Updates and Errata
The following is a list of errata noted for
The Unicode®
Standard, Version 17.0, its code charts, annexes, the Unicode
Character Database, and the text and data files for other synchronized
specifications. It is periodically updated to include
corrections to typographic errors and new clarifications of the
text. This list also includes errata noted for the text of The Unicode Standard, Version 17.0—Core Specification.
Current Errata Notices
| Date |
Summary |
| 2026-02-03 |
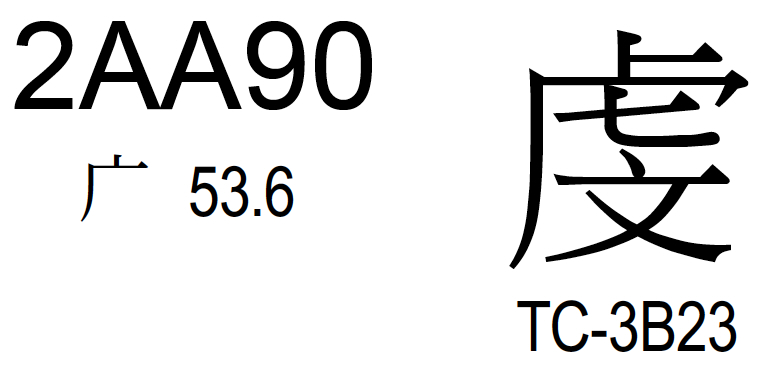
In the published code charts for Versions 6.1 through 17.0 of the Unicode Standard, the T-source representative glyph TC-3B23 for U+2AA90 is incorrect. The incorrect and correct representative glyphs are shown in the images below. The representative glyph will be updated in a future version of the standard. See 185-A91.
| Incorrect: |
 |
| Correct: |
 |
|
| 2026-02-03 |
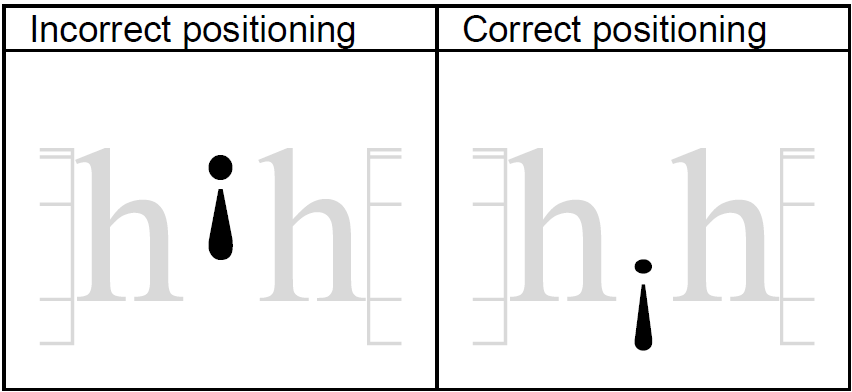
In the published code charts for Versions 5.1 through 17.0 of the Unicode Standard, the representative glyph for U+A71F MODIFIER LETTER LOW INVERTED EXCLAMATION MARK is incorrect. The incorrect and correct representative glyphs are shown in the images below, on the left and right respectively. The image includes grayed out characters beside U+A71F in order to better understand how low U+A71F should be in relation to the baseline. The representative glyph will be updated in a future version of the standard.
See 186-A058.
|
Reporting Errors
Reports of errors in published documents, such as the Unicode
Standard itself or Unicode Technical Reports, may be filed using the
Unicode Consortium's
contact form. If confirmed, and depending on the nature of the
reported error, a notice may be posted on this page, to be fixed
in subsequent editions of the Unicode Standard or related specifications.
Corrigenda Notices
Formal corrigenda notices for the Unicode Standard can be found at
Corrigenda to the Unicode Standard.
Unicode CLDR
Corrigenda for Unicode CLDR
are posted at
Unicode CLDR Corrigenda. Errata notices for Unicode CLDR and its related specification, UTS #35: Locale Data Markup Language (LDML) can be found in the various release notes accessed from the Unicode CLDR Downloads page. For information regarding filing and accessing bug reports for Unicode CLDR, see Unicode CLDR: Requesting Changes.
Archived Errata Fixed in Prior Unicode Versions
|
