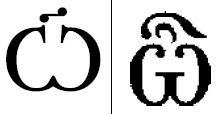|
|
Public Review Issues | Tech Site | Site Map | Search |
Resolved Public Review Issues 1-99
This page lists recent Public Review Issues numbered 1 - 99 which have been resolved, in reverse order by issue number. The link on the title points to a background document if any is available. For open issues, please see the Public Review Issues page. For later resolved public review issues, please see the next Resolved Issues page.
99 Proposed Draft UTR #33, Unicode Conformance Model 2007.01.30 The UTC has released an updated draft of the technical report describing the conformance model for the Unicode Standard. Review and feedback are welcome. Resolution: Closed 2007-02-15. The draft will be updated with feedback and published. 98 Ideographic Variation Database Submission 2007.03.15 The Ideographic Variation Database provides a registry for collections of unique variation sequences containing unified ideographs, allowing for standardized interchange according to UTS#37, Ideographic Variation Database. A submission to the Ideographic Variation Database has been received for: "Combined registration of the Adobe-Japan1 collection and of sequences in that collection". Details are in the background document. Resolution: Closed 2007-03-20. A new submission will be made to incorporate the feedback. 97 Proposed Draft UTR #38, A User's Guide to the Unihan Database 2007.05.08 The Unihan database is the repository for the Unicode Consortium’s collective knowledge regarding the CJK Unified Ideographs contained in the Unicode Standard. It contains mapping data and additional information to help implement support for the various languages which use the Han ideographic script. A new proposed draft UTR #38, A User's Guide to the Unihan Database, is available for public review and comment. Resolution: Closed 2007-05-29. The proposed draft UTR will move forward to become a draft UAX. 96 Allowing Joiner Characters in Identifiers 2007.05.14 The use of format characters in identifiers is problematical because the formatting effects they represent are considered merely stylistic or otherwise out of scope for identifiers. To make matters worse, it's possible to misapply format characters such that users can create strings that look the same but actually contain different characters. For these reasons format characters are normally excluded from Unicode identifiers. The background document discusses a proposal to allow joiners in identifiers in certain contexts. Background document updated 2007/04/30.
Resolution: Closed 2007-05-29. The text and rules resulting from the PRI will be incorporated into an appendix of UAX #31. 95 Stable Normalization Process 2006.10.31 The UTC is considering adding the specification of a "Stable Normalization Process" to UAX #15, Unicode Normalization Forms, and requests public feedback on the proposed specification. For details, see the background document. Resolution: Closed 2006-11-27. The UTC decided to produce a proposed update for UAX #15 that defines a "normalization process for stable strings" (NPSS), and post for review. 94 Proposed Update to UTS #10: Unicode Collation Algorithm 2006.07.31 Draft UTS #10 is available for public review. The main changes are the incorporation of informative material from UTN #9, and updated references to Unicode 5.0 and to UCA 5.0 data tables. Updated 2006.06.13. The data files for UCA 5.0 are now available for public review:
https://www.unicode.org/Public/UCA/5.0.0/allkeys-5.0.0.txt
https://www.unicode.org/Public/UCA/5.0.0/
The only changes compared to UCA 4.1 are:
- The addition of weights for Unicode 5.0 characters
- Changed weights for eight Unicode 4.1 characters:
a. to match new lowercase forms
Ⅎ U+2132 TURNED CAPITAL F
Ↄ U+2183 ROMAN NUMERAL REVERSED ONE HUNDRED
b. in accordance with feedback
ⵯ U+2D6F TIFINAGH MODIFIER LETTER LABIALIZATION MARK
c. reconciling multiple numeric variants within a script
৴ U+09F4 BENGALI CURRENCY NUMERATOR ONE
...
৷ U+09F7 BENGALI CURRENCY NUMERATOR FOUR
d. insuring last position in the script
് U+0D4D MALAYALAM SIGN VIRAMAResolution: Closed 2006-07-17, after formal approval of the UCA 5.0 draft by UTC letter ballot. 93 Representation of Malayalam /au/ Vowel in Traditional and Reformed Orthography 2006.05.09 The vowel /au/ in Malayalam is represented differently in the traditional and reformed orthographies. This public review issue relates to the representation of these vowels. Details are provided in the background document. Resolution: Closed 2006-05-30. After reviewing all feedback, the UTC decided to accept option "A" of the background document and use a different spelling between traditional and reformed orthographies for Malayalam vowel /au/. 92 Proposed Draft UTS #40: BOCU-1 MIME-Compatible Unicode Compression 2006.05.09 This document describes a Unicode compression scheme that is MIME-compatible, directly usable for e-mail, and preserves binary order (for databases and sorted lists). It replaces UTN #6 and adds a formal description of the algorithms, without substantially changing the specification. Resolution: Closed 2006-05-30. No action has been taken. The UTC thanks reviewers for their feedback. 91 Proposed Update to UAX #9: The Bidirectional Algorithm 2006.05.09 Conformance to the Unicode Bidi Algorithm (UAX #9) has been tightened in the area of bidi mirroring. The list of characters with the Bidi_Mirrored property has also been extended for consistency. Several other editorial clarifications have been made. Resolution: Closed 2006-05-30. The UAX will be updated and published for Unicode 5.0. 90 Unicode 5.0 Beta 2 2006.05.09 The Unicode Consortium has decided to issue Beta 2 of the Unicode Character Database for Unicode 5.0. This extends the feedback period until May 9, 2006. The relevent public review issues for UAXes have also been extended to the same date. Some information on changes and updates to the UAX #9 beta will be announced soon. Data files will also be updated during this period. During the extended beta review period for Unicode 5.0, the UTC is seeking feedback on potential errors or inconsistencies in all of the data files. However, please note that some of the character properties will be frozen as of March 1. The freeze will apply to all properties defined in the following files: UnicodeData.txt, Scripts.txt, and EastAsianWidth.txt; to a specific list of properties from PropList.txt (White_Space, Hex_Digit, Diacritic, and Ideographic); and to two derived properties, Numeric_Value and Numeric_Type. Substantive feedback received after March 1 regarding any of those properties will be recorded and taken into consideration in review of future versions of the standard, but will not be reflected in modifications for Unicode 5.0.
The Unicode 5.0 beta data files are available at https://www.unicode.org/Public/5.0.0/ucd/. General information regarding these data files is available at https://www.unicode.org/Public/5.0.0/.
Resolution: Closed 2006-05-30. The UTC thanks reviewers for their feedback. 89 Proposed Update to UTR #23: Unicode Character Property Model 2006.05.09 This proposed update reflects changes to the definitions that are planned for the forthcoming Unicode Version 5.0 and includes a new section on the difference between code point properties and abstract character properties. Resolution: Closed 2006-05-30. The UTR will be updated and published. 88 Proposed Update to UAX #14: Line Breaking Properties 2006.05.09 The UTC has modified the conformance clauses of UAX #14 and the text they reference. These changes clarify precisely what is tailorable in conformant implementations and what is not. The non-tailorable results are limited to interactions among a small set of well-defined core characters, such as CR, LF, NBSP, SP, and so on, where the semantics of the characters is bound up in how they linebreak. Please see the background document for details of other changes and items to review.
