- Previous message: Doug Ewell: "Re: Nicest UTF"
- In reply to: Chris Jacobs: "Re: No Invisible Character - NBSP at the start of a word"
- Next in thread: Dean Snyder: "Re: No Invisible Character - NBSP at the start of a word"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
On 06/12/2004 00:54, Chris Jacobs wrote:
>>It may appear to your eyes to be an abuse of the orthography, just as to
>>others's eyes the distinct Qamats Qatan which you proposed seems to be
>>an abuse of the orthography. Nevertheless, both these kinds of
>>discrepancies and Qamats Qatan are actually used in a significant number
>>of publications. Indeed the blended Qere/Ketiv forms are in nearly every
>>Hebrew Bible written or printed over more than 1000 years. They may be
>>"abnormal" in some sense, but this is no argument for them not being
>>representable in Unicode.
>>
>>
>
>I don't believe this!
>
>Blending qere with ketiv in such a way that you can exacly tell which vowel goes with which consonant, that you distinguish between
>either two vowels below the first consonant or one of the two as a lonely vowel before the word, seems to me an artefact of the
>printing technique.
>
>Are there copies of written text where this can be checked?
>
>Copies of more than 1000 years old text would be ideal since that cannot imitate print.
>
>
>
This is ture, more or less. See the attached evidence from the Leningrad
Codex, dated 1006/7 CE so not quite 1000 years old. These images can be
tied up with some of the first few forms in
http://www.qaya.org/academic/hebrew/Ketiv-Qere-difficult.pdf. For 2
Samuel 21:9 I have also included an image from the Aleppo codex, which
is nearly a century older than Leningrad. Note how there is little
ambiguity about which vowel points go with which base character.
Some of these examples are not as clear as they might be because there
are no clear word spaces in the Leningrad codex. But the 2 Samuel 21:9
example happens to be at the start of a line in both codices, and so it
is quite clear that the hiriq before the first base character is not
associated with the last character of the previous word.
-- Peter Kirk peter@qaya.org (personal) peterkirk@qaya.org (work) http://www.qaya.org/
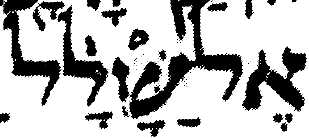
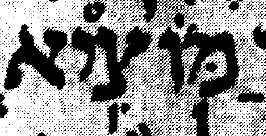

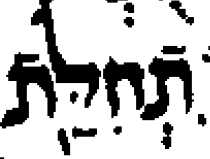
- Next message: Doug Ewell: "Re: OpenType not for Open Communication?"
- Previous message: Doug Ewell: "Re: Nicest UTF"
- In reply to: Chris Jacobs: "Re: No Invisible Character - NBSP at the start of a word"
- Next in thread: Dean Snyder: "Re: No Invisible Character - NBSP at the start of a word"
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ] [ attachment ]
- Mail actions: [ respond to this message ] [ mail a new topic ]
This archive was generated by hypermail 2.1.5 : Mon Dec 06 2004 - 10:26:16 CST