- Previous message: Peter Constable: "RE: hebrew font conversion"
- In reply to: Nick Nicholas: "Transliterating ancient scripts [was: ASCII and Unicode lifespan]"
- Next in thread: Andrew West: "Re: Transliterating ancient scripts"
- Reply: Andrew West: "Re: Transliterating ancient scripts"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
Nick Nicholas wrote at 1:52 PM on Sunday, May 22, 2005:
>from Dean Snyder:
>> Anyone who does original research in cuneiform knows the pedagogical
>> value of glyph reinforcement,
>
>arguably not plaintext
Cuneiform glyphs are no less plain text than text rendered in Latin glyphs.
See, for example, a screen shot of a plain text email containing encoded
cuneiform:
<http://www.jhu.edu/digitalhammurabi/news/cuneiform_email.html>
>> the analytical value of glyph interaction,
>
>not plaintext
Just one example - playful uses of glyphs, "glyphspiel" to coin a word,
are meaningless in transliteration. The laughing emoticon, :-D, does
not evoke the same imagery in Greek or Arabic transliteration.
Transliteration is lossy.
>> the value of programmatic script detection for text processing,
>
>assuredly not plaintext
Locating cuneiform text in mixed script environments is a trivial plain
text process if cuneiform is encoded; it's a practically impossible
process if not.
Transliteration is lossy.
>> and the
>> importance of both glyph-based restorations and glyph-based error
>> detection.
>
>not plaintext -- if you're discussing restorations and errors, you're
>staying close to the facsimile anyway.
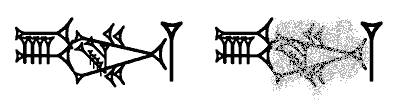
If a damaged cuneiform KUR sign (see attached} is transliterated in the
customary way, K[U]R, what do you know from the transliteration about
the original text?
Hebrew dalet and resh are sometimes confused, but you would never know
why if you were looking at them in transliterated Latin - d and r.
Transliteration is lossy.
>The acid test is, do publications of cuneiform routinely contain
>slabs of normalised printed cuneiform as text, without
>transliterations as a crutch?
First of all, since when is "routinely" a criterion for deciding whether
or not to encode.
Second, there are many cuneiform textbooks that do contain printed, un-
transliterated cuneiform signs.
Third, there are massive numbers of cuneiform texts published in non-
interpreted hand copies that will be of enormously greater benefit to
scholars when they were published as encoded cuneiform - they can then
be searched.
Fourth, there are over 500,000 known cuneiform texts in museums around
the world that have never been read by a modern human being - automated
character recognition into encoded cuneiform, i.e., NOT contextual
character interpretation (which is how the word "transliteration" is
used in cuneiform studies) will increase scholarly access by several
orders of magnitude.
>... there is a distinct
>lack of enthusiasm by a lot of scholars to normalising ancient script
>glyph repertoires
The operative word is "is". This will not be true in the future.
Respectfully,
Dean A. Snyder
Assistant Research Scholar
Manager, Digital Hammurabi Project
Computer Science Department
Whiting School of Engineering
218C New Engineering Building
3400 North Charles Street
Johns Hopkins University
Baltimore, Maryland, USA 21218
office: 410 516-6850
cell: 717 817-4897
www.jhu.edu/digitalhammurabi/
http://users.adelphia.net/~deansnyder/
- Next message: Dean Snyder: "Re: Transliterating ancient scripts [was: ASCII and Unicode lifespan]"
- Previous message: Peter Constable: "RE: hebrew font conversion"
- In reply to: Nick Nicholas: "Transliterating ancient scripts [was: ASCII and Unicode lifespan]"
- Next in thread: Andrew West: "Re: Transliterating ancient scripts"
- Reply: Andrew West: "Re: Transliterating ancient scripts"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
This archive was generated by hypermail 2.1.5 : Mon May 23 2005 - 12:26:22 CDT