| Version | 3.6 |
| Authors | Misha Wolf, Ken Whistler, Charles Wicksteed, Mark Davis, Asmus Freytag, and Markus Scherer |
| Date | 2004-06-07 |
| This Version | http://www.unicode.org/reports/tr6/tr6-3.6.html |
| Previous Version | http://www.unicode.org/reports/tr6/tr6-3.5.html |
| Latest Version | http://www.unicode.org/reports/tr6/ |
This report presents the specifications of a compression scheme for Unicode and sample implementation.
This document is a proposed update of a previously approved Unicode Technical Standard. Publication does not imply endorsement by the Unicode Consortium. This is a draft document which may be updated, replaced, or superseded by other documents at any time. This is not a stable document; it is inappropriate to cite this document as other than a work in progress.
A Unicode Technical Standard (UTS) is an independent specification. Conformance to the Unicode Standard does not imply conformance to any UTS.
Please submit corrigenda and other comments with the online reporting form [Feedback]. Related information that is useful in understanding this document is found in [References]. The latest version of the Unicode Standard is found on [Unicode]. A list of current Unicode Technical Reports is found on [Reports]. For more information about versions of the Unicode Standard, see [Versions].
The compression scheme is mainly intended for use with short to medium length Unicode strings. The resulting compressed format is intended for storage or transmission in bandwidth limited environments. It can be used stand-alone or as input to traditional general purpose data compression schemes. It is not intended as processing format or as general purpose interchange format.
The following description is stated as an encoding of a sequence of Unicode characters as a compressed stream of bytes. It is therefore independent, for example, of whether the uncompressed data is encoded as UTF-8, UTF-16 or UTF-32 (also known as UCS-4 in ISO 10646). If the compressed data consists of the same sequence of bytes, it represents the same sequence of characters. The reverse is not true — there are multiple ways of compressing any character sequence.
While the description uses the term character throughout, no limitation to assigned characters is implied; in other words, SCSU is defined in terms of code points.
Some languages use a small repertoire of characters. Strings in such languages often contain runs of characters encoded close together in [Unicode]. These runs are typically interrupted only by punctuation characters, which are encoded in proximity to each other in Unicode, usually in the Basic Latin range.
The compression scheme sets up a so-called dynamically positioned window, which is a region of 128 consecutive characters in Unicode. This window can be positioned to contain the alphabetic characters in question. Each character that fits this window is represented as a byte between 0x80 and 0xFF in the compressed data stream, while any character from the Basic Latin range (as well as CR, LF, and TAB) is represented by a byte in the range 0x20 to 0x7F (as well as 0x0D, 0x0A or 0x09).
Runs of characters from a selected window which are intermixed only with characters from the range U+0020..U+007F can be compressed without requiring tag bytes beyond the initial setup of the window.
Tag bytes are bytes in the range 0x00 to 0x1F (except CR, LF, TAB) that are used as commands to select, define and position windows, or to escape to an uncompressed stream of Unicode text. Strings from languages using large alphabets use this uncompressed mode.
There are scripts for which the characters ordinarily show larger fluctuation in code values than can be contained in a dynamically positioned window. For these areas of the Unicode code space, windows cannot be set. Instead, an escape to uncompressed UTF-16 can be used.
It is possible to write a simple encoder for this scheme which uses a subset of the allowed tags. For example, it could use only SCU, SD0, UQU and UC0 and still achieve respectable compression with typical text. See Section 8.4, Minimal Encoder for further discussion and sample code.
Encoders should follow the recommendations in Section 8.3, XML Suitability so that they can be used to encode XML, HTML and similar document formats.