Resolution: Closed 2006-05-30. The UAX will be updated and published for Unicode 5.0. 87 Proposed Update to UAX #24: Script Names 2006.05.09 This proposed update contains a proposed change in default script value for unassigned characters from Common to a new value Unknown, and a correction for the contents of the Script=Inherited value. Resolution: Closed 2006-05-30. The UAX will be updated and published for Unicode 5.0. 86 Proposed Update to UAX #15: Unicode Normalization Forms 2006.05.09 There are no substantive changes in this version of UAX #15. Sections were added to clarify stability and versioning issues, and to make some formatting changes for Unicode 5.0. Resolution: Closed 2006-05-30. The UAX will be updated and published for Unicode 5.0. 85 Proposed Update to UAX #31: Identifier and Pattern Syntax 2006.05.09 Clarifying text has been added for ideographs and the use of additional characters in identifiers. Resolution: Closed 2006-05-30. The UAX will be updated and published for Unicode 5.0. 84 Proposed Update to UAX #29: Text Boundaries 2006.05.09 A number of changes have been made to simplify implementations and cover edge cases in the rules. Resolution: Closed 2006-05-30. The UAX will be updated and published for Unicode 5.0. 83 Changing Glyph for U+047C/U+047D Cyrillic Omega with Titlo 2006.08.01 UTC has received information indicating that the glyphs for U+047C and U+047D should be changed. In the accompanying figure below, the current shape is shown on the left. The proposed new shape is shown on the right. UTC will move to implement this change if no information to the contrary is received by the end of the review period.
Resolution: Closed 2006-08-22. Cyrillic Omega with Titlo is left unchanged. The assessment of the UTC is that changing the glyph to be the glyph for "beautiful omega" is inappropriate, and any such character should be encoded separately. 82 Representation of Gurmukhi Double Vowels 2006.01.30 In older Gurmukhi, some texts use two vowel signs on a single consonant; for example, one can find ga with both the oo and u vowel signs. A priori, this can be represented in Unicode using two different sequences. Details of a proposal regarding this situation is found in the background document. Resolution: Closed 2006-03-03. UTC decided to use the first sequence, top then bottom, for Gurmukhi double vowels. 81 Proposed Update to UAX #34: Unicode Named Character Sequences 2006.05.09 A provisional process for the approval of named character sequences has been added to the text of this UAX. A data file containing provisional named character sequences is now available, separate from the list of approved named character sequences. See: https://www.unicode.org/reports/tr34/tr34-4.html Please review the provisional entries in NamedSequencesProv.txt, as well as the proposed text of the update. Resolution: Closed 2006-05-30. The UAX will be updated and published for Unicode 5.0. 80 Proposed Update to UAX #9: The Bidirectional Algorithm 2006.01.30 The Unicode Bidi algorithm has allowed for a great deal of flexibility in determining which characters are to be mirrored (see HL6 https://www.unicode.org/reports/tr9/tr9-16.html#HL6). Unfortunately, that means that text that originates with one person may show up with the wrong graphic to another, thus causing the text to be misinterpreted. The proposal is to tighten up conformance by eliminating overriding of bidi mirroring, and at the same time extending the characters with the Bidi_Mirrored property. The UTC would like public feedback on whether to make this change, and which characters should have the Bidi_Mirrored property. The proposed change is to retain the set of characters currently having Bidi_Mirrored property, and add some additional characters with similar properties. For further information and character lists, see the background document for this issue.
Resolution: Closed 2006-02-25. Some changes were made in the draft as a result of feedback and UTC decisions. A new public review issue will be posted. 79 Proposed Updates to UAX #29: Text Boundaries and UAX #31: Identifier and Pattern Syntax 2005.10.28 There are some small changes to these two UAXes. In particular, clarifying text has been added to indicate that identifiers which are intended to represent words of natural languages should take into account some additional characters such as hyphens, apostrophes, and joiners. See:
https://www.unicode.org/reports/tr29/tr29-10.html
https://www.unicode.org/reports/tr31/tr31-6.htmlResolution: Closed 2005-12-08. Some changes were made in the drafts as a result of feedback and UTC decisions. New public review issues will be posted for both UAX #29 and UAX #31. 78 CLDR 1.4 Design Phase 2005.11.07 The design phase for CLDR 1.4 has made a number of structural additions to LDML, including flexible date/time formatting; tailorable text segmentation (e.g. word/line breaks), rule-based number formats, and transforms (transliterations); additional LDML metadata; localized names of measurement systems; and localized calendar quarters. See the latest working draft at https://www.unicode.org/reports/tr35/tr35-6.html. Feedback on these additions is welcome. Note: it should not be provided via the online Unicode forms; instead,
use the CLDR bug reporting: https://www.unicode.org/cldr/filing_bug_reports.html.Resolution: Closed 2005-12-09. 77 Proposed Draft UTS #39 and Proposed Update UTR #36 2005.10.28 The sections of UTR #36: Unicode Security Considerations that pertain to security functions have been split off into a new proposed draft UTS #39: Unicode Security Mechanisms. In addition, a section on some of the problems with language-based security has been added to UTR #36. We would appreciate feedback on the proposed changes, and comments on the security issues highlighted in UTR #36. See:
https://www.unicode.org/reports/tr36/tr36-4.html
https://www.unicode.org/reports/tr39/tr39-1.htmlResolution: Closed 2006-02-16. Proposed Draft UTS #39 will be finalized to UTS #39 after incorporation of feedback. Proposed Update UTR #36 will be updated and posted for another round of public feedback. 76 Draft UTS #37, Ideographic Variation Database 2005.10.28 The UTC approved the development of a Unicode Technical Standard establishing a database of variation sequences for Ideographic characters. The UTC recognizes that the needs of various user communities for such variation sequences cannot be accommodated by a single, unified collection of sequences. The purpose of the database is to ensure that multiple collections can coexist without compromising the interchangeability of texts using them. This draft Unicode Technical Standard describes the operation of the database. Resolution: Closed 2005-12-08. The draft was approved as a UTS. 75 Proposed Update UTR #25, Unicode Support for Mathematics 2007.01.30 UTR #25, Unicode Support for Mathematics, is being updated to account for recent and pending additions to the character repertoire of mathematical characters in the Unicode Standard. Draft refreshed on 2007-01-30.
