Date: Tue, 16 Aug 2011 21:43:24 +0200
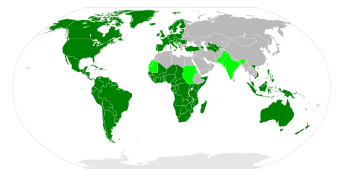
extract from http://en.wikipedia.org/wiki/Latin_alphabet to illustrate my question
Latin alphabet world distribution. The dark green areas shows the countries where this alphabet is the sole main script. The light green shows the countries where the alphabet co-exists with other scripts. Note that the Latin alphabet is sometimes extensively used even in areas coloured grey due to use of unofficial second languages (e.g. French in Algeria or English in Egypt) and Latin transliterations of the official language (practised to some degree in most countries with a non-Latin alphabet, e.g., pinyin in China).
Only to show that seems to me possible to have a map giving unicode set associated to a language.
I dicovered in http://www.unicode.org/Public/UNIDATA/Blocks.txt that some blocks are language specific, and other more generic, generic because used in many language.
The unicode set I imagine could be a block identifier.
My goal is to make statistical computation on word according to a language. May be I will use an heuristic based on unicode blocks definitions.
But to know common unicode characters set use for a lnguage can be usefull, for text editor for example.
Attached text file contains statistic for unicode block usage by language, created from a dbpedia dump.
Best regards
Luc Peuvrier
- text/plain attachment: unilang.txt