SCSU also does not attempt to preserve the binary ordering of strings, and is not MIME compatible, which limits its attractiveness as a processing format, particularly in databases, or as general purpose interchange format. If these features are required, a different compression scheme, such as [BOCU] could be employed.
| C1 | Decoders are required to accept and interpret the full range of tags and arguments defined here. The action of a conformant decoder on illegal or reserved input is undefined. |
| C2 | Conformant encoders must not emit illegal or reserved combinations of bytes. Encoders are not required to utilize (or be able to utilize) all the features of this compression scheme. Encoders must be able to encode strings containing any valid sequence of Unicode characters. The action of a conformant encoder on malformed input is undefined. |
| C3 | Encoders and decoders must always start in the initial state defined below. Encoders must remain in Single-Byte Mode at least until the first code point is encountered that is not U+0000 (NUL), U+0009 (HT), U+000A (LF), U+000D (CR), or U+0020..U+00FF (Latin-1), or an initial U+FEFF. See Section 8.1, Signature Byte Sequence for SCSU and Section 8.3, XML Suitability. |
| C4 | Conformance to SCSU requires conformance to Unicode 2.0.0 or later. |
Conformance to SCSU excludes the options in Section 10, Possible Private Extensions. A higher-level protocol could define an extended form of SCSU that implements these or other extensions to SCSU. Such a higher-level protocol requires a separate agreement between sender and receiver.
The compression scheme is capable of compressing strings containing any Unicode character. Some control character and private use character values overlap with the tag byte values. They can still be encoded, though at a cost of an additional byte per character.
There are two compression modes:
In single-byte mode, bytes between 00 and 1F are used as tags. The tags used in single-byte mode are shown in Table 1, their corresponding byte values are shown in Table 6.
| Name | Meaning | Arguments | Function |
|---|---|---|---|
| SQU | Quote Unicode | hbyte, lbyte | Quote Unicode character = (hbyte << 8) + lbyte. Used for isolated characters from the BMP that do not fit in any of the current windows. |
| SCU | Change to Unicode | Change to UTF-16 mode (locking shift). Used for runs of characters not part of a small alphabet |
|
| SQn | Quote from Window n . | byte | Non-locking shift to window n. If the byte is in the range 00 to 7F, use static window n. If the byte is in the range 80 to FF, use dynamically positioned window n. |
| SCn | Change to Window n | Change to window n (locking shift). Use static window 0 for all following bytes that are in the range 20 to 7F, or CR, LF, HT. Use dynamically positioned window n for all following bytes that are in the range 80 to FF. |
|
| SDn | Define Window n | byte | Define window position n as OffsetTable[byte], and change to window n. |
| SDX | Define Extended | hbyte, lbyte | Define window n in the supplementary codespace and change to
it. n = top 3 bits of hbyte. Window base = 10000 + (80 * remaining 13 bits of hbyte and lbyte). |
| Name | Meaning | Arguments | Function |
|---|---|---|---|
| UQU | Quote Unicode | hbyte, lbyte | Quote a Unicode BMP character. Used to quote tag bytes. |
| UCn | Change to Window n | Change to single-byte mode, window n (locking shift). Use static window 0 for all following bytes that are in the range 20 to 7F, or CR, LF, HT. Use dynamically positioned window n for all following bytes that are in the range 80 to FF. |
|
| UDn | Define Window n | byte | Define window position n as OffsetTable[byte], and change to window n. |
| UDX | Define Extended | hbyte, lbyte | Define window n in the supplementary codespace and change to
it. n = top 3 bits of hbyte Window base = 10000 + (80 * remaining 13 bits of hbyte and lbyte) |
Unicode character = DynamicOffset[n] + (xx - 80)
The values for the starting offsets of dynamically positioned windows can change. Their initial values are specified in Table 5. Bytes in the range 20 to 7F always represent the corresponding character from the Basic Latin block (U+0020 to U+007F). In addition, LF, CR and HT represent U+000A, U+000D and U+0009 respectively.
An SDn tag (or UDn tag) followed by an index byte repositions window n and makes it the active window. To keep the encoding compact, the positions of the dynamically positioned windows are defined via a lookup table. Each window definition tag in the byte stream is followed by one byte that is used as an index into this table. The set of legal positions is defined by the Window Offset Table shown in Table 3.
