Where is my Character?
If you are trying to find a specific character in the
Unicode Standard, the first place to go is the
code charts.
The code charts are organized into blocks, which are groupings of related characters.
For each character defined in Unicode you will find an assigned
code point: a hexadecimal number that is used to represent
that character in computer data.
The very term character is rather
ambiguous, and may be interpreted broadly or narrowly. In this
document, we'll use a very broad sense. For more details, see
UTR #17: Character Encoding Model.
You may not find the character in what you think is
the obvious spot. While the characters in Unicode are grouped into
blocks, this is only a rough grouping because characters can be
categorized many different ways. In particular, punctuation and
symbols are applicable across a very wide range of usages and
scripts (writing systems). Even the notion of a script itself
is not well-defined; text in a given language may make use of
characters from multiple scripts. For example, the digits 0-9 are in
widespread use; the Devanagari danda is used across many
Indic scripts.
Thus you may need to look in several locations to
find your character. If you are using the book, you
may find the printed character index in the back of the standard
helpful. The same data is available online as a plain text file,
Index. Or you can use the web version of the
Unicode Character Name Index.
You can also do a text search in the online
Unicode names list. For example, suppose you were searching for a
"Japanese kome", the character ※. By opening up the
NamesList.txt in your browser, and
searching for "Japanese kome", you would find it under the entry:
203B REFERENCE MARK
= Japanese kome
= Urdu paragraph separator
x (tibetan ku ru kha bzhi mig can - 0FBF)
Documentation regarding the syntax conventions of the online
Unicode names list can be found in
Names List File Format.
For Han characters (Chinese, Japanese, and Korean) you can find
the character you are looking for by using the printed Han
Radical-Stroke Index in the book or by using the the online web
Unihan Database.
There are auxiliary charts which contain the Unicode characters
organized in different ways. You may sometimes find that useful in
finding your character. For example, see
Collation
charts,
Script charts,
Case Mapping
charts, or
Normalization charts. If you know what legacy character encoding
your character is in, you might be able to find it in the
ICU Character
Set Mapping Tables.
You may not find a character simply because the
charts do not specify the exact shape; they only provide a
representative shape for identification. For example, a lowercase
Cyrillic p could appear with any of the following character
shapes (also called glyphs). The second is customary for italic in
Russia, and the third is customary for italic in Serbia:
Cyrillic p |
Russian Italic |
Serbian Italic |
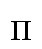 |
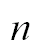 |
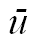 |
Characters may also take on different shapes in
different contexts. So, for example, the Arabic character hah
may have four different basic shapes.
Representative shape in code chart |
Possible shapes in context |
|
|
|
|
|
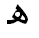 |
The character you are looking for may be represented
as a sequence of code points in Unicode. Here are examples of
such characters, and their representation as a sequence of code
points.
Character |
Code Points |
Linguistic Usage |
|
0063 0068 |
Slovak, traditional Spanish |
|
0074 02B0 |
Native American languages |
|
|
0078 0323 |
|
|
019B 0313 |
|
|
00E1 0328 |
Lithuanian |
|
|
0069 0307 0301 |
|
30C8 309A |
Ainu in kana transcription |
Similarly, you won't find the Indic half-forms in the code
charts, since they are formed with a consonant + halant (virama).
For example:
Representative shapes in code chart |
Display appearance |
|
|
|
Other Devanagari ligatures such as ksha are coded with
sequences, as shown in Table 12-4: Sample Devanagari Half-Forms of
the core specification. For example:
Representative shapes in code chart |
Display appearance |
|
|
|
|
In addition, the joining control characters can be used to
request specific appearances, as in Figure 12-8 of the core specification. For example:
Representative shapes in code chart |
Display appearance |
|
|
|
|
|
Unfortunately there are not yet such detailed block descriptions
for all Indic scripts, so it may not be clear exactly which
sequences to use. These should be forthcoming in the future. In the
meantime, sometimes you may get an answer if you ask on the general
Unicode
public e-mail list.
In some rare instances, you will find apparently
identical characters. In most cases, if not all, this is to maintain
compatibility with the original source standards for Unicode:
vendor, national, and international character standards in wide
usage in 1990. For example, there are duplicate encodings in the
following case:
 |
Capital letter A with ring |
|
|
Angstrom sign |
There are also particular shapes of characters that
are given separate code points in Unicode, such as the shapes of the
Arabic character hah listed above. These were also added to
Unicode because of pre-existing standards.
For compatibility with pre-existing standards, there are
characters that are equivalently represented either as sequences of
code points or as a single code point called a composite
character. For example, the i with 2 dots in naïve
could be presented either as i + diaeresis (0069 0308)
or as the composite character i + diaeresis (00EF).
There are other cases where the order of two combining characters
does not matter. For example, the pair of combining characters
acute and dot-below can occur with either one first; both
alternate orders are equivalent. The rules for when order is
significant is precisely spelled out by the Unicode Standard.
Due to the requirements for uniqueness — especially on the
Internet — Unicode provides for a unique format, called Form C.
This format always picks one of the equivalent code points (or
sequences of code points) and not the other. It also picks a
specific order where there are alternatives. For more information,
see UTR #15: Unicode Normalization Forms.
In a very few cases, Unicode separates glyphs as
distinct characters on the basis of whether they are treated as
letters or not. For example, the following characters are
distinguished on this basis, even though the range of possible
shapes are the same.
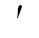 |
Modifier letter prime. Is treated as a letter. Used
to transcribe the "soft" sign in Cyrillic. |
|
Prime. Treated as a punctuation mark or symbol. Used
in mathematics, and as a symbol for minutes (fractions of
degrees). |
In those rare cases where this occurs, to decide
which character to use you should consult the text of the Unicode
Standard.
Simply because a character or sequence of
characters may have a different sorting order does not
qualify it to be given a separate code point in Unicode. For
more information, see
UTR #10: Unicode
Collation Algorithm.
Finally, your character may not yet be encoded in
Unicode. There is a well defined
submission process for new characters or scripts. This process
verifies that the proposed character is in fact a candidate for
encoding. In some cases, this process may not be straightforward.
Because the Unicode Standard and ISO 10646 are
synchronized in character codes, both organizations need to agree to
the encoding of new characters. This process can require some time
before a new character is accepted into the standard, and some time
beyond that before it is fully supported in products.