Resolution: Closed 2007-02-15. The draft will be published after incorporation of feedback and updates. 74 Change to Default Localization for NaN in CLDR 2005.10.31 There has been a request to change the default localization for a NaN from the character U+FFFD (�) REPLACEMENT CHARACTER to another representation. The NaN floating-point value means "Not a Number", and represents an undefined result of a mathematical operation such as (0 ÷ 0) or (∞ - ∞). Unfortunately, there is no generally accepted mathematical symbol for NaN (e.g., from the American Mathematical Society). The character currently used as the default (root) localization follows Java usage, where it was originally chosen because it is a symbol (thus not an English-specific abbreviation), and has a sense that roughly corresponds to NaN. The CLDR technical committee is somewhat reluctant to make a change, given that this has been in use in Java for many years. If there is a change, possibilities are to revert to the English abbreviation "NaN" or to chose another character such as U+26A0 (⚠) WARNING SIGN. The committee would appreciate comments on this issue. Resolution: Closed 2005-12-09. 73 Representative Glyphs for Arabic Characters U+06DF, U+06E0, and U+06E1 2005.08.09 The representative glyphs for several Arabic characters used to annotate the Koran have been reported as being possibly incorrect. The UTC has tentatively decided to revise them as explained in the accompanying document. The UTC invites anyone knowledgeable in their use to provide additional information or recommendations. Resolution: Closed 2005-08-17. UTC will change the representative glyphs for 3 characters (U+06DF, U+06E0, and U+06E1), but not for U+06E9. UTC intends to document glyphic variations of U+06E9 in a future version of the standard. 72 Stability of the Bidi Mirrored Property 2005.08.09 In a bidirectional context, the images of many characters need to be oriented depending on the writing direction of the text in which they occur. The Bidi Mirrored property defines this behavior, but the model it implements has a few inconsistencies. Ideally, these would be corrected, but doing so will destabilize all documents containing the affected characters. A stability policy would freeze future changes, but should one last round of improvements be carried out? Your input on the range of possible actions is solicited, whether you are a language expert, user. or implementer. Resolution: Closed 2005-08-17. UTC chose option B of the background document and will issue a Proposed Update UAX #9 to clarify section 6, and a new Public Review Issue will be posted on the specific content of the Bidi Mirroring property. 71 Questions on Malayalam Digits 2005.08.09 It has come to the attention of the UTC that the glyph printed in the standard for U+0D66 MALAYALAM DIGIT ZERO is incorrect, and information is being sought. Three numeric signs have been identified for future encoding, and further information is being sought. Details on these questions are in the accompanying document. Resolution: Closed 2005-08-17. UTC accepted the glyph change for U+0D66, and also accepted the Malayalam numeric signs for 1/4, 1/2, and 3/4 as well as 10, 100, 1000 for encoding in a future version of the standard. (Details of the encoding status and progress may be followed on the Pipeline page.) 70 Proposed Draft UTS #37, Registration of Ideographic Variation Sequences 2005.08.09 The UTC approved the development of a Unicode Technical Standard establishing a registry of variation sequences for Ideographic characters. The UTC recognizes that the needs of various user communities for such variation sequences cannot be accommodated by a single, unified collection of sequences. The purpose of the registry is to ensure that multiple collections can coexist without compromising the interchangeability of texts using them. This proposed draft Unicode Technical Standard describes the operation of the registry. Resolution: Closed 2005-08-17. Proposed Draft UTS #37 will be advanced to Draft, and a new PRI will be posted when it is available. 69 Proposed Update UAX #24, Script Names 2005.08.09 This is an initial update for Unicode 5.0.0 which proposes the addition of an appendix of iconic script indicators, derivative from the usage of last resort font missing glyph forms. Additional updates will be needed to reflect the planned additions of scripts to 5.0.0. Those will be in a subsequent draft. Resolution: Closed 2005-08-17. The appendix with a list of iconic indicators will be removed from the UAX. 68 Proposed Update UTS #10 Unicode Collation Algorithm 2005.04.26 The Unicode Technical Committee has released a beta version of UTS #10 Unicode Collation Algorithm (UCA) Version 4.1.0. It is available for public review until April 26. This is a running beta; the data files may be updated during the course of the beta. This beta provides a data table that is synchronized with the repertoire of Unicode 4.1.0. In addition, it includes:
- a revised handling of Thai/Lao via contractions
- enhancements to sorting and matching, with a new conformance clause
- changes to the handling of ignorable characters
- guidelines on the use of grapheme joiner
- new introductory text on user expectations
- changes in weights for a small number of characters.
See: https://www.unicode.org/Public/UCA/4.1.0/ for the data files.
Resolution: Closed 2005-05-06. The proposed update was approved. The draft and ancillary files have been updated and published. The final released revision number is 14, available here: https://www.unicode.org/reports/tr10/tr10-14.html. 67 CLDR Version 1.3 Beta (Updated 2005.04.22) 2005.05.10 The 1.3 version of CLDR is now at at beta status, and available via http://unicode.org/cldr/version/1.3.html. The new features include addition of data for timezones, UN M.49 regions, POSIX-format data, LDML meta-data, language/script/territory mappings, new tests, and various other fixes and additions of data, and many extensions to the specification. A new survey tool is being used to vet the additions of data. We encourage people to look at the data and provide feedback, especially on the new POSIX-format data and the changes in the specification. For details on accessing CLDR data, see http://unicode.org/cldr/repository_access.html. NOTE: Feedback should not be provided via the online Unicode forms; instead,
use the CLDR bug reporting method: http://unicode.org/cldr/filing_bug_reports.html.Resolution: Closed 2005-05-19. The review period has ended. 66 Encoding of Chillu Forms in Malayalam 2005.05.03 The UTC is considering the question of encoding 5 "chillu" forms in Malayalam. A brief explanation is in the above-linked background document. Feedback and detailed information on this issue is being sought. (Note: as with other Public Review Issues, this is not a "vote". Submissions that simply favor one approach or another without giving any evidence either way will not be considered by the committee.) Resolution: Closed 2005-05-18. The UTC accepted the 5 chillu forms for Malayalam, for encoding in a future version of the standard. Also accepted was a sixth chillu form for "ka". 65 Encoding of Devanagari Eyelash Ra 2005.05.03 The UTC is considering the question of encoding a separate character for the Devanagari eyelash RA, ( ). Reviewers may refer to discussion in The Unicode Standard, Version 4.0, pages 226 and 230. There is no separate background document. Feedback and detailed information on this issue is being sought. (Note: as with other Public Review Issues, this is not a "vote". Submissions that simply favor one approach or another without giving any evidence either way will not be considered by the committee.)