The first part of the Window Offset Table defines half blocks covering the alphabetic scripts, symbols and the private use area. The individual entries from F9 onwards cover the scripts that cross a half-block boundary, plus one useful segment of European characters. Some collections of miscellaneous symbols and punctuation also cross half-block boundaries, but these characters are likely to occur rarely, or in isolation. Therefore no special offsets for them are included here.
| Byte x | OffsetTable[x] | Comment |
|---|---|---|
| 00 | reserved | reserved for internal use |
| 01..67 | x*80 | half-blocks from U+0080 to U+3380 |
| 68..A7 | x*80+AC00 | half-blocks from U+E000 to U+FF80 |
| A8..F8 | reserved | reserved for future use |
| F9 | 00C0 | Latin-1 letters + half of Latin Extended-A |
| FA | 0250 | IPA Extensions |
| FB | 0370 | Greek |
| FC | 0530 | Armenian |
| FD | 3040 | Hiragana |
| FE | 30A0 | Katakana |
| FF | FF60 | Halfwidth Katakana |
offset = 10000 + (80 * ((hbyte & 1F) * 100 + lbyte))
where & is the bitwise AND operator and all values are in hexadecimal notation. After an extended window is defined each subsequent byte in the range 80 to FF represents a character from the supplementary codespace.
For example, when decoding SCSU into UTF-16, the bits in the two argument bytes following the SDX (or UDX) and a subsequent data byte map onto the bits in the resulting surrogate pair as shown in the following table:
| High Surrogate | Low Surrogate | ||||
|---|---|---|---|---|---|
| 110110wwwwwzzzzz | 110111yyyxxxxxxx | ||||
| nnnwwwww | zzzzzyyy | 1xxxxxxx | |||
| High Byte | Low Byte | Data Byte | |||
Unicode character = StartingOffset[n] + xx
The positions of static windows are as shown in Table 4 and cannot be changed. The static windows cover character ranges which contain characters that tend to occur in isolation and therefore are suitable for access via non-locking shifts. Static window 0 is also used when bytes following an SCn or UCn are in the range 20 to 7F.
| Window | Starting Offset | Major Area Covered |
|---|---|---|
| 0 | 0000 | (for quoting of tags used in single-byte mode) |
| 1 | 0080 | Latin-1 Supplement |
| 2 | 0100 | Latin Extended-A |
| 3 | 0300 | Combining Diacritical Marks |
| 4 | 2000 | General Punctuation |
| 5 | 2080 | Currency Symbols |
| 6 | 2100 | Letterlike Symbols and Number Forms |
| 7 | 3000 | CJK Symbols & Punctuation |
As in the general case of SCn, a following byte value in the range 80 to FF indicates use of dynamically positioned window 0.
Default positions are assigned based on the following criteria:
The choice of offsets makes it possible to handle most languages by requiring no more than the definition of one extra window, at the cost of a single byte. The default settings of the dynamically positioned windows are shown in Table 5. The static window positions are fixed and are shown in Table 4.
| Window | Starting Offset | Major Area Covered |
|---|---|---|
| 0 | 0080 | Latin-1 Supplement |
| 1 | 00C0 | (combined partial Latin-1 Supplement/Latin Extended-A) |
| 2 | 0400 | Cyrillic |
| 3 | 0600 | Arabic |
| 4 | 0900 | Devanagari |
| 5 | 3040 | Hiragana |
| 6 | 30A0 | Katakana |
| 7 | FF00 | Fullwidth ASCII |
Note: All conformant decoders that output UTF-8 or UTF-32 must be prepared to convert surrogate pairs to characters, even for the case SQU hbyte1 lbyte1 SQU hbyte2 lbyte2.
