficient use of code space
- The ability to support all languages that can be written with the script
- A unique ordering of code points comprising a Myanmar syllable (consonants, vowels, and so on), where vowels always follow the consonant
- Consistent implementation of text comparison, search, and other language processing
- Font-independent representation, allowing rendering with any Unicode-compliant font installed on a device
The ad hoc font encodings such as Zawgyi have many serious problems:
- No compatibility across platforms, operating systems, or programming languages
- Incompatible with Unicode, the widely supported international standard
- Incompatible with Internationalized Domain Names (IDN)
- Use of multiple code points for characters and combined renderings, leading to interchange chaos
- Inefficient use of the code range, requiring twice as many code points to represent only a subset of the script
- No support for all the languages used in Myanmar, making it impossible to show text in languages using this script other than Myanmar
- Vowel code points may appear before or after a consonant. This results in different representations for each visual rendering, leading to search and comparison problems.
- Inconsistent text comparison, searching, and other language processing, often within a single document.
- Lack of font support. Because the appearance of a syllable depends on the specific code points selected, text in these ad hoc encodings such as Zawgyi can only be rendered if the specific font is installed on the target device.
- No support in standard software offerings
Q: What are some of the visible differences between Unicode and the ad hoc encodings such as Zawgyi?
The font page for the Myanmar Wikipedia shows code point differences between Unicode and Zawgyi, the most commonly used ad hoc scheme.
For each combining character, the Unicode Standard defines a single code point that is rendered appropriately for the base character. For example U+103C, the ra medial surrounds an associated consonant with a line. A Unicode font generates the right shape at display time.
Non-Unicode fonts define as many as 8 code points for different parts of the same ra glyph. Typing is cumbersome because the user must select the right form for each context.
An incorrect match between font and text shows "dotted" characters or overlapping lines, and also incorrect characters, as shown in the following table.
| Encoding | With Unicode (Padauk) font | With ZawgyiOne font | Code points |
|---|---|---|---|
| Unicode text | 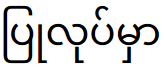 |
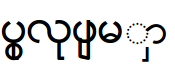 |
U+1015 U+103C U+102F U+101C U+102F U+1015 U+103A U+1019 U+103E U+102C |
| Zawgyi-encoded text | 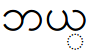 |
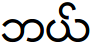 |
0x1018 0x101a 0x1039 |
Unicode text can be displayed using any Unicode-compliant font. However, non-Unicode text can only be displayed with its encoded font.
Unicode also defines a unique order of code points for base letters and combining characters.
Q: Is there a universal font that will display Unicode and Zawgyi text together?
No. Since the code points for Zawgyi and Unicode use the same range (0x1000-0x109f), no font can automatically apply the right character shapes. A universal font is impossible.
Zawgyi should be converted to Unicode before adding to a web page or other display.
If absolutely necessary, HTML can explicitly specify a non-Unicode font for a tagged region if the encoding of the text is non-Unicode.
Q: Does "UTF-8" always indicate Unicode?
Yes, when properly used with Unicode code points. "UTF-8" technically does not apply to ad hoc font encodings such as Zawgyi.
Q: How can I tell what encoding is used for a particular website or piece of text?
Almost all text in a given encoding will render correctly only when displayed with a compatible font. For example, Zawgyi text will appear incorrectly with a Unicode font, and text encoded as Unicode will look wrong with the ZawgyiOne font. However, some strings look identical in both encodings because all these fonts have a common subset of characters.
Some online tools are available that will help determine the encoding of text.
- zawgyi-unicode-test.appspot.com takes text and displays it using several common fonts, including two different Unicode fonts
- gist.github.com/swanhtet1992
- github.com/greelikeorange
The Unicode Consortium does not guarantee that these tools are accurate or complete, however.
Q: Are there any tools that can help me detect Zawgyi encoded text and convert it to Unicode?
Yes. Because some strings are valid in both Zawgyi and Unicode, it is not always possible to achieve 100% accuracy in distinguishing the two. The library Myanmar Tools uses a machine learning model to estimate whether a string is represented in Zawgyi or in Unicode. The tools are available from the Google i18n team in JavaScript, Java (Android), and other programming environments. See: https://github.com/googlei18n/myanmar-tools
Note: Detectors that use hand-coded rules are susceptible to flagging content in other languages like Shan and Mon as Zawgyi when it is actually Unicode, so are not generally recommended.
