|
|
Technical Reports |
| Version | 1 (draft 7) |
| Editors | Robin Leroy 𒉭 (eggrobin@unicode.org) |
| Date | 2024-02-27 |
| This Version | https://www.unicode.org/reports/tr56/tr56-2.html |
| Previous Version | https://www.unicode.org/reports/tr56/tr56-1.html |
| Latest Version | https://www.unicode.org/reports/tr56/ |
| Latest Proposed Update | https://www.unicode.org/reports/tr56/proposed.html |
| Revision | 2 |
This document outlines the need for ancillary data in the use of the Sumero-Akkadian Cuneiform script, and describes how the Oracc Global Sign List provides that data.
This is a draft document which may be updated, replaced, or superseded by other documents at any time. Publication does not imply endorsement by the Unicode Consortium. This is not a stable document; it is inappropriate to cite this document as other than a work in progress.
A Unicode Technical Report (UTR) contains informative material. Conformance to the Unicode Standard does not imply conformance to any UTR. Other specifications, however, are free to make normative references to a UTR.
Please submit corrigenda and other comments with the online reporting form [Feedback]. Related information that is useful in understanding this document is found in the References. For the latest version of the Unicode Standard see [Unicode]. For a list of current Unicode Technical Reports see [Reports]. For more information about versions of the Unicode Standard, see [Versions].
The Unicode Standard formally establishes the character identity of cuneiform signs by means of their names and representative glyphs in the code charts; see D2 in Section 3.3, Semantics, in [Unicode]. However, while the identity of abstract characters is well-established in the cuneiform script, the abstract characters are not usually referred to by standardized names, and the glyphic ranges of the abstract characters are vast and overlapping.
In practice, implementations of the script require an association of sequences of code points with entries in the classical sign lists that establish abstract character identity, and with the sign values which provide the usual names of these signs. Similar reliance on ancillary data may be found in other large scripts; see for instance Unicode Standard Annex #38, “Unicode Han Database (Unihan)” [UAX38].
This document briefly discusses the approach to the complexities of cuneiform sign identity taken by the encoding; it then describes the sign list maintained by the Open Richly Annotated Cuneiform Project (Oracc) which provides the ancillary data necessary to the effective use of the encoded script.
Assyriologists have published many sign lists, that is, classifications of the re◌́pertoire of cuneiform signs; these are numbered lists of signs, each illustrated with its glyphic range in the area and time period of interest, and often associated with a representative glyph from the Neo-Assyrian period and with the phonetic and logographic values of the sign. The sign lists play a similar role to the sources used in the CJKV or Tangut encodings.
Examples of such sign lists include [aBZL], [BAU], [ELLes], [HZL] [KWU], [LAK], [MÉA], [MZL], [aBZL], [PTACE], [RÉC], [RSP], [ŠL], and [ZATU]. Notably, [ŠL] and [MÉA] use the same numbering; however, the other sign lists have different numbering schemes.
The glyphic range of a sign is stylistic, encompassing for instance variation between lapidary inscriptions and cursive on clay tablets, regional variation, and variation between time periods. ; see This is illustrated in Figure 1, which shows glyphs given in [MÉA] for the sign NA 𒈾 in three styles:
Distinct glyphs for the same sign are not used contrastively, nor do they co-occur in texts that use a consistent style. In particular, for a given sign, the various phonetic and logographic values are not distinguished by contrasting glyphs.
Figure 1. Glyphs for the sign NA 𒈾 in (a) Old Babylonian lapidary style (b) Old Babylonian cursive style (c) Neo-Assyrian style, as shown in [MÉA].
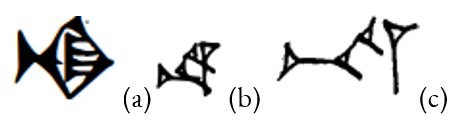
These signs are the abstract characters of the cuneiform script. See also point 5 in [ICE]. This approach makes it possible to encode texts known from multiple copies (so-called composite texts) that use different styles but consistent spellings, or to use encoded text to refer to the signs diachronically, as in dictionaries or sign lists covering broad timespans.
Texts are often published in transliterated form; the scheme for transliteration (and for the notation of sign values) originates with Thureau-Dangin’s [Syllabaire]. It uses numeric subscripts to distinguish homophones; the numbering of homophones is kept consistent across sign lists.