| Name | Value | Comment |
|---|---|---|
| pass | 00 | NUL |
| SQ0 - SQ7 | 01 - 08 | |
| pass | 09 | HT |
| pass | 0A | LF |
| SDX | 0B | |
| reserved | 0C | reserved for future use |
| pass | 0D | CR |
| SQU | 0E | |
| SCU | 0F | |
| SC0 - SC7 | 10 - 17 | |
| SD0 - SD7 | 18 - 1F | |
| pass | 20 - 7F |
The tag byte values used in Unicode mode are shown in Table 7. In this table MSB means that the byte value is used as the most significant byte of a two byte sequence representing a Unicode code point on the BMP. There are no restrictions on the values of the byte immediately following an MSB.
| Name | Value | Comment |
|---|---|---|
| MSB | 00 - DF | Start of a Unicode character |
| UC0 - UC7 | E0 - E7 | |
| UD0 - UD7 | E8 - EF | |
| UQU | F0 | |
| UDX | F1 | |
| reserved | F2 | reserved for future use |
| MSB | F3 - FF | Start of a Unicode character |
Where data streams are not tagged externally, it is useful to provide a signature at the beginning of the stream. For UTF-16, UTF-32 and UTF-8, this is done by using U+FEFF to allow identification of the text as Unicode and to distinguish little-endian from big-endian forms of UTF-16 and UTF-32.
Unlike the standard character encoding forms defined in [Unicode], SCSU does not have a single representation for U+FEFF. Depending on the implementation of an SCSU encoder, and depending on the following text, a leading U+FEFF character could be encoded as one of these initial byte sequences:
| Bytes | Commands | Comment |
|---|---|---|
|
Preferred |
||
|
0E FE FF |
SQU FE FF |
Single-byte mode Quote Unicode |
|
Not Recommended |
||
|
0F FE FF |
SCU FE FF |
Single-byte mode Change to Unicode |
|
18 A5 FF |
SD0 A5 FF |
Single-byte mode Define dynamic window 0 to 0xFE80 |
|
19 A5 FF |
SD1 A5 FF |
Single-byte mode Define dynamic window 1 to 0xFE80 |
|
1A A5 FF |
SD2 A5 FF |
Single-byte mode Define dynamic window 2 to 0xFE80 |
|
1B A5 FF |
SD3 A5 FF |
Single-byte mode Define dynamic window 3 to 0xFE80 |
|
1C A5 FF |
SD4 A5 FF |
Single-byte mode Define dynamic window 4 to 0xFE80 |
|
1D A5 FF |
SD5 A5 FF |
Single-byte mode Define dynamic window 5 to 0xFE80 |
|
1E A5 FF |
SD6 A5 FF |
Single-byte mode Define dynamic window 6 to 0xFE80 |
|
1F A5 FF |
SD7 A5 FF |
Single-byte mode Define dynamic window 7 to 0xFE80 |
It is recommended to use only the byte sequence <0E FE FF> for an initial U+FEFF character (0E is the "SQU" tag). This convention will assist receiving processes that use initial byte sequences to identify a data file or stream as being encoded in SCSU. Every SCSU encoder should write this particular initial byte sequence if a U+FEFF is encountered as the first character in the stream. Any further occurrences of this character may be encoded in the most compact way possible with SCSU.
Note: The recommended sequence is the only one that does not affect the state of the encoder or decoder, and may be safely stripped by a receiver even before initiating a decoder.
A process reading text from a file or stream could interpret the initial bytes <0E FE FF> as a signature for SCSU and assume that the file or stream is encoded in SCSU. The process or SCSU decoder may or may not strip the initial U+FEFF character from the resulting text. Any other encoding of an initial U+FEFF character, and any encoding of a U+FEFF after the initial character are normally interpreted as a ZWNBSP.