Resolution: Closed 2005-05-18. The UTC has not seen pervasive problems with the representation of eyelash ra. Therefore based on concerns for stability, the UTC re-affirms its position that eyelash ra is represented as indicated in Rule R5 in Section 9.1 Devanagari of The Unicode Standard, Version 4.0. 64 Draft UTR #36: Security Considerations for the Implementation of Unicode and Related Technology 2005.05.03 This draft Unicode Technical Report describes security considerations that are important to be aware of when working with Unicode, and provides specific recommendations for dealing with the issues that arise. Resolution: Closed 2005-05-18. The UTC decided to issue an approved version after resolution of open issues by the newly-formed security subcommittee. 63 POSIX Data for CLDR 2005.03.31 There is a new tool that creates POSIX locale data files from CLDR. It has been used to generate draft POSIX locale data files for public review. The CLDR Technical Committee is seeking review of this data. Details and relevant URLs are in the above-linked background document. Note that the CLDR 1.3 freeze date has also been extended. Please see http://unicode.org/cldr/version/1.3.html. Resolution: Closed 2005-05-19. The review period has ended. 62 Proposed Update UTS #10 Unicode Collation Algorithm 2005.01.31 A proposed update for UTS #10: Unicode Collation Algorithm (UCA) for Unicode 4.1.0 is available for public review. The main feature is the update of the repertoire to Unicode 4.1.0 (for synchronization, UCA 4.1.0 will be available within the month after Unicode 4.1.0). Other changes include:
- Use of ignorable character (especially CGJ) to interrupt contractions
- Changing the mechanism for reordering Thai/Lao characters to use contractions
- More detail about alternatives for handling Hangul characters
- Additional options in Searching and Sorting
- The data tables are not yet available, but the changes can be summarized as: assignments for all new 4.1.0 characters, additions of Thai/Lao contractions, plus changes in the weighting of certain Latin characters, some previously ignorable characters, and modifications of certain other Thai characters.
Resolution: Closed 2005-02-14. The proposed update was approved with changes incorporating editorial and other feedback. Proposals for some extensive changes were not accepted. The draft and ancillary files will be updated and published. 61 Proposed Update UAX #15 Unicode Normalization Forms 2005.01.31 A proposed update to UAX #15 for Unicode 4.1.0 is available at the link above. The proposed changes are listed in the Modifications section of the document. Resolution: Closed 2005-02-14. The proposed update was approved and will be published as part of Unicode 4.1.0. Some editorial feedback will be included; proposals for some extensive changes were not accepted. 60 Proposed Update UAX #9 Bidirectional Algorithm 2005.01.31 A proposed update to UAX #9 for Unicode 4.1.0 is available at the link above. The proposed changes are listed in the Modifications section of the document. Resolution: Closed 2005-02-14. The proposed update was approved, with some changes incorporating feedback, and will be published as part of Unicode 4.1.0. 59 Disunification of Dandas 2005.05.03 The UTC is considering the question of disunifying the characters U+0964 DEVANAGARI DANDA and U+0965 DEVANAGARI DOUBLE DANDA from their counterparts in several other Indic scripts. Feedback on this issue, including evidence, for or against the disunification, is being sought. Details are in the background document linked above. (Note: as with other Public Review Issues, this is not a "vote". Submissions that simply favor one approach or another without giving any evidence either way will not be considered by the committee.) Resolution: Closed 2005-05-18. The UTC has not seen pervasive problems caused by the unification of dandas in the core scripts of India. Therefore based on concerns for stability, the UTC re-affirms its position that dandas are unified across these scripts.. 58 Characters with cedilla and comma below in Romanian language data 2005.01.31 The CLDR Technical Committee is seeking feedback regarding the relative frequency of use of the characters with comma below and of the characters with cedilla in Romanian language textual material in widespread implementations, such as databases and operating systems, and in published documents and Romanian websites. The purpose for this feedback is to determine which to use in a default set of locale data for Romanian to be specified for CLDR.
The characters in question are:
U+0219 LATIN SMALL LETTER S WITH COMMA BELOW and
U+021B LATIN SMALL LETTER T WITH COMMA BELOWversus:
U+015F LATIN SMALL LETTER S WITH CEDILLA and
U+0163 LATIN SMALL LETTER T WITH CEDILLAPlease accompany your feedback with information on the source of your data and indicate the extent and nature of your experience with Romanian data processing. Note: There is no other background document for this item.
Resolution: Closed 2005-02-22. The resolution was to use the more distinctive characters, since users of the repository can map the characters together if they want.. 57 Changes to Bidi categories of some characters used with Mathematics 2005.01.31 The UTC is considering changing the bidi category of seven compatibility characters from "ET" to "ES": U+207A SUPERSCRIPT PLUS SIGN
U+208A SUBSCRIPT PLUS SIGN
U+FB29 HEBREW LETTER ALTERNATIVE PLUS SIGN
U+FE62 SMALL PLUS SIGN
U+FE63 SMALL HYPHEN-MINUS
U+FF0B FULLWIDTH PLUS SIGN
U+FF0D FULLWIDTH HYPHEN-MINUSThe UTC is also seeking feedback on the bidi categories of the following characters, and whether to also change these from "ET" to "ES":
U+2212 MINUS SIGN
U+207B SUPERSCRIPT MINUS
U+208B SUBSCRIPT MINUSAll of these characters may be used in connection with mathematical applications. Note: There is no other background document for these proposed changes.
Resolution: Closed 2005-02-14. The changes to all ten characters were approved and will be published as part of Unicode 4.1.0. 56 Proposed Update UAX #14 Line Breaking Properties 2005.01.31 This is a proposed update to a previously approved Unicode Standard Annex. It incorporates some changes in Hangul syllable rules, word separators, U+00A0 as a base for combining marks, and other updates. The UTC is seeking public feedback on these changes. Resolution: Closed 2005-02-14. The proposed update was approved with minor editorial changes and will be published as part of Unicode 4.1.0. 55 Proposed Change to Character Properties for Two Katakana Characters 2004.11.08 The UTC has received to change the General Category of two characters. Reports indicate that they should not have the General Category "Connector Punctuation" (gc=Pc) because the characters don't connect other elements, they separate elements. The two characters are: U+30FB KATAKANA MIDDLE DOT
U+FF65 HALFWIDTH KATAKANA MIDDLE DOTThe proposal is to change the General Category of those characters from "Pc" (Connector Punctuation) to "Po" (Other Punctuation). (Note: there is no other background document for this issue.)