Note that accents can be used interchangeably with numbers (ú for u₂, ù for u₃), and additional information about the interpretation of signs is conveyed by capitalization and styling; a discussion of the specifics of assyriological transliteration is out of scope for this document.
Thanks to this numbering, a transliteration uniquely determines the sequence of signs of the original text. For example, the transliterations ib-bu-u₂ and ib-bu-u of distinct spellings of Akkadian ibbû “they named” are unambiguously transliterations of the sequences of signs 𒅁𒁍𒌑 and 𒅁𒁍𒌋, respectively. Note that while they share the phonetic value /u/, the signs U₂ 𒌑 and U 𒌋 are not stylistic variants of each other: they have distinct sets of values and meanings; for instance, 𒌑 means “grass” and 𒌋 means the number 10, meanings that are not shared with the other sign.
This relation between transliteration and abstract characters means that encoded cuneiform texts can be automatically generated from transliterated corpora. The reverse is not true; for instance, the sign 𒀸 might be transliterated aš, ina, or dil, depending on context.
A machine-readable format for cuneiform transliteration exists to facilitate such automatic processing of transliterated corpora. See [ATF].
Some signs can be analysed in all styles as a sequence of other signs written one after the other, and some sequences of signs have special values unrelated to their components; for instance, the sign GEME₂ 𒊩𒆳 is always written like the sign SAL 𒊩 followed by the sign KUR 𒆳, even as these signs change across styles; the sign DIRI 𒋛𒀀 is always written as SI 𒋛 followed by A 𒀀.
Such signs are not separately encoded; the corresponding sequences should be used to represent these abstract characters. See also items 2 and 5 in [Principles], and Complex and Compound Signs in Section 11.1, Sumero-Akkadian, of [Unicode].
Some signs have distinct glyphs in the styles of earlier periods, but identical glyphs in those of later periods; such occurrences are called mergers. Conversely, some signs have identical glyphs in the styles of earlier periods, distinct glyphs in those of later periods; such occurrences are called splits.
When encoding texts written in styles where the glyphs of merged or split signs are identical, the character corresponding to the correct sign value should be used, so that the encoding of a text is independent of the style in which it is written.
Figure 2 illustrates splits and mergers affecting four signs; note that a sign can be affected both by a split and a merger, as is the case of TI₂ 𒎗, which splits from DIN 𒁷 and merges with ḪI 𒄭. The source of the hand copy shown is given in each cell of the table.
Figure 2.
Mergers and splits of 𒊹, 𒄭, 𒎗, and 𒁷.
The source of the hand copy shown is listed in each cell.
| Early Dynastic IIIa | Ur III | Old Assyrian | Middle Assyrian | |
|---|---|---|---|---|
| 𒊹 ŠAR₂ |  [P010576] |
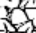 [P142296] |
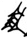 [P281820] |
|
| 𒄭 ḪI | 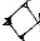 [P225950] |
 [P142296] |
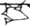 [P360975] |
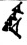 [P282017] |
| 𒎗 TI₂ |  [P142296] |
 [P360975] |
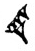 [P282017] |
|
| 𒁷 DIN | 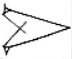 [P225950] |
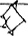 [P103303] |
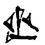 [P282017] |
This diachronic approach to the encoding means that characters newly encoded to represent a contrast present in some styles may need to be supported in fonts where that contrast is absent. For instance, after the sign 𒎌 MEŠ was encoded in Unicode Version 7.0 to represent the contrast with the sequence me-eš in Neo-Assyrian styles, as illustrated in Section 2.3.1, Mergers and Splits of Sequences, fonts for Old Babylonian styles had to be updated to support newly encoded Akkadian texts, even though the plural marker MEŠ looks identical to the sequence of syllables me-eš in Old Babylonian.
See also item 11 in [Principles], as well as Mergers and Splits in Section 11.1, Sumero-Akkadian, of [Unicode].
A special case of mergers and splits is that of signs that look like sequences of other signs in some styles, but have a different appearance (and are sometimes even used contrastively with the corresponding sequence) in other styles. In such cases, they are not considered as sequences as described in Section 2.2, Sequences, and are separately encoded.
For example, the sign MEŠ 𒎌 (an Akkadian plural marker) originally looks like the sequence of syllables me-eš 𒈨𒌍, but their appearance diverges in Neo-Assyrian styles, as shown in Figure 3. This is a split.