If the input text starts with a U+FEFF that is to be interpreted as a ZWNBSP, then an encoder or sending process may prepend the text with another U+FEFF which may be safely recognized as an SCSU signature and stripped by a receiving process. Otherwise, the initial ZWNBSP could be misinterpreted as a signature and stripped by a receiving process. This is equivalent to sending and receiving text in UTF-16 or UTF-32. A signature should not be used where a protocol specification, database design, or out-of-band information or similar specifies the encoding.
By using SCU plus an input string in UTF-16, almost all Unicode strings can be represented with the same number of bytes as their UTF-16 encoding plus 1 byte. Strings containing private use characters in which the MSB collides with the tag byte values are the exception. These characters must be quoted with SQU or UQU, requiring three bytes instead of two bytes per character. Therefore, an absolute upper limit of required SCSU length is three bytes per UTF-16 code unit. (See also Section 5.2.1, Quoting in Unicode Mode). This upper limit is reached only for strings of n characters containing at least n-1 private use characters, subject to the quoting requirement.
Because the characters requiring SQU or UQU are in the BMP, an SCSU encoded string is never required to be longer than four bytes per character. In other words, it is never longer than its UTF-32 encoding. For supplementary characters there is no need for a one byte overhead, because any supplementary character can be represented using four bytes in SCSU by using SDX. (See also Section 6.1.3, Extended Windows).
A Unicode string consisting entirely of certain control characters will take up twice as much space in SCSU than in UTF-8, since each control character must be individually quoted with SQ0. (See also Section 5.1, Single-Byte Mode).
All of these upper limits can be exceeded, if an encoder deliberately chooses a particularly inefficient representation, such as using SQU or UQU to quote each surrogate separately for characters in the supplementary codespace (see also Section 7.3, Surrogate Pairs), or inserting redundant tags.
Typical compression of average text is markedly better than the worst case behavior, and normal text is encoded with fewer bytes in SCSU than in either UTF-8 or UTF-16.
SCSU can be used for XML or HTML or similar documents if attention is paid to the in-document encoding declaration. The process emitting the document should place the encoding declaration at the earliest possible location, in front of any non-Latin-1 characters. Such documents can be parsed properly up to and including the encoding declaration, because many document parsers initially assume ASCII-compatible encodings. (See also Section F of XML 1.0.)
An SCSU encoder is XML-Suitable if it encodes all initial Latin-1 text (code points U+0000, U+0009, U+000A, U+000D, U+0020..U+00FF) in the shortest possible form. That is, it uses Single-Byte Mode without SQ0, SC0 or any other commands. This encodes initial Latin-1 text with the same bytes as with ISO 8859-1. It would be unusual for an SCSU encoder to not encode initial Latin-1 text in the shortest form, so most existing SCSU encoders are XML-Suitable.
If there were an initial U+FEFF indicating a Unicode encoding signature, it would be encoded with SQU (see Section 8.1, Signature Byte Sequence for SCSU). However, many HTML and XML parsers do not recognize Unicode encoding signatures other than for UTF-16, so such a signature should not be used with XML and HTML documents.
While it is straightforward to write an SCSU decoder, writing an encoder may seem complicated because there are many ways to encode the same text. The choices that are made for an implementation affect the achievable compression ratio.
However, it is quite simple to write a minimal SCSU encoder that still produces valid and reasonable, even XML-suitable, output. The scsumini.c sample C code demonstrates this; its encoder function consists of about 75 lines of C code and uses only one integer state variable (for single-byte versus Unicode mode and the current window). It uses most SCSU commands, including quoting from and switching to all pre-defined windows, but does not define dynamic windows and does not use any look-ahead.
This kind of encoder is generally sufficient for text with mostly Latin/Cyrillic/Arabic/Devanagari/Japanese characters and CJK ideographs.
Even an encoder with good compression performance is relatively easy to write. The following are tactics used:
Use all dynamic windows.
Using all dynamic windows is important for multi-script text because
redefining windows is expensive.
Use the current window if possible.
Output a single byte per character for as long as possible for maximum
compression.