Resolution: Closed 2004-11-23. The change in General Category of U+30FB KATAKANA MIDDLE DOT and U+FF65 HALFWIDTH KATAKANA MIDDLE DOT from "Pc" to "Po" was accepted and will be documented in Unicode 4.1. 54 Proposed Update UTS #22 Character Mapping Markup Language 2005.01.31 This is a proposed update to a previously approved Unicode Technical Report. It will change to a Unicode Technical Standard, so the update includes a new conformance section. Included in the update are many editorial changes and explicit text about multiple-character mappings. Resolution: Closed 2005-02-14. The proposed update was approved with minor editorial changes and will be published. 53 Proposed Draft UTR #33 Unicode Conformance Model 2005.05.03 This proposed draft Unicode Technical Report explains the issue of conformance relating to the Unicode Standard so that users better understand the contexts in which products are making claims for support of the standard, and implementers better understand how to meet the formal conformance requirements while satisfying the expectations of their users. It does not alter, augment or override the actual Unicode conformance requirements. Rather it attempts to provide a conceptual framework to make it easier for users and implementers to identify and understand the specific conformance requirements. Resolution: Closed 2005-05-18. A new draft will be posted with further updates. 52 Proposed Draft UTR #36 Security Considerations 2004.11.08 This draft Unicode Technical Report describes some of the security considerations that should be taken into account by programmers, system analysts, standards-developers, and others when implementing the Unicode Standard and related technologies. The UTC is seeking public feedback on this document. Resolution: Closed 2004-11-23. The proposed draft will be updated with editorial feedback and advanced to "Draft" status. 51 Proposed Update UAX #29 Text Boundaries 2005.01.31 This is a proposed update to a previously approved Unicode Standard Annex. It contains some important changes in categories for some characters and changes in linebreaking rules. The UTC is seeking public feedback on these changes. Note: The text of UAX #29 has been modified slightly to make it clear that level run and directional run refer to the same thing. Re-posted on 2005-01-17. Resolution: Closed 2005-02-14. The proposed update was approved and will be published as part of Unicode 4.1.0. 50 Proposed Update UTS #18 Unicode Regular Expressions 2004.11.08 This is a proposed update to a previously approved Unicode Technical Standard. The update includes some new notation, new notes on Compatibility Properties, and other changes. The UTC is seeking public feedback on these changes. Resolution: Closed 2004-11-23. The proposed update was approved with changes from feedback and will be published. 49 Proposed Update UTS #6 A Standard Compression Scheme for Unicode 2004.11.08 This is a proposed update to a previously approved Unicode Technical Standard. This standard describes a compression scheme (SCSU) mainly intended for use with short to medium length Unicode strings. A number of changes and clarifications have been made in the text, and the UTC is seeking public feedback on these changes. Resolution: Closed 2004-11-23. The proposed update was approved and will be published. 48 Definition of "Directional Run" 2004.11.08 A definition of "directional run" is proposed for inclusion in UAX #9 The Bidirectional Algorithm. The UTC is seeking public feedback on this definition. See the background document for details. Resolution: Closed 2004-11-23. The UTC decided to make the definition of "directional run" be the same as "level run" in UAX #9. An updated draft will be posted later. 47 Changes to default collation of Latin in UCA 2004.11.08 In collation, searching, and matching according to the Unicode Collation algorithm, the 10 characters Æ, Ǽ, Ǣ, Đ, Ð, Ħ, Ł, Ŀ, Ø, Ǿ (and their lowercase forms) currently have primary (base letter) differences from the letters A, D, H, L, and O respectively. There is a proposal before the UTC to change these to have secondary (accent) differences from AE, D, H, L, O, respectively. We would welcome feedback on this issue -- pro or con.
Arguments for the change are in the background document. We expect to add the contrary point of view to that document.Resolution: Closed 2004-11-23. The UTC accepted changes for the ten characters and their lower case counterparts.
46 Proposal for Encoded Representations of Meteg 2004.11.08 In some Biblical Hebrew usage, it is considered necessary to distinguish how the meteg mark positions relative to a vowel point: to the left of the vowel, or to the right; or, in the case of a hataf vowel, between the two components of the hataf vowel. A solution for this has been proposed using control characters, including the zero width joiner and non-joiner characters. This public-review issue is soliciting feedback on this proposed solution. Resolution: Closed 2004-11-23. The proposal was approved and will be documented in Unicode 4.1.
45 Bidi Category of Narrow No-Break Space 2004.11.08 Should the Bidi category of Narrow No-Break Space (NNBSP, U+202F) be changed from "WS" to "CS", in analogy to No-Break Space U+00A0? The reason for the change is that in all scripts but Mongolian it acts like ordinary NBSP, except for its width. In Mongolian it may be recognized in shaping. (Note, there is no separate background document for this issue.) Resolution: Closed 2004-11-23. The proposal was approved and the category changed. This will be documented in Unicode 4.1. 44 Bidi Category of Fullwidth Solidus 2004.11.08 Unicode 4.0.1 changes the Bidi Category U+002F SOLIDUS from "ES" to "CS" but leaves U+FF0F FULLWIDTH SOLIDUS as category "ES". U+FF0F FULLWIDTH SOLIDUS should probably have the same bidi class as its regular sibling. The UTC proposes to make this change for Unicode 4.1. (Note, there is no separate background document for this issue.) Resolution: Closed 2004-11-23. The proposal was approved and the category changed. This will be documented in Unicode 4.1.
43 Proposed Update UAX #24 Script Names 2004.11.08 This is a proposed update to a previously approved Unicode Standard Annex. This annex provides an assignment of script names to all Unicode code points. This information is useful in mechanisms such as regular expressions and other text processing tasks. The proposed update makes several substantial changes to the previously approved annex. Resolution: Closed 2004-11-23. The proposed update was approved and will be published. 42 Proposed Draft UAX #34 Unicode Named Character Sequences 2004.11.08 This proposed annex specifies sequences of characters that may be treated as single units, either in particular types of processing, in reference by standards, in listing of repertoires (such as for fonts or keyboards), or in communicating with users. Resolution: Closed 2004-11-23. The proposed draft will be updated with editorial feedback and advanced to "Draft" status.
41 Encoding of INVISIBLE LETTER 2004.11.08 UTC is seeking feedback regarding a proposal to encode "INVISIBLE LETTER" to serve as an unambiguous base letter for combining marks in isolation. The character properties would be specifically designed to aid in processing. This proposed letter might also be used to correspond to the "INV" letter in ISCII in some conversion scenarios, but its intent isn't exactly the same as that character. See the above-linked document for details. Resolution: Closed 2004-11-23. The proposal was rejected by UTC.
40 Encoding of Latin Capital and Small Letter "At" 2004.11.08 LATIN CAPITAL LETTER AT and LATIN SMALL LETTER AT are used as orthographic characters in the Koalib language of Sudan. They are typically used for Arabic loan words. Although similar in appearance to COMMERCIAL AT, LATIN SMALL LETTER AT should have different character properties. The main concern is the similarity in appearance of LATIN SMALL LETTER AT to COMMERCIAL AT. There are potential implications for Internet protocols that use @. The question for reviewers is: Should the UTC accept LATIN CAPITAL LETTER AT and LATIN SMALL LETTER AT? Resolution: Closed 2004-11-23. The UTC concluded that there is no compelling evidence of usage to date. Furthermore, the UTC will not change the properties of the existing @ sign U+0040 to be a letter.
