Greek Language and Script
Q: Why are there two blocks of Greek characters in the Unicode Standard?
The layout of the Greek script in the Unicode Standard is an artifact of the history of Unicode and of ISO/IEC 10646. The Unicode Standard started out with just the Greek block (U+0370..U+03FF), with Greek characters laid out in compatibility with the modern Greek monotonic standard, ISO/IEC 8859-7, and with additions for some Coptic, ancient Greek, and Greek symbol letters to fill out the block.
As part of the standards compromise which resulted in the synchronization of the Unicode Standard with the drafts of ISO/IEC 10646, the Unicode Standard acquired a collection of pre-composed Greek characters intended for polytonic Greek usage. Those had to be placed somewhere, and a “compatibility” block was created at U+1F00..U+1FFF to accommodate them.
Q: Does the existence of two blocks of Greek characters create problems for searching in Greek?
The division may seem unexpected from the perspective of polytonic Greek; however, breaking a script across blocks is not uncommon, and implementations, including search usually don’t care about such division into blocks.
Also, if you examine the code charts for the U+1F00..U+1FFF block of “extended” Greek carefully, you will note that all the polytonic Greek pre-composed characters have canonical mappings. This means that they are canonically equivalent to sequences consisting of the basic letters plus sequences of the basic letters plus combining voicing and accent marks. Any properly constructed Unicode search operation should treat canonical equivalents the same, so it should not matter whether one specifies a target match in terms of the pre-composed characters or in terms of the sequences of basic letters and combining marks. This situation for Greek is no different from the requirement for the Latin script that a search for a pre-composed Latin letter and the same letter with a combining accent mark produce the same results.
Q: Which block of Greek characters should I use?
The answer to that is that it depends what you are doing. But generally, the basic Greek block plus the use of the generic combining marks in the Combining Diacritical Marks block (U+0300..U+036F) is the best approach to polytonic Greek support. Some fonts do not directly support the display of the pre-composed extended Greek characters, and most current systems and browsers do a decent job for Greek using generic fonts. In any case, best display of Greek data—particularly polytonic Greek data—will result from use of specially-designed Greek fonts which handle all combinations of Greek accents optimally.
Q: What is the order of the accents on ancient Greek letters in a Unicode encoded data stream?
The order of the combining marks used for accents on letters for ancient Greek is the same as all other cases in Unicode: the accents are represented by combining marks that appear after the base letter. The canonical order can be seen either by looking at the polytonic Greek charts in the Unicode Standard or at the online Greek normalization charts.
Q: Why does Unicode encode a separate character for the final sigma in Greek?
While it may at first seem to violate the character-glyph model, there are actually three reasons for this, all of which conspire to support the same result.
First, there is very extensive legacy practice for handling Greek characters. And in most of the major Greek character encodings, a character for the final sigma and a character for the non-final sigma are distinguished. This includes IBM Code Pages 423, 851, and 869, Windows Code Page 1253, the HP Greek8 code page, ISO 8859-7, and the Macintosh Greek code page. Ignoring this legacy and failing to encode a separate lowercase final sigma and non-final sigma would have resulted in major interoperability issues for Unicode and all preexisting Greek data in those character encodings.
Second, the usability of a rendering model involving positional alternate glyphs for characters depends in part on the distribution and regularity of those forms in each particular script. The Arabic script is at one end of this continuum, since it is a cursive script, with predictable glyph shape variations for every character based on word position; such a script fits naturally into a processing model which has a basic character for each “letter”, and then dynamically picks presentation forms (or even ligatures) based on positional analysis. Greek, on the other hand, is a non-cursive script, and in modern usage, at least, has basically just the single positional variant form, for sigma. In the latter case, burdening the rendering model with positional variant analysis is a bad engineering tradeoff, just to get the two sigmas to be represented by a single code. It is easier to simply equate the two sigma codes for operations which are concerned with word content, for example.
Finally, a detailed analysis of Greek corpora and the usage of final sigma and non-final sigma makes it clear that no simple positional context rule would cover all the cases. The rule is actually rather complex and has lots of exceptions, for abbreviations and other special cases. That the “rule”, if indeed there is a single rule, is so complex, indicates that:
- it would be difficult to implement, and would probably lead to nagging inconsistencies between implementations;
- the long history of final sigma and non-final sigma as character entities (encoded or not) has resulted in them starting to accrue some independent “characterhood”, enabling people to think of uses for them independent of their canonical positions.
Taken all together this was an easy call: Unicode should (and does) have a separate character code for the Greek final sigma and the non-final sigma.
Q: How do I represent a mute iota?
In Greek, the vowels α η ω can be followed by a mute iota. In those cases, the iota is written in smaller size, under the letter: ᾳ ῃ ῳ, and it is represented using U+0345 COMBINING GREEK YPOGEGRAMMENI.