Use a static window if a matching character is found.
Static windows are defined for punctuation, controls and combining marks and
similar characters. Using a static window avoids a switch from the current
dynamic window, which is likely to be needed for the following character,
and avoids using a dynamic window for relatively rare characters.
Switch to Unicode mode for uncompressible text.
SCSU does not provide for window definitions for the main Han and Hangul
character ranges, which are too large for effective use of dynamic windows.
The Unicode mode should also be used for large scripts using supplementary
code points.
Switch to an already-defined window if a matching
character is found.
Avoid defining a new window.
Quote a standalone character.
Some characters, like U+FEFF (used for the signature), specials (U+FFF0..U+FFFD)
and non-characters are always best quoted with SQU, for the same reasons as
using a static window (see above). Other standalone characters should also
be quoted, for example a single Telugu letter in Japanese text.
Define a new window for a string of compressible
characters.
When there is a string of characters that fit into the same new dynamic
window, then one should be defined so that text is compressed for which
there is not a predefined window. Simple tactics for choosing a window
number (for example, the least recently used one) and for choosing to define a
window rather than quoting characters (for example, two or more same-window
characters in a row) yield good results.
For optimal compression, an encoder would have to look ahead several characters and probably compare multiple alternatives for sections of the text. The compression of normal text may improve only by a relatively small percentage compared to the strategy outlined in the previous paragraph.
Sample text (9 characters)
Öl fließt
Unicode code points (9 code points):
00D6 006C 0020 0066 006C 0069 0065 00DF 0074
Compressed (9 bytes):
D6 6C 20 66 6C 69 65 DF 74
Sample text (6 characters)
Москва
Unicode code points (6 code points):
041C 043E 0441 043A 0432 0430
Compressed (7 bytes):
12 9C BE C1 BA B2 B0
Sample text (116 characters)
♪リンゴ可愛いや可愛いやリンゴ。半世紀も前に流行した「リンゴの歌」がぴったりするかもしれない。米アップルコンピュータ社のパソコン「マック(マッキントッシュ)」を、こよなく愛する人たちのことだ。「アップル信者」なんて言い方まである。
Unicode code points (116 code points)
3000 266A 30EA 30F3 30B4 53EF 611B
3044 3084 53EF 611B 3044 3084 30EA 30F3
30B4 3002 534A 4E16 7D00 3082 524D 306B
6D41 884C 3057 305F 300C 30EA 30F3 30B4
306E 6B4C 300D 304C 3074 3063 305F 308A
3059 308B 304B 3082 3057 308C 306A 3044
3002 7C73 30A2 30C3 30D7 30EB 30B3 30F3
30D4 30E5 30FC 30BF 793E 306E 30D1 30BD
30B3 30F3 300C 30DE 30C3 30AF FF08 30DE
30C3 30AD 30F3 30C8 30C3 30B7 30E5 FF09
300D 3092 3001 3053 3088 306A 304F 611B
3059 308B 4EBA 305F 3061 306E 3053 3068
3060 3002 300C 30A2 30C3 30D7 30EB 4FE1
8005 300D 306A 3093 3066 8A00 3044 65B9
307E 3067 3042 308B 3002
Compressed (178 bytes)
08 00 1B 4C EA 16 CA D3 94 0F 53 EF 61 1B E5 84