39 Draft Unicode Technical Standard #31 Identifier and Pattern Syntax 2004.11.08 An updated draft of UTS #31 "Identifier and Pattern Syntax" is available at the above link. This draft has new conformance information as well as a new section on Normalization and Case and other changes. This document has implications for programming languages, regular expressions, and scripting languages. An update of this document incorporating minor changes was posted 2004/10/19. Resolution: Closed 2004-11-23. The draft will be updated with editorial feedback and published. 38 Draft Unicode Technical Report #30 Character Foldings 2004.08.03 An updated draft of UTR #30 "Character Foldings" is available at the above link. This update also provides a new set of draft data files for several types of character foldings. The Unicode Technical Committee especially seeks review of the data files. Resolution: Closed 2004-06-24. The draft will be updated with editorial feedback and published. (Due to various factors, publication did not actually occur. On August 14, 2008, the UTC decided to rescind its approval for publication and put the draft of UTR #30 into withdrawn status. See UTC action 116-C8.)
37 Clarification of the Use of Zero Width Joiner in Indic Scripts 2004.08.03 There are some inconsistencies in the use of ZERO WIDTH JOINER (ZWJ) in a number of Indic scripts which are outlined in the accompanying review document. This proposal intends to rectify these problems, clarifying how the ZERO WIDTH JOINER is to be applied in scripts, and consolidating common mechanisms for equivalent problems that exist in several scripts. The scope for what is proposed covers Devanagari, Bengali, Gurmukhi, Gujarati, Oriya, Tamil, Telugu, Kannada and Malayalam.
The question for reviewers is: Should the UTC adopt a model in which ZWJ precedes Virama, as proposed in section 7 of the review document?Resolution: Closed 2004-08-24. UTC accepted the proposal and will create an Indic conjoining behavior model. 36 Draft Unicode Technical Report #30 Character Foldings 2004.06.08 An updated draft of UTR #30 "Character Foldings" is available at the above link. This update also provides draft data files for four types of character foldings. The Unicode Technical Committee especially seeks review of the data files. Resolution: Closed 2004-06-23. The draft will be updated with editorial feedback and published. 35 Encoding of LATIN SMALL LETTER C WITH STROKE as a phonetic symbol 2004.06.08 At the February 2004 meeting of the Unicode Technical Committee, a proposal was considered to encode the phonetic symbol LATIN SMALL LETTER C WITH STROKE. Some reservation was expressed on the part of some committee members, however, due to potential legacy encoding issues. A decision was made to give tentative approval of this character, but to prepare a public review issue to elicit feedback on the pros and cons of encoding this character. Resolution: Closed 2004-06-23. The UTC decided to encode the this character. For information on the progress of encoding and balloting, please see the Proposed New Characters: Pipeline Table. 34 Draft UTS #35 Locale Data Markup Language, Version 1.2 2004.09.01 Version 1.2 is now under development, incorporating changes decided on by the CLDR technical committee. The latest working draft of version 1.2 is located at working draft CLDR 1.2. Feedback should be submitted via the CLDR bug database, not with the reporting form.Resolution: Closed 2004-11-09. The final 1.2 version of LDML was released.
33 UTF Conversion Code Update2004.08.03 The C language source code example for UTF conversions (ConvertUTF.c) has been updated to version 1.2 and is being released for public review and comment. This update includes fixes for several minor bugs. The code can be found at the above link. Resolution: Closed 2004-08-24. The code will be updated with feedback received and published.
32 Proposed Update UTR #23 Character Property Model 2004.06.08 This is a new draft for the Character Property Model, revising some definitions and extending the discussion of stability as well as override of properties. Resolution: Closed 2004-06-23. The draft will be updated with editorial feedback and published.
31 Cantonese Romanization 2004.08.03 The sources for the Unihan database use multiple competing romanizations of Cantonese, while the Unihan database uses yet another romanization. We feel that there is no good reason for Unicode to contribute to this confusion, so we plan to adopt a single, standard Cantonese romanization for use throughout the Unihan database. Resolution: Closed 2004-08-24. UTC decided to go ahead with the change in the next update of the Unihan database. 30 Bengali Khanda Ta 2004.06.08 The description of khanda ta in section 9.2 of Unicode 4.0 and in one of the current Indic FAQs assumed a particular understanding of expected behaviors rather than stating those expectations explicitly. Due to certain wording and an atypical use of ZERO WIDTH JOINER, some implementers have been misled about the behaviors related to khanda ta that were assumed.
In the course of investigating this issue, input was received suggesting that the atypical use of ZERO WIDTH JOINER was problematic, and that a different encoded representation for khanda ta should be adopted.
Alternate representations for khanda ta are described and evaluated in the review document. It is proposed that the existing representation specified in section 9.2 be retained, but that the description in the Standard be revised to remove any ambiguity and potential for misunderstanding.Resolution: Closed 2004-06-23. The UTC decided to encode the khanda ta as a separate character in a future version of the Unicode Standard. For information on the progress of encoding and balloting, please see the Proposed New Characters: Pipeline Table. 29 Normalization Issue 2004.06.08 There is a problem in the language of the specification of Unicode Standard Annex #15: Unicode Normalization Forms for forms NFC and NFKC. A textual fix is required to make normalization formally self-consistent. The fix will not have an impact on real data found in practice (with the possible exception of test cases for the algorithm itself), because the affected sequences do not constitute well-formed text in any language. Details, cases, and recommendations can be found in the review document. Resolution: Closed 2004-06-23. The UTC decided to implement the recommendation in the review document, and a draft of Unicode Standard Annex #15: Unicode Normalization Forms incorporating the changes will be updated and published. 28 BIDI Boundary_Neutral Property Value 2004.02.04 The BIDI property value BN is currently aligned with the General Category Value Format_Character (Cf), minus, the BIDI specific format characters (LRM, RLM, RLE, LRE, RLO, LRO, PDF). The intent of the BN property is to allow the BIDI algorithm to ignore invisible, irrelevant characters when determining the ordering of the visible characters. The proposal is to align the BN property with Default_Ignorable_Code_Point property (DICP) instead of Cf, minus again the BIDI specific characters. Resolution: Closed 2004-02-12. Change the bidi properties of the following code points for Unicode 4.0.1:
U+00AD SOFT HYPHEN from ON to BN
All noncharacters from L to BN
All unassigned code points with the Default_Ignorable_Code_Point property from L to BN
(U+2064..U+2069, U+FFF0..U+FFF8, U+E0000, U+E0002..U+E001F,
U+E0080..U+E00FF, U+E01F0..U+E0FFF)
Annotation characters U+FFF9..U+FFFB from BN to ON27 Joiner/Nonjoiner in Combining Character Sequences 2004.01.27 Unicode 4.0 describes the structure of Khmer syllables, saying that they may contain an interior ZWJ. There is a problem with this that needs to be resolved in 4.0.1, because some of the characters later in the syllable can be combining characters. This paper describes a proposal with which to fix this problem. As a part of the proposal, a choice has to be made among two alternatives. Resolution: Closed 2004-02-12. The UTC decided to allow ZWJ and ZWNJ in combining character sequences, but not to change their general category. The interpretation of joiner/nonjoiner between two combining marks is not yet defined. Minimal changes to definitions D14 and D17 of the standard will be made for Unicode 4.0.1. UTC also decided to issue a proposed update of UTS #18 Unicode Regular Expression Guidelines that makes appropriate changes.