Note: As in the single-character case, the term split refers to the divergence of the visual representations of two fixed character sequences, here 𒈨𒌍 and 𒎌. That term does not refer to the phenomenon of a sign becoming a sequence of signs; indeed 𒎌 instead arose by two pre-existing signs coalescing into one.
Figure 3. The sequence me-eš 𒈨𒌍 and the sign MEŠ 𒎌 on a the Neo-Assyrian prism; photograph from [P422664].

As an example of a merger, the sign 𒋁, whose Sumerian readings include šeš₂ “to anoint” and še₈ “to weep”, initially looks distinct from the sequence of unrelated signs SIKI.LAM 𒋠𒇴, the first of which means “hair” and the latter a kind of tree; this is the case in the reference glyphs. However, in later styles, the sign ŠEŠ₂ 𒋁 has the same appearance as the sequence SIKI.LAM 𒋠𒇴.
Note: The term merger refers to the convergence of the visual representations of two fixed character sequences, here 𒋁 and 𒋠𒇴. As far as the scribes were concerned, the sign 𒋁 had broken up into a sequence of signs.
While the diachronic character identity used for the cuneiform encoding generally matches the understanding scribes had of character identity in their own script, there are discrepancies as scribes were not aware of mergers long past, let alone future splits. For example, some lexical texts describe explicitly the sign ŠEŠ₂ 𒋁 as being made up of the sequence 𒋠𒇴, see [P467315.r.i.22].
As mentioned in Section 2.1, Cuneiform Signs, sign lists typically use a Neo-Assyrian style for their reference glyphs, even when illustrating a different style.
However, because many signs are merged in the Neo-Assyrian style, this was an impractical choice for the reference glyphs in the code charts; instead these reference glyphs are primarily in an Ur III style, where most signs are distinct; where a sign is unattested in the Ur III period, or where signs appear identical in the Ur III period, a different style was chosen for the sake of distinctiveness of the reference glyphs. For example, the reference glyph for ŠAR₂ 𒊹 is in an Early Dynastic style, because that sign merges with ḪI 𒄭 by the Ur III period; the reference glyph for TI₂ 𒎗 is in a style that is Old Assyrian or newer, because it has not yet split from DIN 𒁷 in the Ur III period.
See also item 7 in [Principles], as well as Fonts in Section 11.1, Sumero-Akkadian, of [Unicode]
The names of the signs are generally based on a structural analysis of the signs, rather than on the common sign values; thus 𒄠 is described as GUD×KUR (𒄞×𒆳, meaning 𒆳 inscribed inside 𒄞), rather than AM. Note that this structural analysis may not be evident in all styles; see Figure 4.
Figure 4. Neo-Assyrian glyphs for AM 𒄠, GUD 𒄞, and KUR 𒆳 from [MÉA].
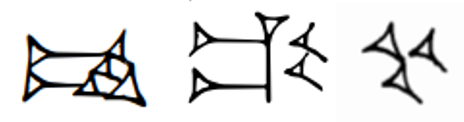
In some styles, the sign may even have a different structure from the one described by the name, as shown in Figure 5, where U+1224B 𒉋 CUNEIFORM SIGN NE SHESHIG (left) instead appears like NE×PAP 𒉈×𒉽. For comparison, the appearance of the sign NE 𒉈 on the same artifact is shown on the right.
Figure 5. Left: tThe signs BIL₂ 𒉋 and NE 𒉈 on the stele of Hammurapi [P249253]. Right: the sign NE 𒉈 on the same stele. In that style, BIL₂ appears as NE×PAP.
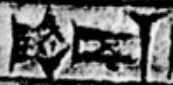
|

|
See also item 8 in [Principles].
On occasion, some sequences of signs may be combined in a ligature., as This is illustrated in Figure 6., where the signs 𒀭 and 𒂗 are ligated on the inscription on the left, but not on the inscription on the right. Such ligatures are not usually distinguished in transliteration from the corresponding sequences, so that both inscriptions would be transliterated ᵈsuen or ᵈEN.ZU; they and do not carry distinct semantics. They are not separately encoded; it is left to the font to display these if desired, possibly based on the presence of a zero-width joiner; see Cursive Connection and Ligatures in Section 23.2, Layout Controls, of [Unicode], and item 2 in [Principles]. When one needs to convey the ligature in transliteration, a plus sign is used, thus ᵈ⁺EN.ZU for the ligated example in Figure 6.
| [P226934] | [P232275] |
|---|---|

|

|
The Oracc Global Sign List [OGSL] (formerly Oracc Global Sign List, OGSL) associates signs with their encoding, with their values, and with their numbers in various sign lists; it can therefore be used to automatically produce encoded versions of transliterated texts as described in Section 2.1.1, Transliteration, to build input methods based on transliteration, and to look up the glyphic range of a sign in various styles.