In initial capitalization and in all-caps words, one can find a wide range of graphic presentations of the mute iota:
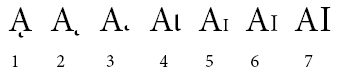
The proper sequence of characters to use depends on the graphic presentation you want to achieve:
- for 1-3, use U+0345 COMBINING GREEK YPOGEGRAMMENI
- for 4, use U+03B9 GREEK SMALL LETTER IOTA
- for 5-7, use U+0399 GREEK CAPITAL LETTER IOTA (may be styled in small caps)
Conversely, rendering systems usually render a mute iota represented by U+0345 COMBINING GREEK YPOGEGRAMMENI as one of 1-3, render a mute iota represented by U+03B9 GREEK SMALL LETTER IOTA as 4 and render a mute iota represented by U+0399 GREEK CAPITAL LETTER IOTA as one of 5-7.
However, it is perfectly acceptable for a rendering system to produce any of the graphic presentations of mute iota from any of the coded character representations, much like it is perfectly acceptable for a rendering system to produce a small caps graphic display of lowercase text.
Note that this has implications for case conversion. In particular, U+0345 COMBINING GREEK YPOGEGRAMMENI contains information that can be lost when converting to uppercase. This is not unusual with case mappings: converting “McGowan” or “vedereLa” to uppercase also loses information. [EM]
Q: Where can I find a detailed, scholarly analysis of all the problems related to the Greek script and Unicode?
Greek Unicode Issues has more than you will probably ever need to know about all the Greek encoding issues related to Unicode. It also has links to other sites dealing with Greek.
has more than you will probably ever need to know about all the Greek encoding issues related to Unicode. It also has links to other sites dealing with Greek.
Q: Why is the Unicode Standard inconsistent in the spelling of “lambda” and “lamda”?
“Lambda” corresponds to the conventional English name of the Greek letter while “lamda” is the direct transliteration from modern Greek name of the letter: Λάμδα. So why does the Standard have both spellings for the character name?
The use of the transliteration dates back to Greek National Standard ELOT 928, from which derived the character names in ISO 8859-7:1987. From there, they were adopted into the draft for ISO 10646, while Unicode 1.0 had been using LAMBDA instead. Part of the merger between Unicode 1.0 and ISO 10646 back in 1992 was the agreement to make Unicode character names exactly match the ISO 10646 names. Names for characters unique to the original repertoire of the Unicode Standard were not adjusted, leading to the inconsistency in spelling.
Because of the way character names function as identifiers, they are bound by longstanding stability guarantees for names, which means nothing can be done about “correcting” names in the standard.
Q: Why are some composite uppercase Greek letters missing from Unicode?
The Unicode Standard encodes various composite characters for polytonic Greek, mostly in the Greek Extended block (U+1F00..U+1FFF). Usually these come in identifiable case pairings, but some lowercase composite characters lack a corresponding uppercase composite. A side effect of these omissions is that Greek text in normalization form C (NFC) may no longer be in NFC after changing case.
For example, the ancient Greek name “Ρ̓ᾶρος” starts with an uppercase Ρ with a smooth breathing (unusual in ancient Greek). Ordinarily that would be represented by the sequence <03A1, 0313>, which is in NFC. However, when that sequence is lowercased to <03C1 0313>, the string is no longer in NFC. The NFC form of that sequence would be U+1FE4 “ῤ”, instead. The lack of composite capital characters also breaks any uppercasing or lowercasing algorithm that does not allow changing the length of the string.
There are other issues in casing polytonic Greek: uppercase Greek letters with accents are sometimes represented using compatibility spacing accents from the Greek Extended block, preceding the letters, rather than the preferred representation with combining marks following the letters.
Preservation of normalization forms for Greek text across a casing transform is not sufficient reason to fill the gaps in composite uppercase Greek letters. Changes in case do not always preserve normalization forms, an issue not limited to uppercase polytonic Greek. Furthermore, any proper Unicode implementation of a casing transformation should be designed to handle changes in the string length as needed. This issue is also not limited to Greek characters. For example, German “ß” maps to “SS” on uppercasing.
The normalization stability policy for the Unicode Standard requires that any string that is normalized must remain normalized. This makes adding composite Greek uppercase letters less useful: any new composite character for which all parts of its Decomposition_Mapping are already in Unicode would have to be decomposed under NFC, in what is called a “composition exclusion”. In other words, the new composite character would never appear in NFC text, completely obviating any rationale for encoding it in the first place.
In contrast, lowercase forms of uppercase Greek letters — regardless of whether the uppercase forms were represented as composites or sequences — would continue to normalize to the existing lowercase composites. Thus, there would be no appreciable gain from addition of new composites — just additional complication in implementations.
The original reasons for these casing gaps in Greek have to do with the history of polytonic Greek encoding and the patterns of expected occurrence or non-occurrence of various accents with uppercase Greek letters. More detailed explanation of that history can be found at this article by Nick Nicholas.