C4 0F 53 EF 61 1B E5 84 C4 16 CA D3 94 08 02 0F
53 4A 4E 16 7D 00 30 82 52 4D 30 6B 6D 41 88 4C
E5 97 9F 08 0C 16 CA D3 94 15 AE 0E 6B 4C 08 0D
8C B4 A3 9F CA 99 CB 8B C2 97 CC AA 84 08 02 0E
7C 73 E2 16 A3 B7 CB 93 D3 B4 C5 DC 9F 0E 79 3E
06 AE B1 9D 93 D3 08 0C BE A3 8F 08 88 BE A3 8D
D3 A8 A3 97 C5 17 89 08 0D 15 D2 08 01 93 C8 AA
8F 0E 61 1B 99 CB 0E 4E BA 9F A1 AE 93 A8 A0 08
02 08 0C E2 16 A3 B7 CB 0F 4F E1 80 05 EC 60 8D
EA 06 D3 E6 0F 8A 00 30 44 65 B9 E4 FE E7 C2 06
CB 82
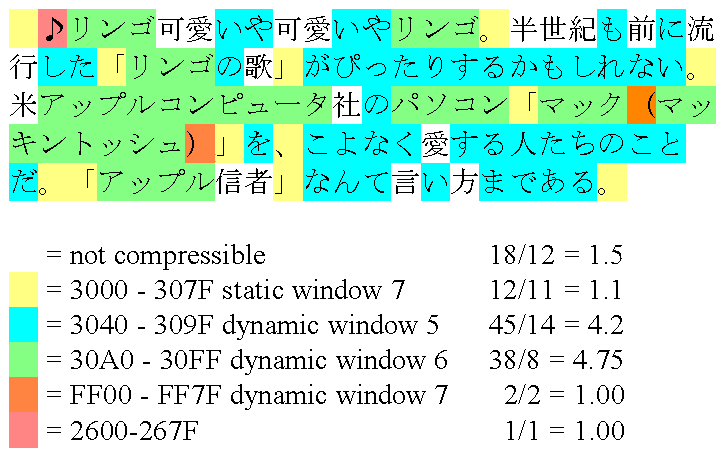
The example above consists of a short piece of text found in a Japanese news story. Each character is color coded to indicate which characters can be encoded using the same window. The table lists the number of occurrences of characters for a given window divided by the number of runs, yielding the average run length.
The reference encoder will encode the 116 characters of this example into 178 bytes. This is approximately 3/4 of the size required to store the text in UTF-16, or any of the double byte character sets. A single window implementation, like the original Reuters' RCSU version of the Compression scheme would have required about a dozen window resets, plus would have had to resort to quoting Unicode a few more times. A complex example like this demonstrates the advantage of the multiple window implementation quite nicely.
Unicode code points (18 code points):
0041 00DF 0401 015F 00DF 01DF F000 10FFFF 000D 000A 0041 00DF 0401 015F 00DF 01DF F000 10FFFF
UTF-16 code units (20 code units)
0041 00DF 0401 015F 00DF 01DF F000 DBFF DFFF
000D 000A 0041 00DF 0401 015F 00DF 01DF F000 DBFF DFFF
Compressed (35 bytes)
41 DF 12 81 03 5F 10 DF 1B 03 DF 1C 88 80 0B
BF FF FF 0D 0A 41 10 DF 12 81 03 5F 10 DF 13 DF 14 80 15 FF
With a simple re-mapping, the SCSU encoded data stream can be made free of most control byte values so that it can be passed where ASCII text is expected. This re-mapping is not as costly as more general schemes for converting binary data to text and leaves the text parts of compressed Latin-1 text fully readable.
After encoding, replace any control byte by DLE (0x10) followed by the original byte plus 0x40. NUL becomes DLE followed by '@' (0x40). DLE is replaced by DLE followed by U+0050. Before decoding, the opposite transformation must be performed.
Longer runs of the same character allow additional compression. Because this scenario is unusual, it was omitted from the standard algorithm. In situations where sender and receiver can agree on the additional specification and where runs are common, the following method is suggested:
Before encoding, replace any run of four or more Unicode characters by '@' (U+0040), followed by the character to repeat, followed by a 16-bit count (packed into one Unicode character). The sequence of 33 hyphens --------------------------------- becomes '@' '-' '!' (0x40, 0x2D, 0x21). Any occurrence of @ sign by itself is replaced by @@U+0001. After decoding, the reverse operation must be performed.