26 Update properties for Ethiopic and Tamil non-decimal digits 2004.01.27 Decimal numbers are those using in decimal-radix number systems. In particular, the sequence of the ONE character followed by the TWO character is interpreted as having the value of twelve. We have gotten feedback that this is the not the case for Ethiopic or Tamil. Details of the affected codepoints are in the above-linked document. Resolution: Closed 2004-02-12. UTC decided to encode Tamil Digit Zero as "Nd" and the other digits will remain "Nd" reflecting current practice. (This character's status will be tracked in the "Pipeline" list of future additions to the standard.) The Ethiopic digits U+1369 - U+1371 will be changed in Unicode 4.0.1 from general category "Nd" to "No" and the numeric type will be changed to synchronize.
25 Proposed Update UTR #17 Character Encoding Model 2004.08.03 This is an updated draft of the Character Encoding Model, reflecting the feedback received until 2004-03-25 and clarifying the description of Character Encoding Schemes. Resolution: Closed 2004-08-24. The proposed update progressed to final status and will be posted. 24 Proposed Update UAX #9 Bidirectional Algorithm 2003.10.27 A proposed update of Unicode Standard Annex #9 Unicode Bidirectional Algorithm is available at the link above. Resolution: Closed. This review item has now been included in the Unicode 4.0.1 beta. 23 Terminal Punctuation Characters 2003.10.27 In Unicode 4.0.1, the new property Sentence_Terminal will be added. This consists of characters that terminate a sentence; in particular, a sentence (unless quoted) should not span one of these characters based on UAX #29 (Text Boundaries). The above-linked document provides a comparison of this property with the existing Terminal_Punctuation and Other_Punctuation, so that people can provide feedback as to whether any characters should be moved from one category into another. Resolution: Closed. "Sentence_Terminal" will be changed to "STerm" in the UCD, Proplist.txt and PropertyAliases.txt. The change will be implemented for Unicode version 4.0.1. 22 Collation Mechanism for Syllabic Scripts 2003.10.27 In UTS #10: Unicode Collation Algorithm, there is discussion of a mechanism for handling syllabic scripts, notably Korean Hangul. The alternative mechanism discussed in the above-linked document is proposed to allow the UCA and tailorings to deal with syllabic collation. The goal is for this mechanism to be very lightweight, and thus easy for implementations to implement without impacting the performance of other characters. Resolution: Closed. The collation mechanism for syllabic scripts will be documented in an update to UTS #10. 21 Changing U+200B Zero Width Space from Zs to Cf 2003.10.27 There have been persistent problems with usage of the U+200B Zero Width Space (ZWSP). The function of this character is to allow a line break at positions where it normally would not be allowed, and is thus functionally a format character with a general category of Cf. This behavior is well documented in the Unicode Standard, and the character not considered a Whitespace character in the Unicode Character Database. However, for historical reasons the general category is still Zs (Space Separator), which causes the character to be misused. ZWSP is also the only Zs character that is not Whitespace. The general category can cause misinterpretation of rule D13 Base character as allowing ZWSP as a base for combining marks.
The proposal is to change the general category of U+200B from Zs to Cf.
Resolution: Closed. The general category of U+200B will be changed from Zs to Cf in Unicode version 4.0.1.
20 Draft UTR #31 Identifier and Pattern Syntax 2004.06.08 A draft of Unicode Technical Report #31 Identifier and Pattern Syntax is available at the link above. Note: this new draft was posted January 26, 2004. Resolution: Closed 2004-06-23. The draft will be updated with editorial feedback and published as a Unicode Technical Report. 19 Proposed Draft UTR #30 Character Foldings 2003.10.27 A proposed draft of Unicode Technical Report #30 Character Foldings is available at the link above. Please provide feedback to the authors by the deadline for comments. Resolution: Closed. The proposed draft progressed to the status of Draft Unicode Technical Report. 18 Draft UTR #23 The Unicode Character Property Model 2003.10.27 A proposed draft of Unicode Technical Report #23 The Unicode Character Property Model is available at the link above. Changes in the document are marked with yellow formatting. This will be finalized after the next UTC meeting. Resolution: Closed. 17 UTS #18 Unicode Regular Expressions 2003.10.27 It is proposed to change the status of UTR #18 from a Unicode Technical Report (UTR) to a Unicode Technical Standard (UTS). The draft of the proposed UTS is is available at the link above. Changes in the document are marked with yellow formatting. This will be finalized after the next UTC meeting. Resolution: Closed. The change was made to a UTS. 16 Update to UAX #29 Text Boundaries 2003.10.27 A proposed update for Unicode Standard Annex #29 Text Boundaries is available at the link above. Changes in the document are marked with yellow formatting. This will be finalized and included as part of the Unicode 4.0.1 release. Resolution: Closed. The UTC decided include some minor editing to take into account public feedback. 15 Changing General Category of Braille Patterns to "Letter Other" 2003.10.27 The UTC has received requests to change the general category of the Braille characters to be "Letter other" (Lo) rather than "Symbol other" (So), and is seeking comments and information on the Braille processing model and existing implementations to help with this decision. The Braille pattern symbols are encoded from U+2800 through U+28FF, and are discussed in the Unicode Standard 4.0, chapter 14 section 9. The presumption until now in Unicode has been that the Braille characters are essentially "final form" characters; that the source text would be in other scripts, and these would be used for presentation of that source text. Under that model, the characters would be better characterized as symbols; in particular, they would not be suitable for program identifiers.
The effect of the proposed change would be for implementations to treat the Braille pattern symbols as letters rather than symbols for various textual processes. There is a particular interaction with the proposed XML 1.1 categorizations for element names that the committee is concerned with, and is especially interested in feedback regarding related issues.
Resolution: Closed. The UTC decided not to change the general category of the Braille characters. However, the Bidi category of the Braille characters was changed to be strong left-to-right (L), as a result of this review. 14 Unicode Collation Algorithm 4.0.0 Beta 2003.08.26 The primary goal of this release of the Unicode Collation Algorithm is to synchronize the repertoire of strings for collation (sorting) with the repertoire of Unicode 4.0. For future versions of the Unicode Standard that add characters, there will also be versions of the UCA tables with synchronized repertoire. A small number of additional changes have been made for consistency in treatment of new and old characters; however, other changes await working with SC22/WG2 so that future versions of ISO 14651 and UCA can be synchronized. The relevant data file is this version of allkeys.txt. Resolution: Closed.