The Oracc Global Sign List is available as the machine-readable file https://github.com/oracc/ogsl/blob/master/00lib/ogsl.asl. A specification of the structure of that file may be found at [ASL].
The Oracc Global Sign List treats the Unicode encoding as a sign list, and establishes a concordance with the other sign lists. However, while multiple OGSL signs may share the same number in the classical sign lists, a code point corresponds to at most one OGSL sign. This is a consequence of the principles described in Section 2.3, Mergers and Splits.
For example, the signs 𒁆 BALAG and 𒂀 DUB₂ both correspond to sign number 565 in [MZL] because they merge after the Ur III period, but they are encoded separately as they are distinct in earlier styles.
Not all signs in the OGSL correspond to a Unicode code point. Some signs are encoded as sequences, as described in Section Section 2.2, Sequences; the OGSL documents the appropriate sequence. Other signs have no documented encoding. Some of them may be candidates for encoding; however, as the OGSL is a working dataset, others may eventually be found to be misreadings, to be duplicates or variants of already-encoded signs, or to otherwise be unencodable.
Indeed, some signs in the OGSL, including some that are encoded in Unicode, are marked as deprecated, because they are the result of errors in the classification of cuneiform signs.
Some of these errors occurred as part of the encoding process. For example, the sign DUB×EŠ₂ 𒁿 does not exist; sign number 243 in [MZL] is named DUB׊E, but that was misread during encoding as DUB×ŠÈ (with a spurious grave accent,). The grave accent is equivalent to subscript 3), where and še₃ and eš₂ are values of the same sign 𒂠, so the misreading DUB×ŠÈ was encoded as DUB×EŠ₂.
Others are errors in earlier scholarship that were spotted after encoding. For example, the sign DUB׊E 𒍶, which represents sign number 243 in [MZL], does not exist; it was listed in [MZL] based on a misreading of actual tablets in [gaz₃]; it the sign appearing on these tablets should have been read GUM׊E 𒄤.
| [aBZL] | Catherine Mittermayer. Altbabylonische Zeichenliste der sumerisch-literarische Texte. 2006. |
| [ASL] |
Steve Tinney. “ASL/OGSL File Format”. Oracc Global Sign List. The OGSL Project, 2024.
http://oracc.org/ogsl/aslogslfileformat/ |
| [ATF] |
Steve Tinney & Eleanor Robson. “Working with ATF to edit texts”.
Oracc: The Open Richly Annotated Cuneiform Corpus. http://oracc.org/doc/help/editinginatf/index.html |
| [BAU] | Eric Burrows, Archaic Texts (Ur Excavations Texts 2; London 1935) |
| [ELLes] | Pietro Mander, “Lista dei segni dei testi lessicali di Ebla”, in Materiali epigrafici di Ebla 3, pp. 285-382. 1981. |
| [gaz₃] | Miguel Civil, “Bloc-notes: sa-gazₓ(DUB׊E)--ak.”, in Revue d’Assyriologie et d’archéologie orientale 60, p. 92. 1966. |
| [HZL] | Christel Rüster & Erich Neu, Hethitisches Zeichenlexikon (Harrassowitz Verlag 1989) |
| [KWU] | Nikolaus Schneider, Die Keilschriftzeichen der Wirtschaftsurkunden von Ur III (Rome 1935) |
| [LAK] | Anton Deimel, Liste der archaischen Keilschriftzeichen von Fara (Wissenschaftliche Veröffentlichungen der Deutschen Orient-Gesellschaft 40; Berlin 1922) |
| [MÉA] | René Labat, Manuel d'épigraphie akkadienne (6th ed. Paris 1988) |
| [MZL] | Rykle Borger, Mesopotamisches Zeichenlexikon (Alter Orient und Altes Testament 305; Ugarit-Verlag 2003) |
| [ICE] |
Dean A. Snyder. “Cuneiform: From Clay Tablet to Computer”. UTC document L2/00-398. |
| [OGSL] |
Niek Veldhuis, Steve Tinney, et al. “Oracc Global Sign List”.