| [BOCU] |
BOCU-1: MIME-Compatible Unicode Compression |
| [FAQ] | Unicode Frequently Asked Questions http://www.unicode.org/faq/ For answers to common questions on technical issues. |
| [Feedback] | Reporting Errors and Requesting
Information Online http://www.unicode.org/reporting.html |
| [Glossary] | Unicode Glossary http://www.unicode.org/glossary/ For explanations of terminology used in this and other documents. |
| [Reports] | Unicode Technical Reports http://www.unicode.org/reports/ For information on the status and development process for technical reports, and for a list of technical reports. |
| [Unicode] | The Unicode Consortium. The Unicode Standard, Version 4.0. Reading, MA, Addison-Wesley, 2003. 0-321-18578-1. |
| [Versions] | Versions of the Unicode Standard http://www.unicode.org/standard/versions/ For details on the precise contents of each version of the Unicode Standard, and how to cite them. |
Note: none of the fixes imply a change to the specification.
The following summarizes modifications from the previous version of this document.
| 3.6 | Added 8.4 Minimal Encoder and 8.5 Encoder Strategies and the scsumini.c sample code. Many editorial changes, including a move of sections 8.1..8.3 to 7.2..7.5. Included the formerly linked details page for the Japanese Text Example (9.3) into this text directly. | ||||||
| 3.5 | Added recommendation to remain in Single-Byte Mode for initial Latin-1 text, and an informative section about the resulting XML suitability. | ||||||
| 1.0 - 3.4 | 1. Russian uses SC2 instead of SC7 as claimed in
the examples.
2. The 'All Features' example has been corrected. 3. A new Japanese example has been added. 4. Changed Table 3 from
to
to match the correct value used in the sample code. 5. Corrected 1FFF to 1F in the offset calculation equation for defining extended windows. 6. Corrected a few minor typographical errors [6/5/99]. 7. Corrected dynamic offset in for Window 1 in sample code to 0x00C0 to match Table 5 of specification (updated internal version number of SCSU.java to 005 and commented changed source line). 8. Changed methods in the expander from private to protected to support a minor update of the driver program. (Updated internal version number to 005 in Expand.java and added a comment). 9. Minor improvements to the driver program. (Updated internal version number to 005 in CompressMain.java) 10. Editorial reformatting. [11/12/99] 11. Added the section on use of signature and changed version to 3.1 (The sample programs have not been updated to implement this recommendation). 12. Fixed HTML validation error. [3/11/00] 13. Added an informative section on worst-case behavior [10/31/01]. 14. Changed references to 'expansion space' to 'supplementary coding space', to be more in line with terminology introduced in Unicode 3.1. 15. Clarified that the "Unicode" data in Unicode Mode is UTF-16BE. This clarification is necessary since later versions of the Unicode Standard add UTF-8 and UTF-32 on an equal basis. 16. Clarified that SCSU is an encoding of a sequence of code points, independent of the encoding form. This makes no change to the specification, since nothing in the original wording required the uncompressed data to be in UTF-16. 17. Clarified that SQU and UQU may only be applied to characters on the BMP, which are represented by two bytes in SCSU. 18. In 6.2.1, corrected
to
19. Corrected the example in section 10.2. 20. Changed styles and template. 21. Added section 2.3 to discuss limitations of SCSU. Added references. [05/08/02] 22. Changed "Unicode Values" to "code points" and made similar clarifications throughout. Added restriction to remain in Single-Byte Mode for initial Latin-1 text, and an informative section about the resulting XML suitability. |
Copyright © 1999-2004 Unicode, Inc. All Rights Reserved. The Unicode Consortium makes no expressed or implied warranty of any kind, and assumes no liability for errors or omissions. No liability is assumed for incidental and consequential damages in connection with or arising out of the use of the information or programs contained or accompanying this technical report.
Unicode and the Unicode logo are trademarks of Unicode, Inc., and are registered in some jurisdictions.