13 Unicode 4.0.1 Beta 2004.01.27 The beta period for Unicode 4.0.1 is open. Detailed information is available on the 4.0.1 beta page. This release also includes three proposed updates to Unicode Standard Annexes (UAXes): Proposed Update UAX #9 Bidirectional Algorithm
Proposed Update UAX #11 East Asian Width
Proposed Update UAX #29 Text BoundariesThe above list of proposed updates, the Unicode 4.0.1 data files and the 4.0.1 beta page may be updated during the beta period. The purpose of the update to UAX #11 is to clarify the concept of Ambiguous width.
In addition, feedback is welcome on the UAXes that do not currently have proposed updates posted.
Resolution: Closed 2004-02-12. 12 Terminal Punctuation Characters 2003.08.18 In Unicode 4.0.1, the new property Sentence_Terminal is being added. This property is to be used in the default sentence boundaries in UAX #29 (Text Boundaries), instead of a list in the body of that document (under the heading "Term"). The Unicode Technical Committee is seeking feedback on the common usage of certain punctuation characters; especially feedback from those familiar with non-Latin writing systems, including Arabic, Armenian, Syriac, Devanagari, Myanmar, and so on. Resolution: Closed. In addition to the characters discussed in the above document, the following characters are also included in Sentence_Terminal:
U+05C3 HEBREW PUNCTUATION SOF PASUQ
U+0F08 TIBETAN MARK SBRUL SHAD
U+0F0D TIBETAN MARK SHAD
U+0F0E TIBETAN MARK NYIS SHAD
U+0F0F TIBETAN MARK TSHEG SHAD
U+0F10 TIBETAN MARK NYIS TSHEG SHAD
U+0F11 TIBETAN MARK RIN CHEN SPUNGS SHAD
U+0F12 TIBETAN MARK RGYA GRAM SHAD
11 Soft-Dotted Property 2003.08.18 The Unicode Standard has the principle that if an accent is applied to an i or j, the base character loses its dot. Such characters are called "soft-dotted". The UTC proposes to extend this property to a number of characters that do not currently have the property. The accompanying document lists the characters. Resolution: Closed. The UTC decided to resolve the issue by adding the list of proposed additional soft-dotted characters (in the above document), excluding "ij" small ligature U+0133. 10 Interlinear Annotation Characters 2003.08.15 Change the General Category for the Interlinear Annotation Characters from Cf to Po (Punctuation Other), and thereby change the status to not be Default_Ignorable_Code_Points. In addition to the document linked above, some explanation from the standard about Default Ignorable codepoints is available. Resolution: Closed. The UTC decided to resolve this issue not by changing the general category, but by making them non-default-ignorable, and using an exclusion list. This also calls for adding a documentary note that not all characters with dotted-box glyphs have the general category Cf.
9 Bengali Reph and Ya-Phalaa 2003.10.27 Resolve an ambiguity with regard to handling of reph and ya-phalaa in Bengali implementation by using ZWNJ between Ra and Halant (Virama). Resolution: Closed. After consideration of public review comments, the UTC decided to adopt the solution suggested in the attached resolution document. 8 Math digits 2003.06.01 It is proposed to give the mathematical digits (U+1D7C9 .. U+1D7FF) the general category of "No" rather than "Nd", and to delete the value of field 6 from those characters in the UCD (UnicodeData.txt file; note: the first field is numbered 0).
This is in recognition of the fact that these digits are most commonly not used as part of decimal numbers, but are used as variables or other mathematical symbols.
This proposal is intended to change their Numeric_Type from nt=de (Decimal) to nt=di (Digit), thereby aligning them with the superscript and subscript digits which were just changed, as special cases, and distinguishing them from the various sets of decimal digits per se (nt=de and gc=Nd). As a result of the proposed change, category Nd would be reserved for decimal digits used in ordinary decimal numbers.Resolution: Closed. The UTC sees no reason to change the numeric values assigned to the Math Digits 1D7C9..1D7FF. 7 Tailored normalization forms 2003.06.01 The UTC is considering allowing limited tailoring of normalization forms. This would involve excluding certain specified sets of characters from decomposition, notably the CJK compatibility characters (which are actually canonical--not compatibility--decomposables).
Possible advantages are that it allows the graphic variations to be preserved; possible disadvantages are interoperability problems with different variants of normalization forms. Two documents discussing this issue are posted HERE and HERE.Resolution: Closed. In view of the many problems which turned up when attempting to design a tailoring mechanism for normalization, the UTC has decided not to add a mechanism for tailored normalizations. 6 Unicode 4.0 Beta data 2003.03.21 The beta reviewof the Unicode 4.0 data files is open for public comment. We strongly encourage implementers to download these files and test them with their programs, well before the end of the beta period.The comment period ends March 21, 2003. However, comments that are not editorial will need to be reviewed by the Unicode Technical Committee (UTC). Comments received by March 3, 2003 will be in time to be reviewed at the next meeting of the UTC.Resolution: Closed. 5 Object Replacement Char 2003.06.01 Whether to treat U+FFFC Object Replacement Character and the Interlinear Annotation Characters as "default ignorable" or to have a default visible representation. Resolution: Closed. The UTC determined that the Object Replacement Character and the interlinear annotation characters should not be given the Default_Ignorable property. 4 Sharp S collation weight 2003.02.14 The default weighting in the UCA for the following character should have a tertiary difference from "ss" instead of a secondary difference.
U+00DF (ß) LATIN SMALL LETTER SHARP SResolution: Accepted. This change will be incorporated into a subsequent revision of UTS #10, the collation standard. However, DIN takes a different approach so we are attempting to contact them to get more information. 3 Connecting Characters 2002.11.05 Add language indicating that glyphs for the following should normally be designed to connect.
U+2013 (–) EN DASH
U+2014 (—) EM DASH
[Related Internal Document L2/02-277]Resolution: Rejected. UTC now considers it inadvisable add such language, given widespread implementation. 2 Khmer character deprecation 2002.11.05 Deprecate the following characters
U+17A3 () KHMER INDEPENDENT VOWEL QAQ
U+17D3 () KHMER SIGN BATHAMASAT
Mark the following as being discouraged:
U+17B4 () {KHMER VOWEL INHERENT AQ
U+17B5 () {KHMER VOWEL INHERENT AA
U+17A4 () {KHMER INDEPENDENT VOWEL QAA
U+17D8 () {KHMER SIGN BEYYAL
Resolution: Accepted. This change is to be incorporated into Unicode 4.0. 1 Lang tag deprecation 2003.02.14 Deprecate the Plane 14 Language Tags Resolution: Closed. There is no change in status; additional clarification has been added to Unicode 4.0 text.