- Previous message: asadek@st-elias.com: "Re: Coptic abbreviations"
- Maybe in reply to: Leiter Phelix: "Missing capital H from Unicode range (see 1E96)"
- Next in thread: Tom Gewecke: "Re: Missing capital H from Unicode range (see 1E96)"
- Reply: Tom Gewecke: "Re: Missing capital H from Unicode range (see 1E96)"
- Reply: Jukka K. Korpela: "RE: Missing capital H from Unicode range (see 1E96)"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
> From: unicode-bounce@unicode.org [mailto:unicode-bounce@unicode.org]
On Behalf
> Of Jukka K. Korpela
> Anyway, when you use U+0048 U+0331, you are asking programs to
construct a
> rendering by adding a line under to "H", whereas for E+1E96, programs
may
> use a glyph from a suitable font.
I don't know about anybody else's software, but in MS software both
would be assumed to be handled by using appropriate glyphs from a
suitable font.
> So the rendering mechanisms can be
> rather different. In current software, the dynamic construction of
> characters with diacritic marks is usually qualitatively poor and does
not
> really correspond to the Unicode standard's idea of such construction.
That generalization is not true of MS' current Windows and Office
software.
> I'm afraid there is not much you can do, except perhaps try another
> program and/or another font, if possible. (In a simple test, I noticed
> that using Arial Unicode MS, U+0048 U+0331 looks rather bad - the line
> under is positioned too much on the left
Well, I'm not sure what software or version of Arial Unicode MS you're
using. In current MS software, it comes out perfectly fine:
> As I wrote, I don't know this piece of history. But given the fact
that it
> has no code position now, it is very probable that it will not be
added.
Even stronger: it is certain that it will not be added.
Peter Constable
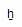
- Next message: Peter Constable: "RE: Arabic encoding model (alas, static!)"
- Previous message: asadek@st-elias.com: "Re: Coptic abbreviations"
- Maybe in reply to: Leiter Phelix: "Missing capital H from Unicode range (see 1E96)"
- Next in thread: Tom Gewecke: "Re: Missing capital H from Unicode range (see 1E96)"
- Reply: Tom Gewecke: "Re: Missing capital H from Unicode range (see 1E96)"
- Reply: Jukka K. Korpela: "RE: Missing capital H from Unicode range (see 1E96)"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
This archive was generated by hypermail 2.1.5 : Wed Jul 06 2005 - 17:14:27 CDT