- Previous message: Elaine Keown: "Re: U+0140"
- In reply to: Alexandros Diamantidis: "Re: U+0140"
- Next in thread: Alexandros Diamantidis: "GREEK ANO TELEIA (was: Re: U+0140)"
- Reply: Alexandros Diamantidis: "GREEK ANO TELEIA (was: Re: U+0140)"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
At 12:26 AM 4/16/2004, Alexandros Diamantidis wrote:
>* Philippe Verdy <verdy_p@wanadoo.fr> [2004-04-16 01:22]:
> > > U+0387 GREEK ANO TELEIA
> > wrong form? it's a small square, and is the greek semicolon, and is then
> > separating words.
>
>U+0387 is canonically equivalent to U+00B7. About its shape, whether it's
>square or round depends on what the full stop looks like in that font -
>they should look exactly the same, only the "ano teleia" (upper dot)
>should be at x-height.
If two characters are canonically equivalent, they can't have a
consistently distinct appearance. Nevertheless, most fonts appear to give a
different glyph to 0387 than to 00B7, not only in height, but also in
weight. (See attached sample). If data is normalized, the appearance of ano
teleia will change (since 0387 will change into 00B7) and users will be
disappointed.
In any environment where data are normalized, getting the correct
appearance requires the use of OpenType with language dependent glyph
selection (and a layout engine that supports this - or the use of a Greek
specific font.
A./
PS: it's water under the bridge by now, but in my opinion, this is another
example of questionable unification of punctuation based on considering
only the 'ink' and not the positioning of it. If one is considering only
the roughest of plain text, having only a single code for a 'dot somewhere
in the middle of the line' yields acceptable results, but it does make the
use of such plain text as back-bone for typographically correct rendering
unnecessarily difficult. The extreme form of such 'plain text only'
approach is using ` and ' as stand-in for the single quotes.
However, for paleo punctuation, where there's no comparable established
typographical tradition requiring consistent differentiation, the use of
unified punctuation is preferable.
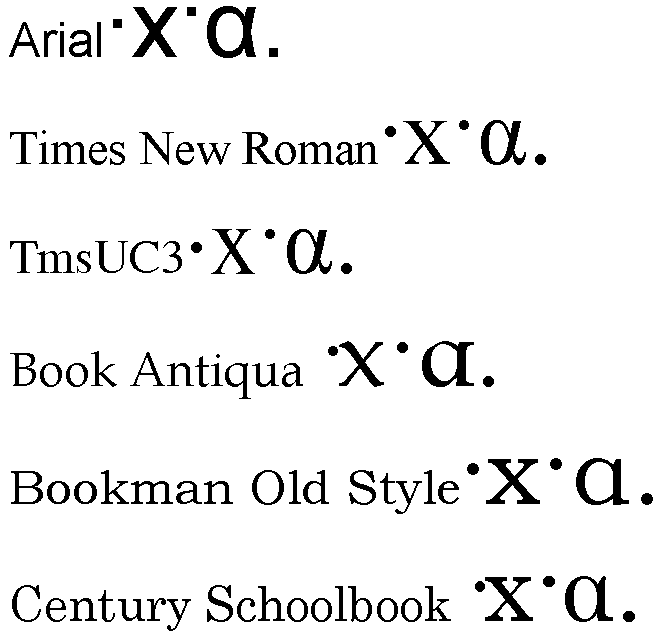
- Next message: Antoine Leca: "Re: U+0140"
- Previous message: Elaine Keown: "Re: U+0140"
- In reply to: Alexandros Diamantidis: "Re: U+0140"
- Next in thread: Alexandros Diamantidis: "GREEK ANO TELEIA (was: Re: U+0140)"
- Reply: Alexandros Diamantidis: "GREEK ANO TELEIA (was: Re: U+0140)"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
This archive was generated by hypermail 2.1.5 : Fri Apr 16 2004 - 15:04:56 EDT