Q: Is it possible to convert text in other encodings to Unicode?
Yes, several converters are publicly available:
The Unicode Consortium does not guarantee the quality of these solutions, however.
Q: Should I support both Unicode and Zawgyi on my site? If so, how do I do that?
Because some platforms do not yet have Unicode fonts, it is helpful to provide a way for all users to view content. The preferred technique is to detect the encoding of user-entered text, then convert to Unicode. Display the converted text.
Other options are to use a webfont on your site and apply it with CSS in any HTML block that displays text, for example, a <div class="myfontclass"> tag. The font is loaded along with the text, allowing modern browsers to display text in the loaded font. This works well in most cases for either Zawgyi or Unicode text. However, transmitting the font increases load time for such content.
Another option is to let users switch via a prominent control on the page to select either Unicode or other encoding. Then use this setting to load pages in the selected encoding. An automatic converter may be used to prepare text as needed. This has the advantage of avoiding font download, but adds complexity to both the client and server.
As a final option, don't worry about it. Provide content in only Zawgyi or only in Unicode and let users determine whether to use your site based on the encoding. This limits the usability of your content, of course, because either the Zawgyi or the Unicode content will appear garbled depending on the user's installed font.
Remember that search engines may not understand all text encodings. Unicode text on your site can be consistently interpreted.
Q: My site has content entered by users in both Zawgyi and Unicode text. How can my users read both?
It's great that you want your users to be able to read all messages! There are at least two ways to enable this, similar to the methods described above for websites. Each requires detecting the encoding of each message posted.
The preferred method is to convert all postings to Unicode form. Set CSS to use Unicode-compatible fonts.
An alternative method is to use web fonts for the site. Make sure each posting is in its own tagged block such as div. Set the CSS for each post to either a Unicode font or Zawgyi, depending on what was detected for the individual posting. Note that this will result in an inconsistent look to the text due to different font styles.
You may also consider educating your users on using Unicode fonts.
Q: How is Myanmar handled on mobile devices?
Most mobile devices do not allow the user to change or replace the installed fonts. An application may "bundle" a font, but that will only be used within the application, not for other tools or apps.
Many devices already include a Unicode-compliant font that is used by default for any Myanmar text. Any Unicode text will appear correctly in the system-installed applications. Zawgyi text will look wrong unless the particular application has included the Zawgyi font within the application.
Some device vendors have installed ZawgyiOne in place of a Unicode font. In this case, Zawgyi will look right, but Unicode text in messages and web sites will look wrong.
It is also possible for an application or device to detect and convert text to match the installed fonts.
Q: How can I tell if my system is using a Unicode font or Zawgyi by default?
Just examine the appearance of the Myanmar character code point (U+104E) here: ၎
| If the above is looks like this character, you have a Unicode font: | 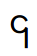 |
| If it looks like this, your browser is using Zawgyi or Myazedi: | 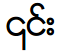 |
| If it looks blank or a box, no Myanmar font was found. | |
Q: My friends all use Zawgyi in email and texting, but my device only supports Unicode. How can I communicate with them?
This is complicated, primarily because fonts cannot be added or changed on most mobile devices. Free Myanmar Unicode keyboards are available for most mobile devices from online sources, so work with your friends to agree on a common way to communicate.
Apps that convert between Zawgyi and Unicode are also available. Copying and pasting text messages into such an interactive converter will let you read any message.
Q: Do I need an input method editor (IME) to properly enter Myanmar text in Unicode?
The keyboard arrangement does not determine if the text is Unicode or another form. Keyboard applications that produce Unicode are available on most devices and web apps. Some browsers support extensions that provide virtual keyboards for Myanmar and other scripts.
Q: Is the keyboard arrangement for Unicode different from other fonts?
Unicode does not specify a keyboard arrangement, but leaves the keyboard or IME provider free to arrange the keyboard in the most natural way for the users. However, a Unicode font requires many fewer keys, because only one code point is needed for each diacritic.
Q: Will everyone in Myanmar eventually convert to Unicode?
The Unicode Standard was designed to provide consistent and efficient interchange of all textual information. Currently, much Myanmar-language text online still uses font encoding. However, Unicode's benefits for the Myanmar language itself, as well as the enabling of non-Myanmar languages, are expected to make Unicode the only way to represent Myanmar script. This is the trend followed for all other scripts supported by Unicode.