Oracc: The Open Richly Annotated Cuneiform Corpus. http://oracc.org/ogsl/ |
| [P010576] |
“CDLI Lexical 000014, Ex. 013 & 000027, Ex. 14 Artifact Entry.” 2001.
Cuneiform Digital Library Initiative (CDLI).
December 4, 2001. https://cdli.ucla.edu/P010576 |
| [P103303] |
“AUCT 1, 458 Artifact Entry.” 2001.
Cuneiform Digital Library Initiative (CDLI).
December 20, 2001. https://cdli.ucla.edu/P103303 |
| [P142296] |
“YOS 04, 232 Artifact Entry.” (2001) 2023.
Cuneiform Digital Library Initiative (CDLI).
February 1, 2023. https://cdli.ucla.edu/P142296 |
| [P225950] |
“CDLI Lexical 000010, Ex. 014 Artifact Entry.” 2003.
Cuneiform Digital Library Initiative (CDLI).
August 19, 2003. https://cdli.ucla.edu/P225950 |
| [P226934] |
“RIME 3/2.01.04.22, Ex. 01 Artifact Entry.” (2003) 2023.
Cuneiform Digital Library Initiative (CDLI).
June 14, 2023. https://cdli.ucla.edu/P226934 |
| [P232275] |
“RIME 3/1.01.07, St B Witness Artifact Entry.” (2003) 2023.
Cuneiform Digital Library Initiative (CDLI).
June 14, 2023. https://cdli.ucla.edu/P232275 |
| [P249253] |
“RIME 4.03.06.Add21, Ex. 01 Artifact Entry.” (2004) 2023.
Cuneiform Digital Library Initiative (CDLI).
June 15, 2023. https://cdli.ucla.edu/P249253 |
| [P281820] |
“BAM 3, 314 Artifact Entry.” 2005.
Cuneiform Digital Library Initiative (CDLI).
November 11, 2005. https://cdli.ucla.edu/P281820 |
| [P282017] |
“KAJ 002 Artifact Entry.” 2005.
Cuneiform Digital Library Initiative (CDLI).
November 11, 2005. https://cdli.ucla.edu/P282017 |
| [P360975] |
“AAA 1/3, 01 Artifact Entry.” 2007.
Cuneiform Digital Library Initiative (CDLI).
February 13, 2007. https://cdli.ucla.edu/P360975 |
| [P422664] |
“RINAP 5/1 Ashurbanipal 010, Ex. 001 Artifact Entry.” (2011) 2023. Cuneiform Digital Library Initiative (CDLI).
February 1, 2023. https://cdli.ucla.edu/P422664 |
| [P467315.r.i.22] |
Niek Veldhuis, et al. YOS 01, 53, reverse i 22. “Digital Corpus of Cuneiform Lexical Texts”.
Oracc: The Open Richly Annotated Cuneiform Corpus. http://oracc.org/dcclt/P467315.210 |
| [Principles] |
Michael Everson & Karljürgen Feuerherm.
“Basic principles for the encoding of Sumero-Akkadian Cuneiform”. UTC document L2/03-162. |
| [PTACE] | Amalia Catagnoti, “La paleografia dei testi dell’amministrazione e della cancelleria di Ebla”. Quaderni di Semitistica 30. 2010. |
| [RÉC] | François Thureau-Dangin, Recherches sur l'origine de l'écriture cunéiforme (Paris 1898) |
| [RSP] | Yvonne Rosengarten, Répertoire commenté des signes présargoniques sumériens de Lagash (Paris 1967) |
| [ŠL] | Anton Deimel, Šumerisches Lexikon (Rome 1925/1950) |
| [Syllabaire] | François Thureau-Dangin, Le Syllabaire Accadien (Paris 1926) |
| [Unicode] |
The Unicode Standard Latest version: https://www.unicode.org/versions/latest/ |
| [UAX38] |
Unicode Standard Annex #38: Unicode Han Database (Unihan) Latest version: https://www.unicode.org/reports/tr38/ |
| [ZATU] | Margret W. Green and Hans J. Nissen, Zeichenliste der Archaischen Texte aus Uruk (Archaische Texte aus Uruk 2; Berlin 1987) |
Robin Leroy authored the bulk of the text, under direction from the Unicode Technical Committee.
Thanks also to the following people for their feedback or contributions to this document: Deborah Anderson, Peter Constable, Karljürgen Feuerherm, Asmus Freytag, Erica Scarpa, Steve Tinney, Niek Veldhuis, Ken Whistler, Ben Yang.
Revision 2
Revision 1